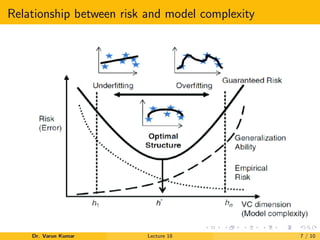
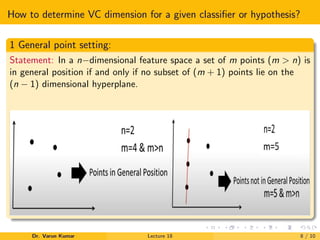
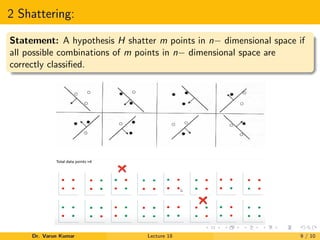
The document discusses VC dimension in machine learning. It introduces the concept of VC dimension as a measure of the capacity or complexity of a set of functions used in a statistical binary classification algorithm. VC dimension is defined as the largest number of points that can be shattered, or classified correctly, by the algorithm. The document notes that test error is related to both training error and model complexity, which can be measured by VC dimension. A low VC dimension or large training set size can help reduce the gap between training and test error.




![Continued–
⇒ Let us our training data are iid from some distribution fX (x).
⇒ Types of risk
(i) Risk R(θ)→ Long term observation→ Test observation
R(θ) = Test error = E[δ(c 6= ĉ(x; θ))]
(ii) Empirical risk Remp
(θ)→ Finite sample observation→ Training
observation
Remp
(θ) = Training error =
1
m
X
i
[δ(c(i)
6= ĉ(i)
(x; θ))]
Dr. Varun Kumar Lecture 18 5 / 10](https://image.slidesharecdn.com/vcdimension-210414041811/85/Vc-dimension-in-Machine-Learning-5-320.jpg)