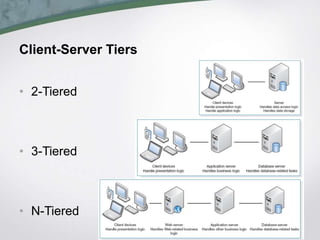
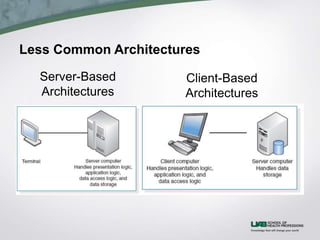
The document discusses health information system architecture design. It covers architectural components including software, data storage, and hardware. It describes client-server architectures which balance processing between clients and servers. Advances like virtualization and cloud computing are mentioned. The document outlines requirements for architecture design like operations, performance, security, and cultural factors. It discusses specifying suitable hardware and software based on functions, performance, costs and other considerations.