||y( ) −|
∑
i=1
n
xi p
y
i
|
2
= || − |
∑
i=1
n
W
T
xi p
y
i
|
2
= ( W − )( − )
∑
i=1
n
x
T
i
p
T
y
i
W
T
xi p
y
i
= ( W − 2 W + || | )
∑
i=1
T
x
T
i
W
T
xi x
T
i
p
y
i
p
y
i
|
2
∂E(W)
∂W
= 2 ( W − )
∑
i=1
n
xi x
T
i
xi p
y
i
= 2( XW − P)X
T
X
T
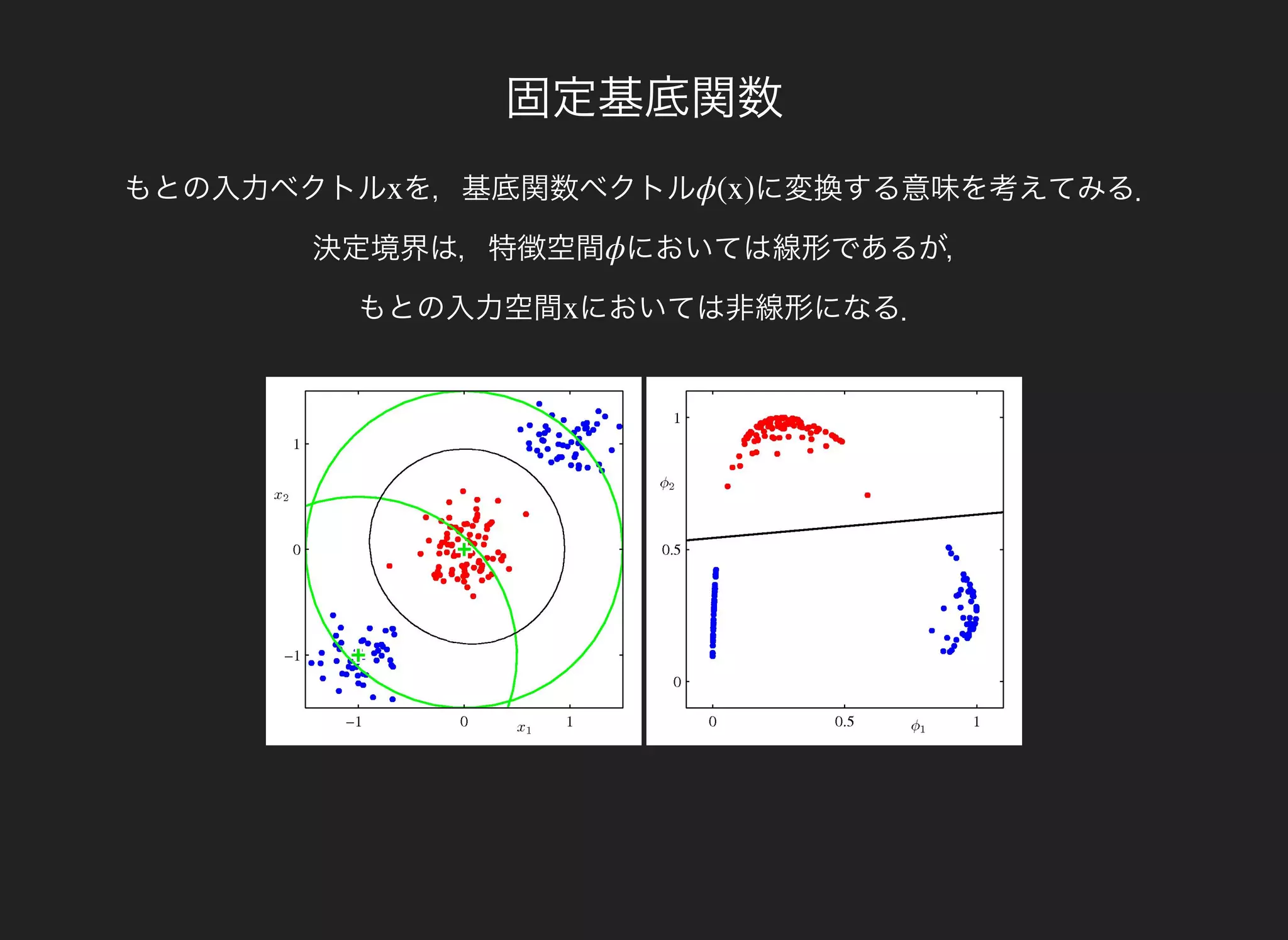
学習データ に対して,D = ( , ), ( , ), …, ( , )x1 y1 x2 y2 xn yn
,y(x) = ( (x), (x), …, (x))yc1
yc2
ycK
とすると,W = ( , , …, )wc1
wc2
wcK
これを と置いて行列E(W) で偏微分するとW
※ と置いた.X = ( , , …, P = ( , , …, )x1 x2 xn )
T
p
y
1
p
y
2
p
y
n
25.
行列の微分
X b =(a + b )X
∂
∂X
a
T
X
T
b
T
a
T
Xb = a
∂
∂X
a
T
b
T
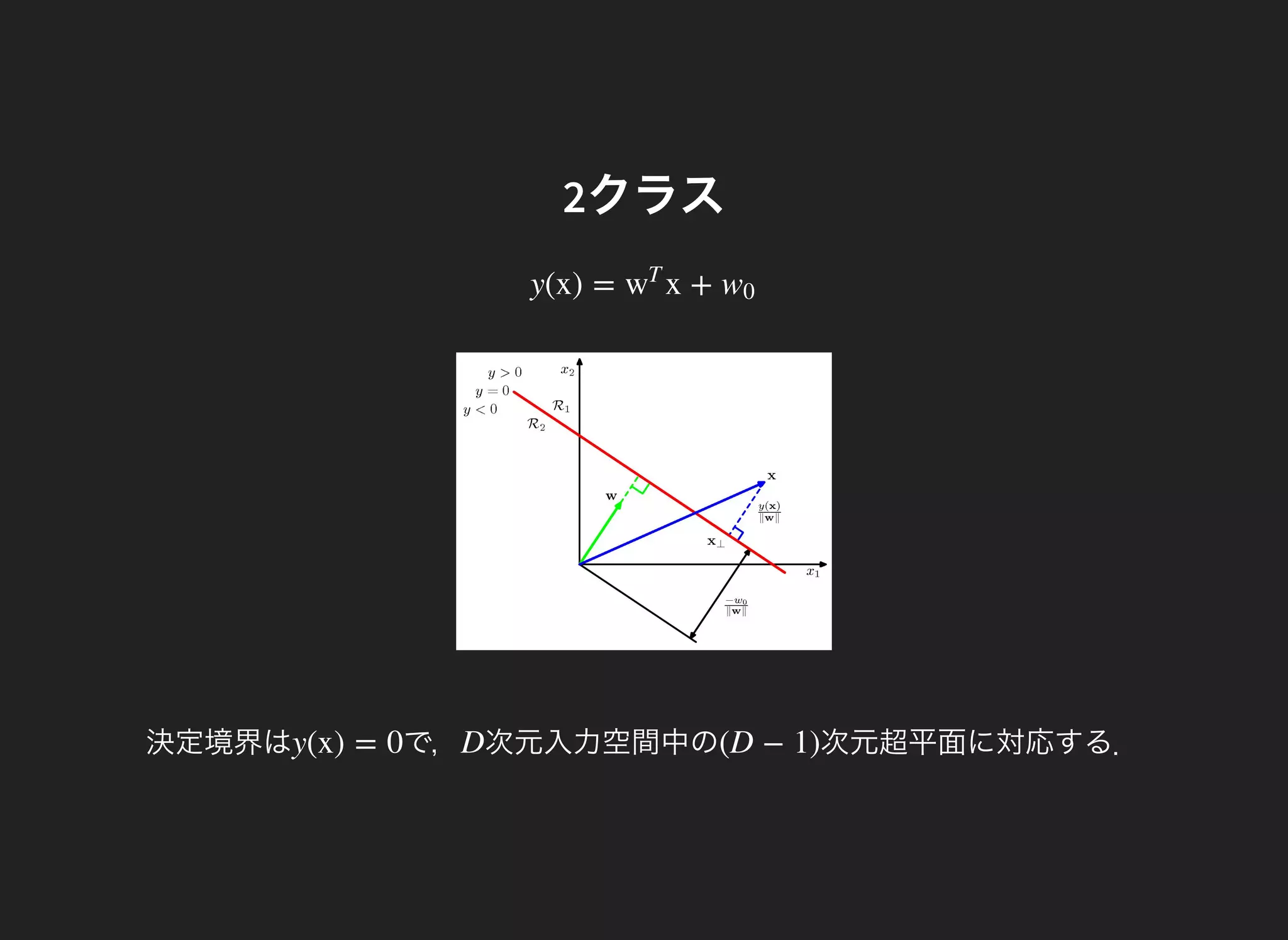
J(w) =
ww
T
SB
ww
T
SW
よって,
= (2(w)( w)( w) − 2( w)( w))/( w = 0
∂J(w)
∂w
SB w
T
SW w
T
SW w
T
SB SW w
T
Sw )
2
ここで,
( w) w = ( w) ww
T
SB SW w
T
SW SB
なので
w = ( − )(( − w) ∝ ( − )SB m2 m1 m2 m1 )
T
m2 m1
これをフィッシャーの線形判別という.
w ∝ w ∝ ( − )S
−1
W
SB S
−1
W
m2 m1
lnσ( ϕ)
d
dw
w
T
= σ(ϕ)
1
σ( ϕ)w
T
d
dw
w
T
= σ( ϕ)
{1 − σ( ϕ)
} ϕ
1
σ( ϕ)w
T
w
T
w
T
d
dw
w
T
=
{1 − σ( ϕ)
}ϕw
T
準備
同様に,
となる
ln
{1 − σ( ϕ)
} = −σ( ϕ)ϕ =
{0 − σ( ϕ)
}ϕd
dw
w
T
w
T
w
T
64.
対数尤度を 倍したものを誤差関数とし,以下のように表す,(−1)
これを
E(w) =− [
lnσ( ) + (1 − )ln
{1 − σ( )
}]
∑i
ti w
T
ϕi ti w
T
ϕi
で微分すると,w
と表せるが,これはさらに,
E(w) = − [ {1 − σ( )
} + (1 − )
{0 − σ( )
} ]
d
dw
∑i
ti w
T
ϕi ϕi ti w
T
ϕi ϕi
とかける
E(w) = − { − σ( )
}
d
dw
∑i
ti w
T
ϕi ϕi
65.
t
y
X
= ( ,, …,t1 t2 tn )
T
= (σ( ), σ( ), …, σ( ph )w
T
ϕ1 w
T
ϕ2 w
T
in )
T
= ( , , …,ϕ1 ϕ2 ϕn )
T
さらに,
と置けば,誤差関数の勾配は以下のように表せる.
E(w) = − (t − y) = (y − t)
d
dw
X
T
X
T
66.
ところで,
を再び
E(w) = −{ − σ( )
}
d
dw
∑i
ti w
T
ϕi ϕi
で微分すると以下のヘッセ行列を得る.w
これを整理すると,以下のように表せる.
H = σ( )
{1 − σ( )
}∑i
w
T
ϕi w
T
ϕi ϕi ϕT
i
H = RXX
T
R =
⎛
⎝
⎜
⎜
⎜
σ( )(1 − σ( ))w
T
ϕ1 w
T
ϕ1
⋮
0
⋯
⋱
⋯
0
⋮
σ( )(1 − σ( ))w
T
ϕn w
T
ϕn
⎞
⎠
⎟
⎟
⎟
ニュートン・ラフソン法
= − ∇E()w
(τ+1)
w
(τ)
H
−1
w
(τ)
はH
−1
に依存しているため,w が新たに求められるたびにw
(正確にはH
−1
)を再計算する必要がある.
これが理由で,このアルゴリズムは反復最重み付け最小二乗法
またはIRLS(iterative reweighted least squares method)として知られている.
R




















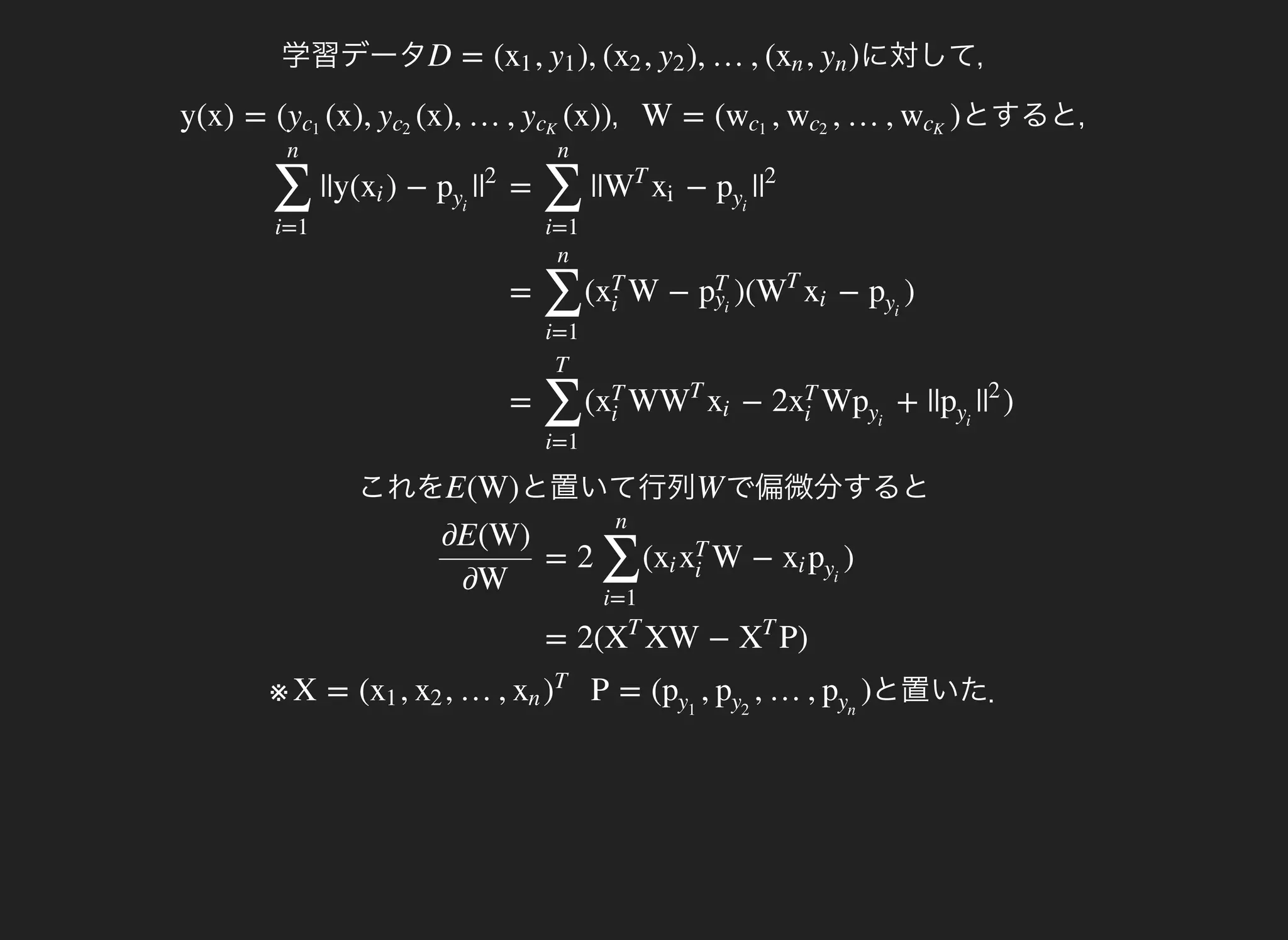

































![よって,学習データ に対する対数尤度はD = {( , ), ( , ), …, ( , )}ϕ1 t1 ϕ2 t2 ϕn tn
より,
L(w|D) = σ(
{1 − σ( )∏i
w
T
ϕi )
ti
w
T
ϕi }
1−ti
とかける.
lnL(w|D) =
[
lnσ( ) + (1 − )ln
{1 − σ( )
}]
∑i
ti w
T
ϕi ti w
T
ϕi](https://image.slidesharecdn.com/progress3-160910082041/75/slide-61-2048.jpg)


![対数尤度を 倍したものを誤差関数とし,以下のように表す,(−1)
これを
E(w) = − [
lnσ( ) + (1 − )ln
{1 − σ( )
}]
∑i
ti w
T
ϕi ti w
T
ϕi
で微分すると,w
と表せるが,これはさらに,
E(w) = − [ {1 − σ( )
} + (1 − )
{0 − σ( )
} ]
d
dw
∑i
ti w
T
ϕi ϕi ti w
T
ϕi ϕi
とかける
E(w) = − { − σ( )
}
d
dw
∑i
ti w
T
ϕi ϕi](https://image.slidesharecdn.com/progress3-160910082041/75/slide-64-2048.jpg)