The document discusses strategies for tuning Apache Spark jobs to optimize performance and resource utilization, focusing on settings such as executor memory, core allocation, and dynamic allocation. It provides practical guidance on collecting historical data, addressing common performance issues, and implementing tuning techniques to enhance efficiency while reducing costs. The presentation emphasizes the importance of understanding the execution environment and adjusting configurations based on specific application needs and historical performance metrics.







![I can haz application :p
val conf = new SparkConf()
.setMaster("local")
.setAppName("my_awesome_app")
val sc = SparkContext.getOrCreate(newConf)
val rdd = sc.textFile(inputFile)
val words: RDD[String] = rdd.flatMap(_.split(“ “).
map(_.trim.toLowerCase))
val wordPairs = words.map((_, 1))
val wordCounts = wordPairs.reduceByKey(_ + _)
wordCount.saveAsTextFile(outputFile)
Trish Hamme
Settings go here
This is a shuffle](https://image.slidesharecdn.com/sparkautotuningtalkfinal1-180917214055/85/Understanding-Spark-Tuning-Strata-New-York-8-320.jpg)
![I can haz application :p
val conf = new SparkConf()
.setMaster("local")
.setAppName("my_awesome_app")
val sc = SparkContext.getOrCreate(newConf)
val rdd = sc.textFile(inputFile)
val words: RDD[String] = rdd.flatMap(_.split(“ “).
map(_.trim.toLowerCase))
val wordPairs = words.map((_, 1))
val wordCounts = wordPairs.reduceByKey(_ + _)
wordCount.saveAsTextFile(outputFile)
Trish Hamme
Start of application
End Stage 1
Stage 2
Action, Launches Job](https://image.slidesharecdn.com/sparkautotuningtalkfinal1-180917214055/85/Understanding-Spark-Tuning-Strata-New-York-9-320.jpg)































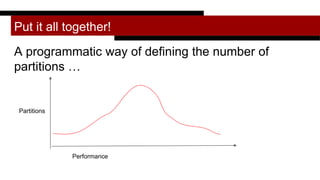


![Compute partitions given a list of metrics for the “biggest stage” across several runs
def fromStageMetricSharedCluster(previousRuns: List[StageInfo]): Int = {
previousRuns match {
case Nil =>
//If this is the first run and parallelism is not provided, use the number of concurrent tasks
//We could also look at the file on disk
possibleConcurrentTasks()
case first :: Nil =>
val fromInputSize = determinePartitionsFromInputDataSize(first.totalInputSize)
Math.max(first.numPartitionsUsed + math.max(first.numExecutors,1), fromInputSize)
}](https://image.slidesharecdn.com/sparkautotuningtalkfinal1-180917214055/85/Understanding-Spark-Tuning-Strata-New-York-46-320.jpg)