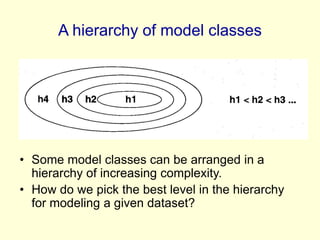
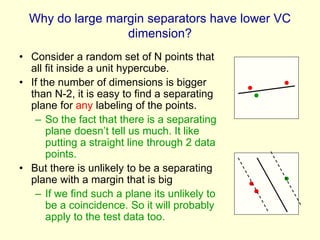
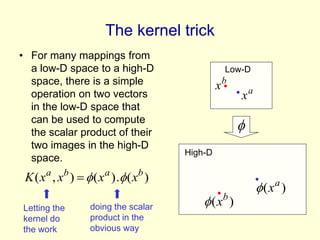
The lecture discusses support vector machines (SVMs) and efficient strategies for generalizing models in large data sets by utilizing feature extraction and the kernel trick. It highlights the importance of structural risk minimization, the Vapnik-Chervonenkis dimension in estimating model complexity, and the concept of maximizing the margin between classes to improve generalization. Additionally, the lecture emphasizes the role of support vectors in SVMs, the computational efficiency of the kernel trick for high-dimensional data, and the performance advantages of SVMs in practical applications.