Download as PDF, PPTX






![Case Study:
Application Outage
[SPARK-8425]](https://image.slidesharecdn.com/5cjosesoltren-170215223233/75/Fault-Tolerance-in-Spark-Lessons-Learned-from-Production-Spark-Summit-East-talk-by-Jose-Soltren-9-2048.jpg)






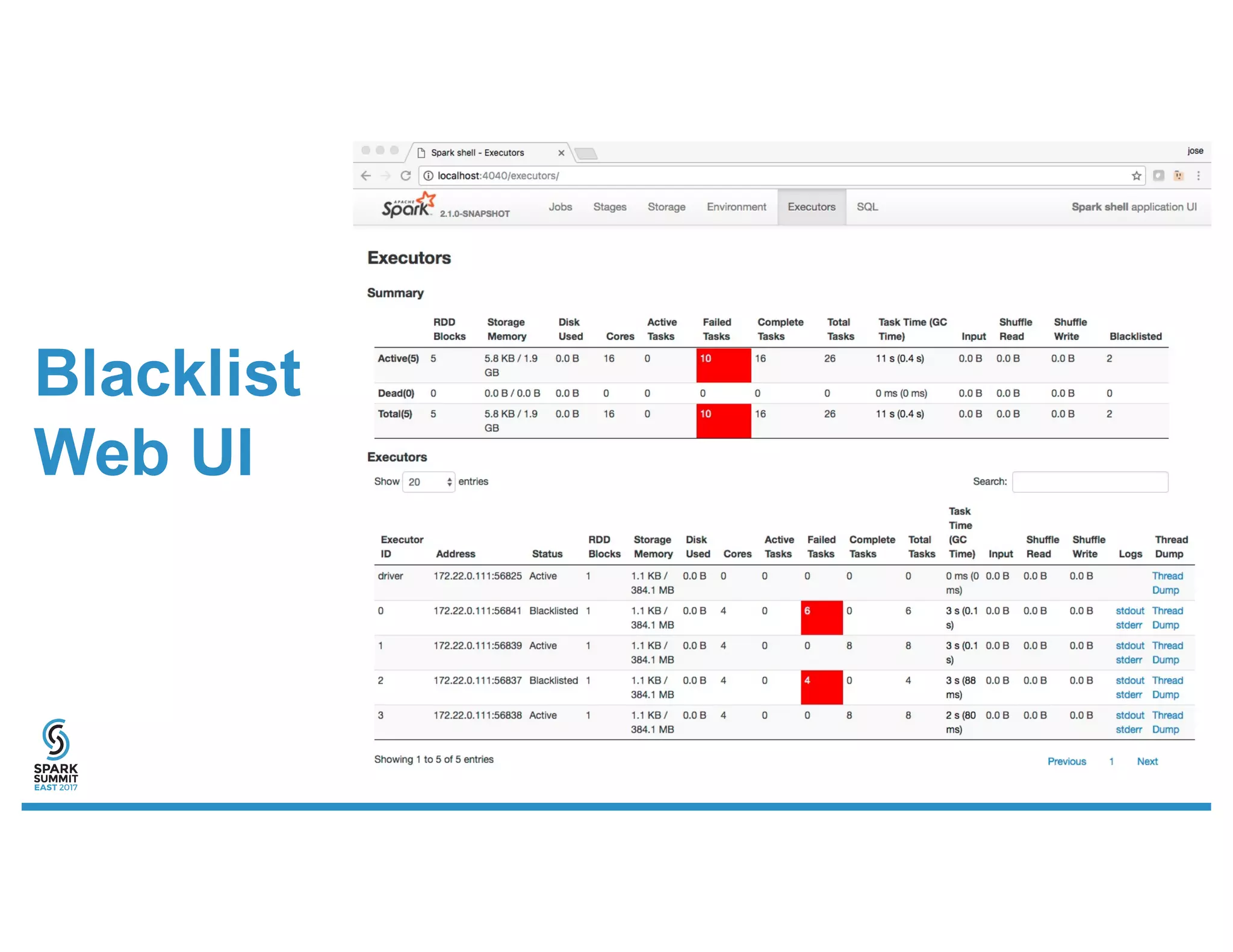
![org.apache.spark.scheduler.
BlacklistTracker
/**
* BlacklistTracker is designed to track problematic executors and nodes. It supports blacklisting
* executors and nodes across an entire application (with a periodic expiry). TaskSetManagers add
* additional blacklisting of executors and nodes for individual tasks and stages which works in
* concert with the blacklisting here.
*
* The tracker needs to deal with a variety of workloads, eg.:
*
* * bad user code -- this may lead to many task failures, but that should not count against
* individual executors
* * many small stages -- this may prevent a bad executor for having many failures within one
* stage, but still many failures over the entire application
* * "flaky" executors -- they don't fail every task, but are still faulty enough to merit
* blacklisting
* * See the design doc on SPARK-8425 for a more in-depth discussion.
*
* THREADING: As with most helpers of TaskSchedulerImpl, this is not thread-safe. Though it is
* called by multiple threads, callers must already have a lock on the TaskSchedulerImpl. The
* one exception is [[nodeBlacklist()]], which can be called without holding a lock.
*/](https://image.slidesharecdn.com/5cjosesoltren-170215223233/75/Fault-Tolerance-in-Spark-Lessons-Learned-from-Production-Spark-Summit-East-talk-by-Jose-Soltren-16-2048.jpg)

![Case Study:
Shuffle Fetch Failures
[SPARK-4105]](https://image.slidesharecdn.com/5cjosesoltren-170215223233/75/Fault-Tolerance-in-Spark-Lessons-Learned-from-Production-Spark-Summit-East-talk-by-Jose-Soltren-19-2048.jpg)







The document discusses fault tolerance in Apache Spark, emphasizing its importance for Cloudera's large-scale applications and identifying a case study where a disk failure caused an application outage due to Spark's failure to handle the bad resource properly. It outlines short-term workarounds and long-term improvements in Spark's scheduler, highlighting new features introduced in version 2.2 to enhance fault tolerance. Key recommendations for developers include starting small, monitoring logs, and being cautious with large deployments to ensure reliability.
Overview of fault tolerance in Spark by José Soltren from Cloudera.
José Soltren's experience as a Software Engineer at Cloudera and expertise in Apache Spark.
Cloudera's reliance on fault tolerance for large-scale applications, emphasizing the critical financial impact of outages.
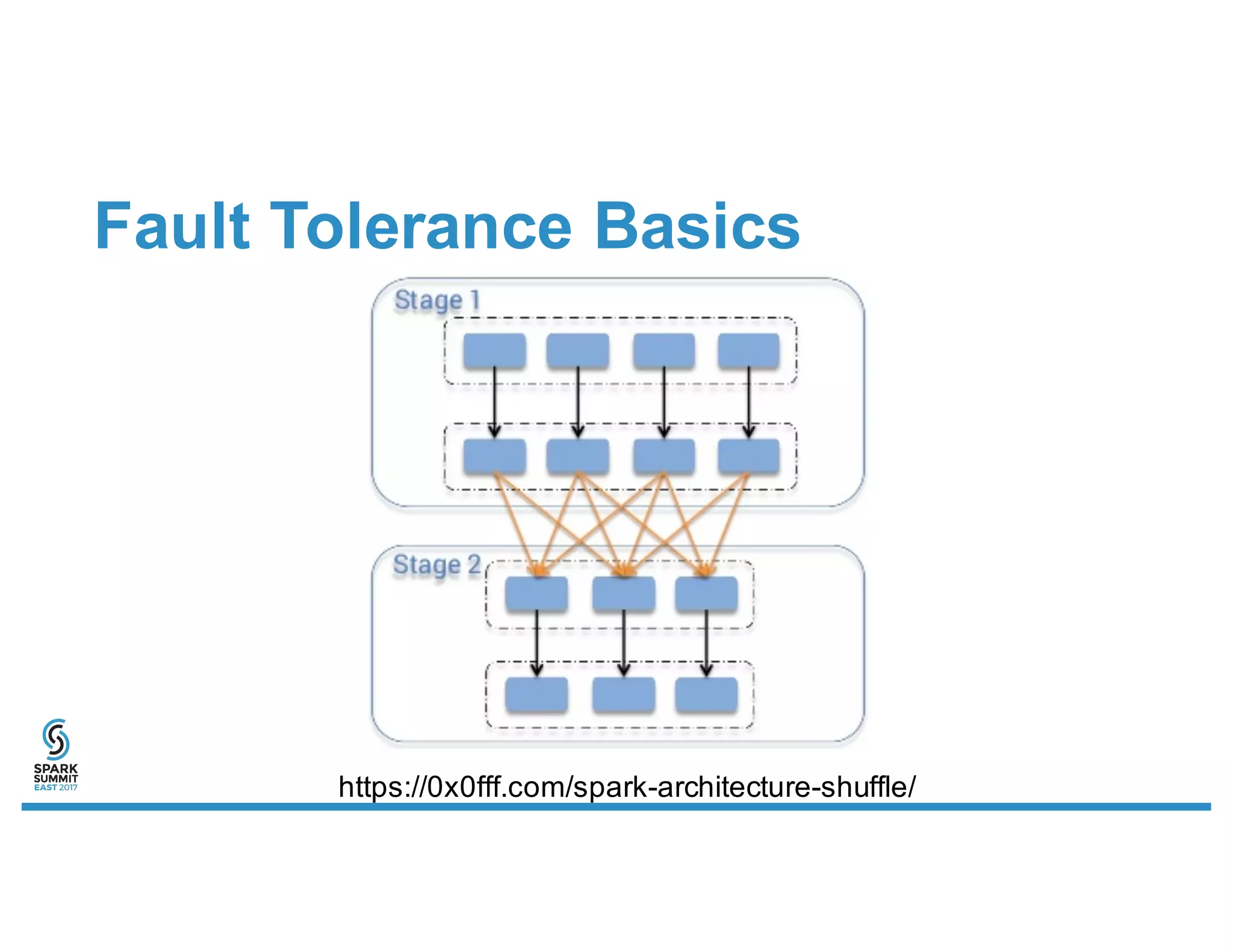
Foundation principles of fault tolerance in Spark, including RDDs, lineage, HDFS, and scheduling.
Discussion of a real-world case study on application outages in production, focusing on scheduling and fault management.
Short-term and long-term strategies for improving Spark's fault tolerance, including changes to task scheduling.
Details about Scheduler improvements in Spark 2.2 and configurations related to blacklisting.
Insights from a case study on shuffle fetch failures, emphasizing non-deterministic errors and fixes in the Spark 2.2 update.
Key takeaways about fault tolerance, scheduler responsibilities, and persistence of distributed systems problems.
Guidelines for application developers to improve performance and manage expectations for Spark applications.
Gratitude expressed by José Soltren with contact information for further inquiries.




































































![[DSC Europe 25] Boris Perkovic - Lost in performance.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/uq5hrp7vsuahqkxzifux-1-251204082258-fd2ee09d-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Dusan Jovicic - AI Story: From on-prem to cloud and back agai...](https://cdn.slidesharecdn.com/ss_thumbnails/8kp49m6uq22ifnbwhfnk-2-251205085715-964d11a6-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DSC Europe 25] Jim Sterne - Adopting Generative AI Capabilities Into the Ent...](https://cdn.slidesharecdn.com/ss_thumbnails/sxhpofuorcagxsaulkmt-3-251204082258-7e66bc48-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Vid Stimac - Policy Parsimony: Between Oversimplifying and Ov...](https://cdn.slidesharecdn.com/ss_thumbnails/eqlepagzqp2rhg3gbluh-dsc-stimac-251120-251205090438-059e7f54-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Nikola Rajovic - Hardware Technologies Under the Hood: RISC-V...](https://cdn.slidesharecdn.com/ss_thumbnails/o2gptrmtoyqndgoshwgq-dsc2025-tenstorrent-rajovic-251205090438-814685f5-thumbnail.jpg?width=640&height=640&fit=bounds)