Download as PDF, PPTX




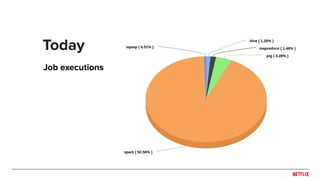
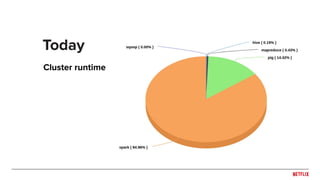
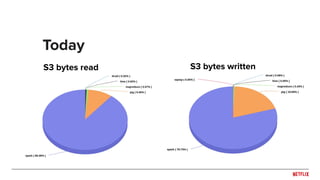





























The document discusses Netflix's migration to Apache Spark, highlighting the transition from Pig and Hive for ETL processes to a predominantly Spark-based architecture. It covers the benefits of using Spark, including improved efficiency and ease of use, as well as the challenges faced during version updates and the implementation of various optimizations. Key technical details about memory management, job execution, stability issues, and configuration best practices are also outlined.




















































































