Downloaded 60 times



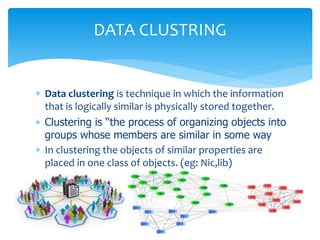
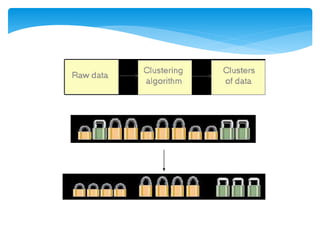



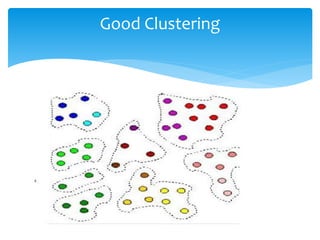




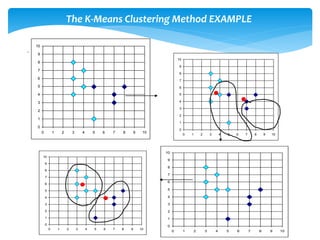

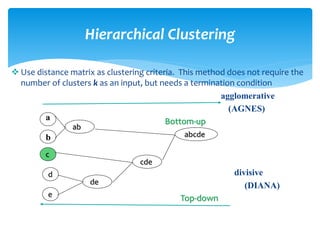






Data clustering is the process of organizing similar objects into groups and is used in various fields such as data mining, pattern recognition, and medical diagnostics. Various clustering methods exist, including partitioning, hierarchical, density-based, and model-based approaches, each with their own algorithms like k-means and agglomerative clustering. The quality of clustering depends on the similarity measures and the ability to identify hidden patterns, making effective algorithms essential for handling large and complex datasets.




























![Clustering[306] [Read-Only].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/clustering306read-only-230112103535-3fb144db-thumbnail.jpg?width=640&height=640&fit=bounds)
















































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)









