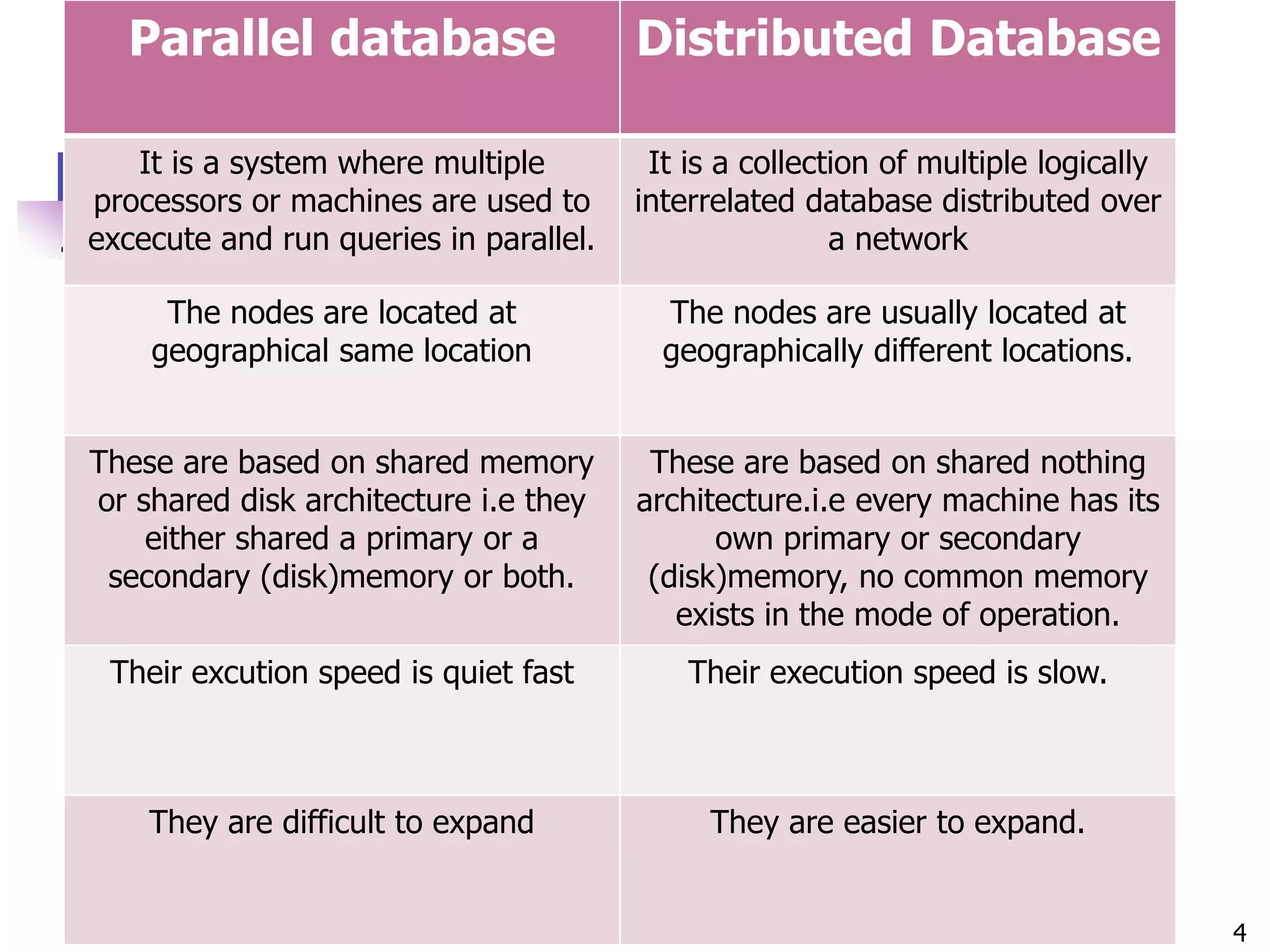
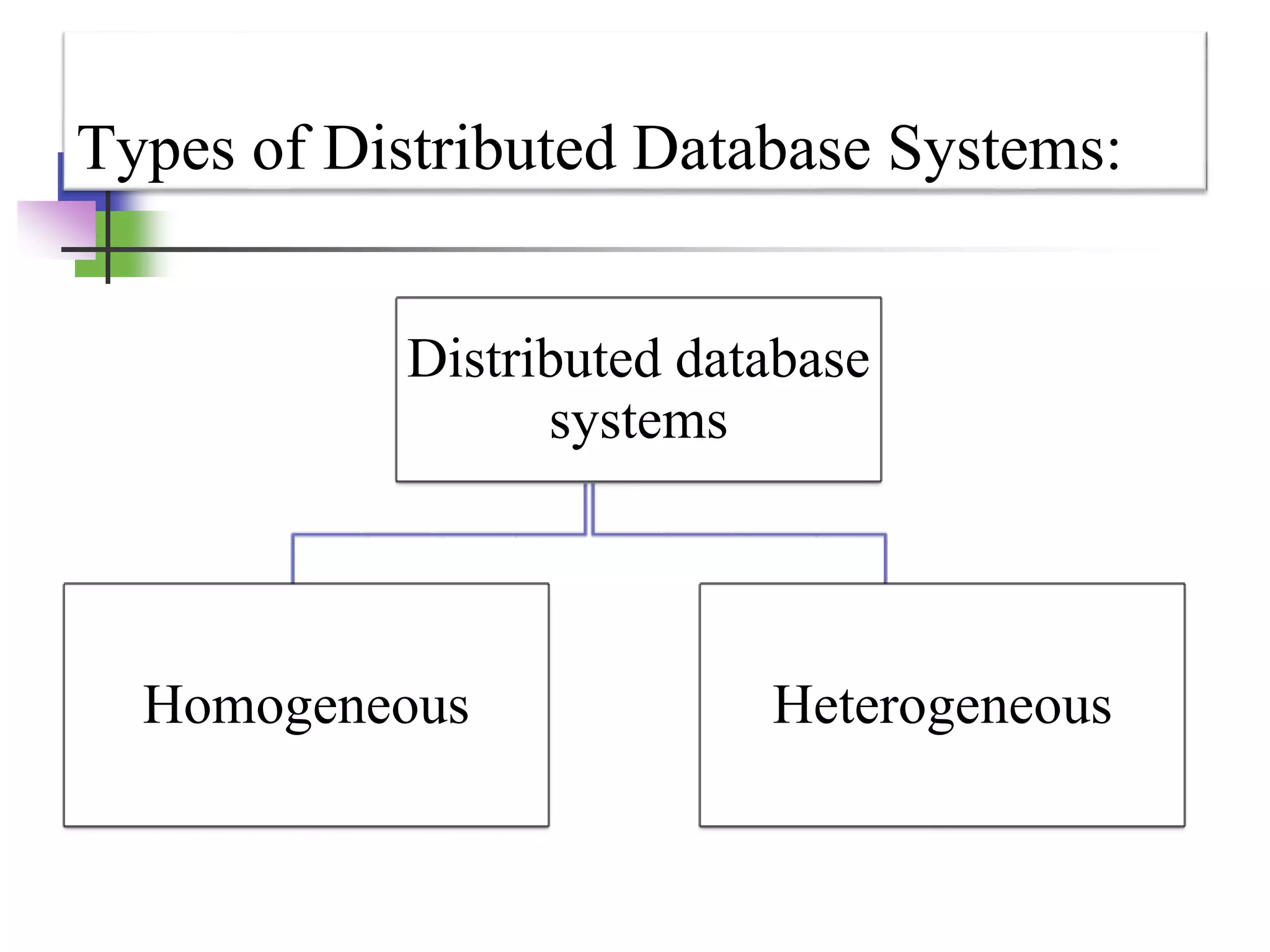
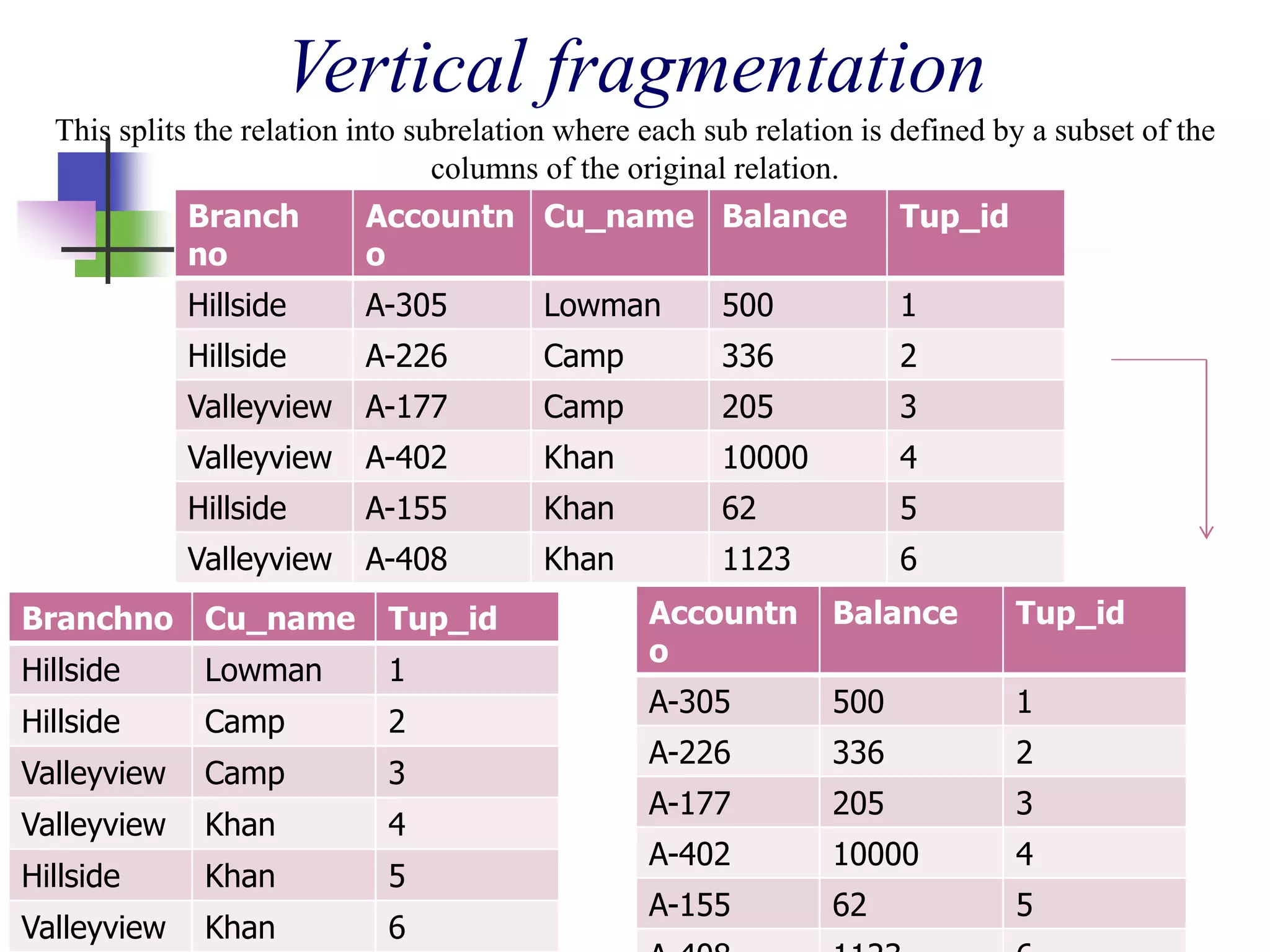
This document provides an introduction to distributed databases. It defines a distributed database as a collection of logically related databases distributed over a computer network. It describes distributed computing and how distributed databases partition data across multiple computers. The document outlines different types of distributed database systems including homogeneous and heterogeneous. It also discusses distributed data storage techniques like replication, fragmentation, and allocation. Finally, it lists several advantages and objectives of distributed databases as well as some disadvantages.