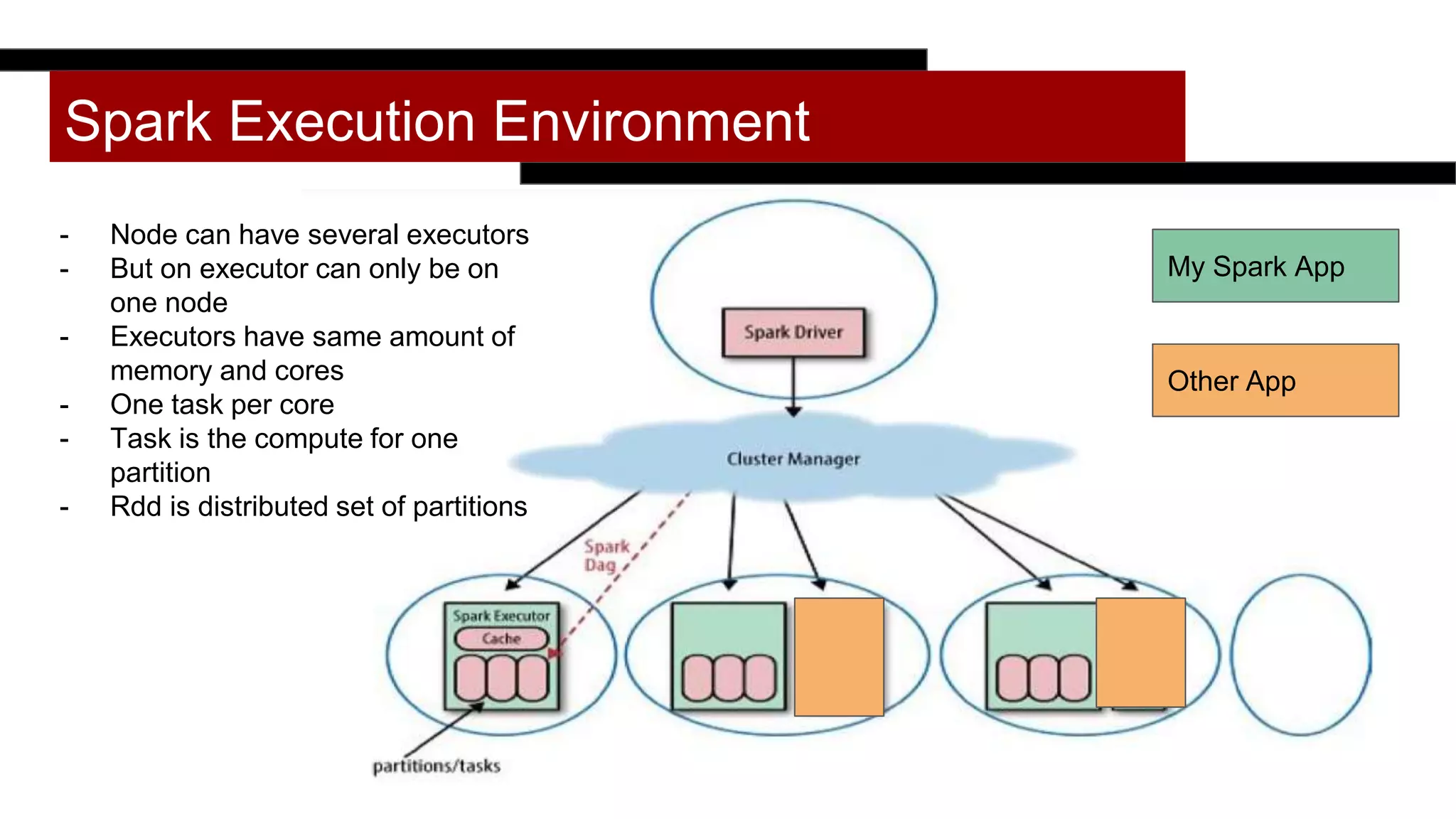
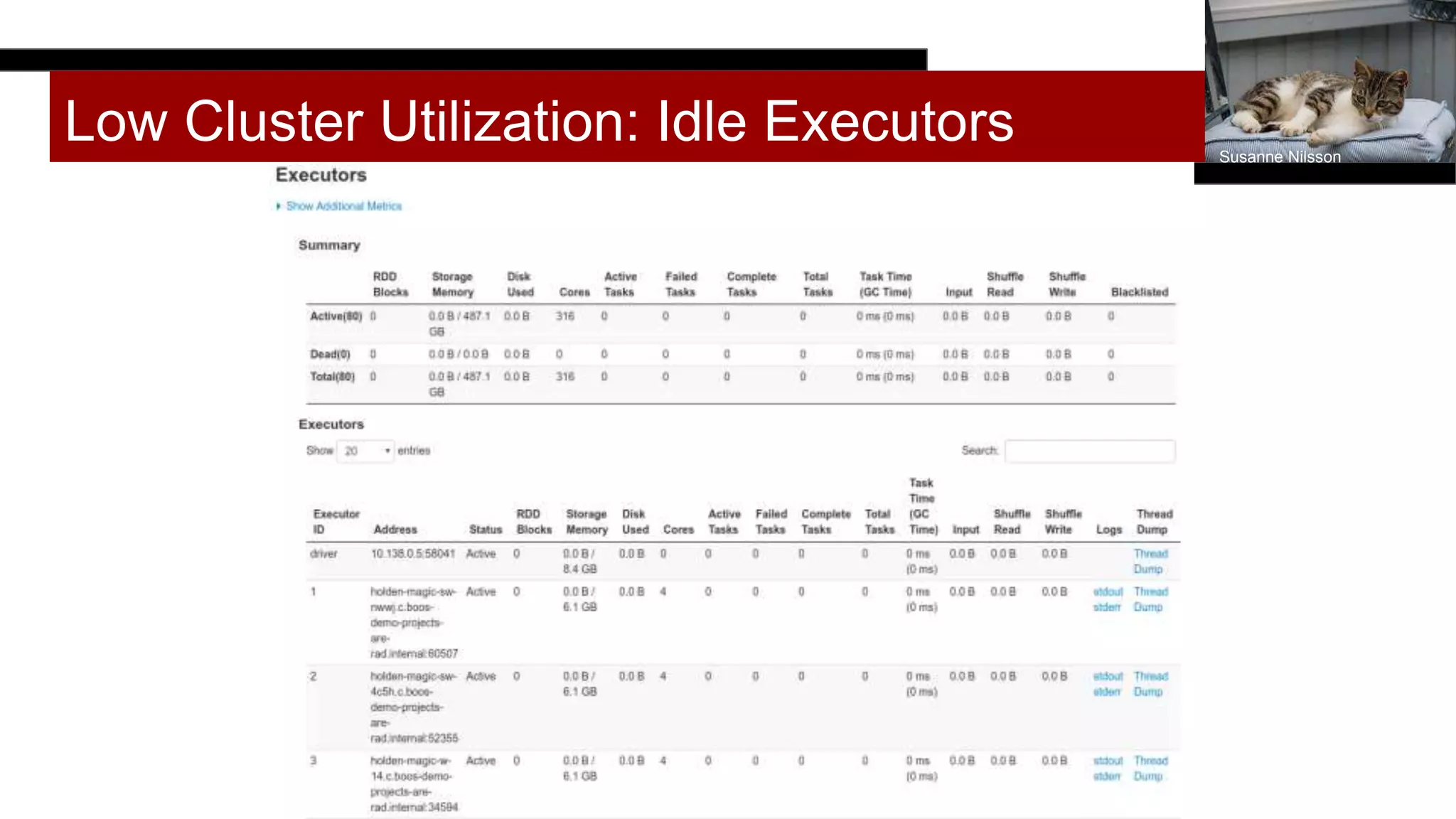
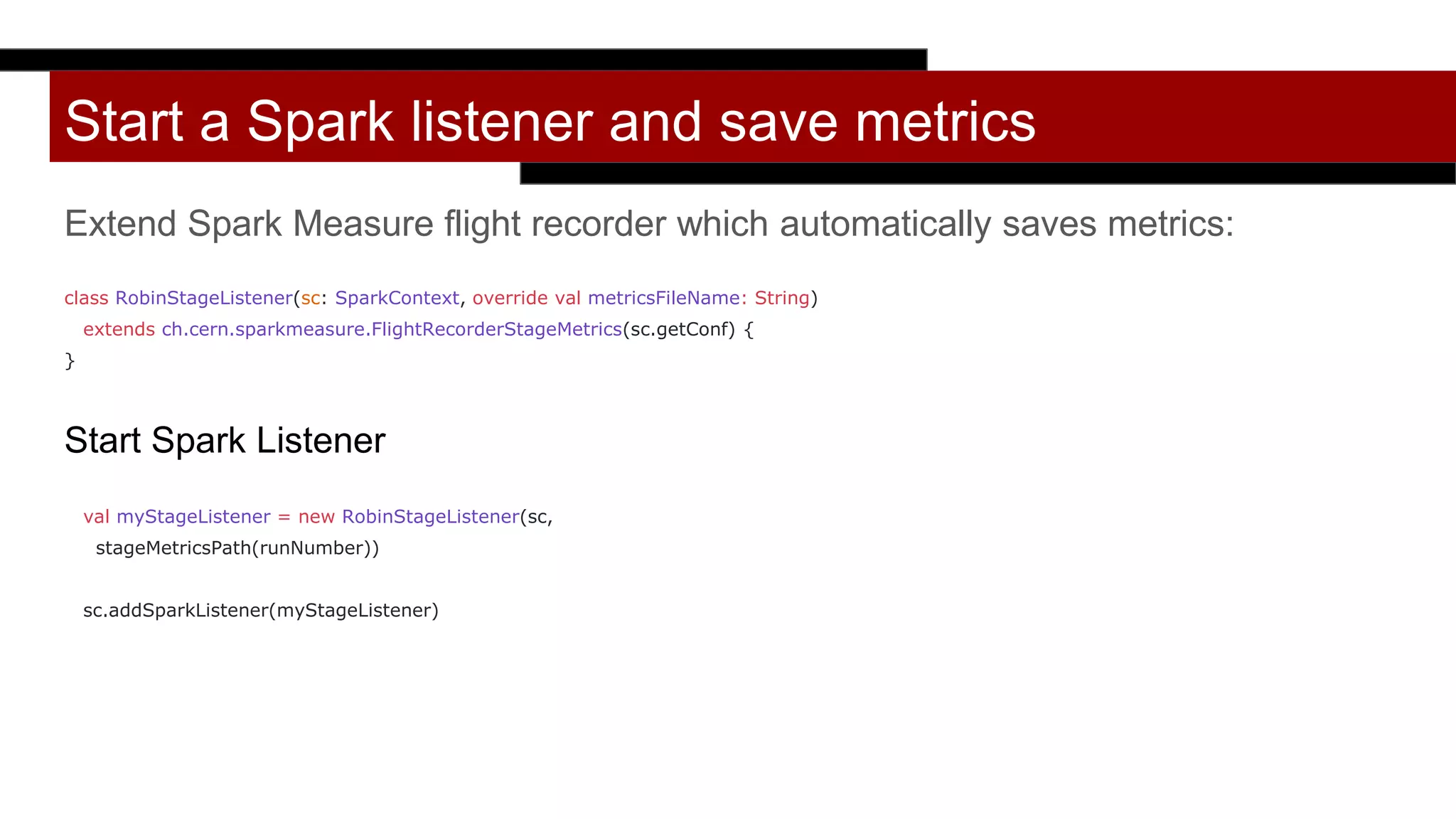
This document discusses programmatically tuning Spark jobs. It recommends collecting historical metrics like stage durations and task metrics from previous job runs. These metrics can then be used along with information about the execution environment and input data size to optimize configuration settings like memory, cores, partitions for new jobs. The document demonstrates using the Robin Sparkles library to save metrics and get an optimized configuration based on prior run data and metrics. Tuning goals include reducing out of memory errors, shuffle spills, and improving cluster utilization.





![I can haz application :p
val conf = new SparkConf()
.setMaster("local")
.setAppName("my_awesome_app")
val sc = SparkContext.getOrCreate(newConf)
val rdd = sc.textFile(inputFile)
val words: RDD[String] = rdd.flatMap(_.split(“ “).
map(_.trim.toLowerCase))
val wordPairs = words.map((_, 1))
val wordCounts = wordPairs.reduceByKey(_ + _)
wordCount.saveAsTextFile(outputFile)
Trish Hamme
Settings go here
This is a shuffle](https://image.slidesharecdn.com/sparkautotuningtalkfinal-180821184308/75/Spark-autotuning-talk-final-8-2048.jpg)
![I can haz application :p
val conf = new SparkConf()
.setMaster("local")
.setAppName("my_awesome_app")
val sc = SparkContext.getOrCreate(newConf)
val rdd = sc.textFile(inputFile)
val words: RDD[String] = rdd.flatMap(_.split(“ “).
map(_.trim.toLowerCase))
val wordPairs = words.map((_, 1))
val wordCounts = wordPairs.reduceByKey(_ + _)
wordCount.saveAsTextFile(outputFile)
Trish Hamme
Start of application
End Stage 1
Stage 2
Action, Launches Job](https://image.slidesharecdn.com/sparkautotuningtalkfinal-180821184308/75/Spark-autotuning-talk-final-9-2048.jpg)































![Compute the number of partitions given a list of web UI input for each stage
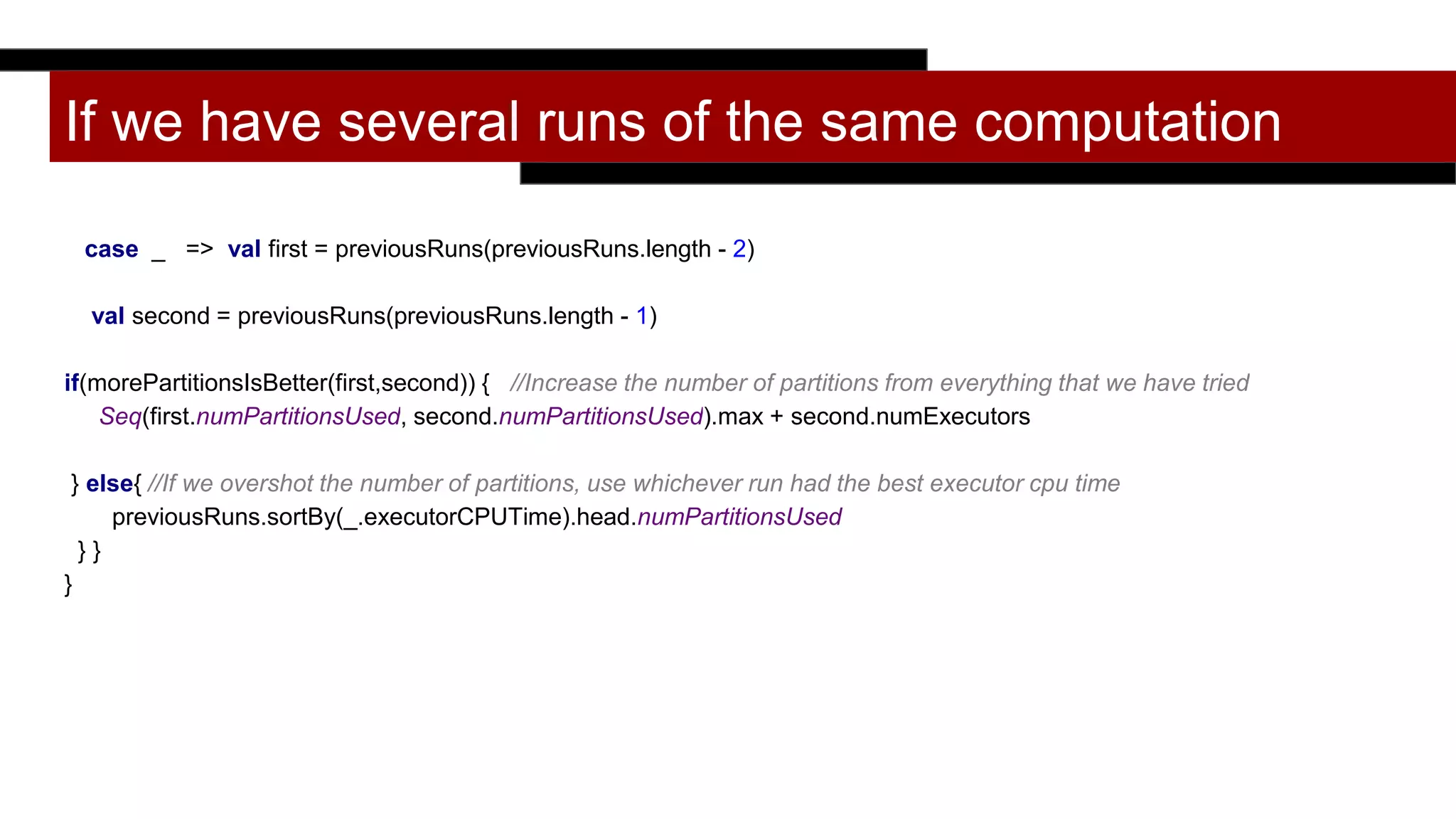
def fromStageMetricSharedCluster(previousRuns: List[StageInfo]): Int = {
previousRuns match {
case Nil =>
//If this is the first run and parallelism is not provided, use the number of concurrent tasks
//We could also look at the file on disk
possibleConcurrentTasks()
case first :: Nil =>
val fromInputSize = determinePartitionsFromInputDataSize(first.totalInputSize)
Math.max(first.numPartitionsUsed + math.max(first.numExecutors,1), fromInputSize)
}](https://image.slidesharecdn.com/sparkautotuningtalkfinal-180821184308/75/Spark-autotuning-talk-final-46-2048.jpg)





































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)







