This document provides an overview of Spark's RDD abstraction and the life cycle of a Spark application.
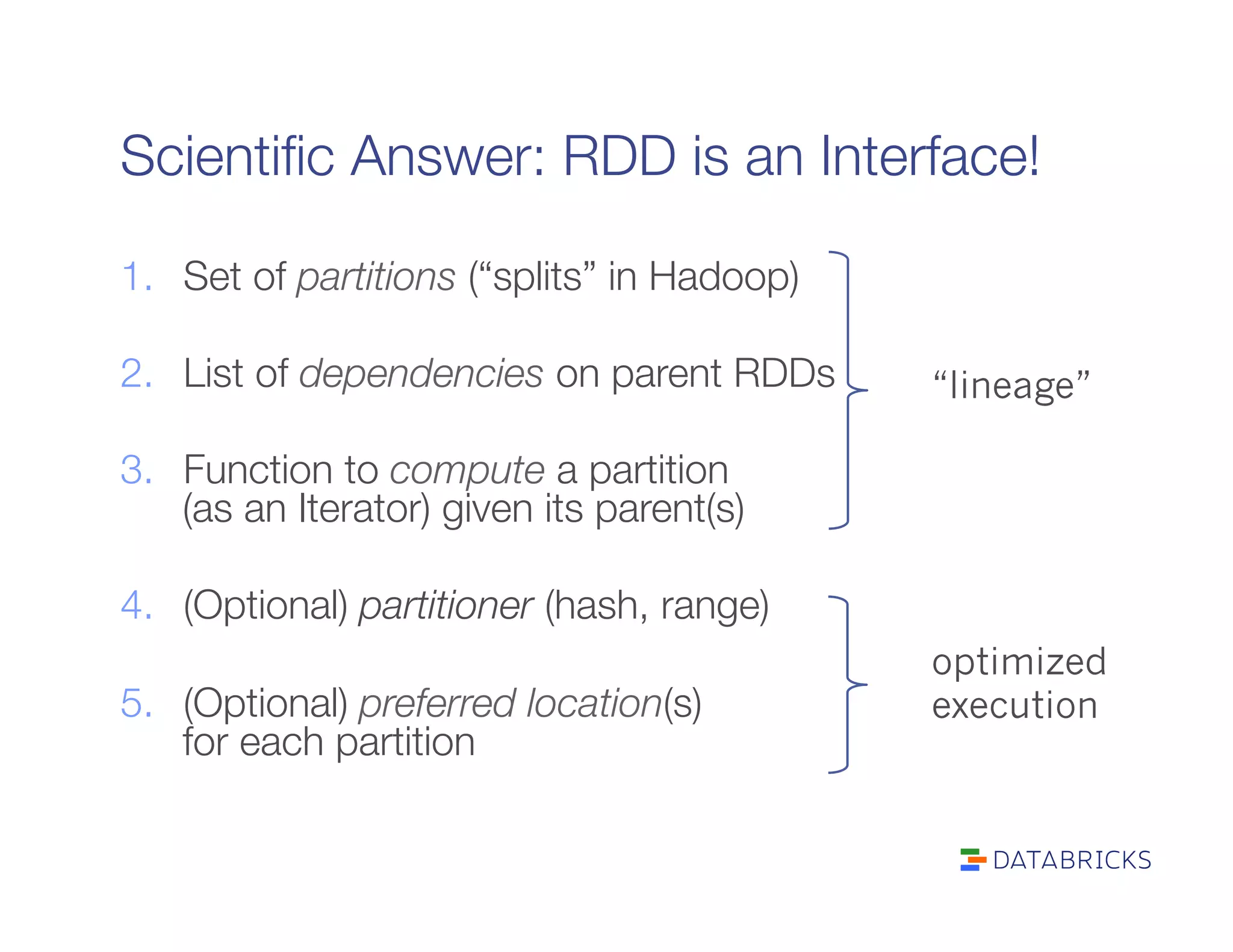
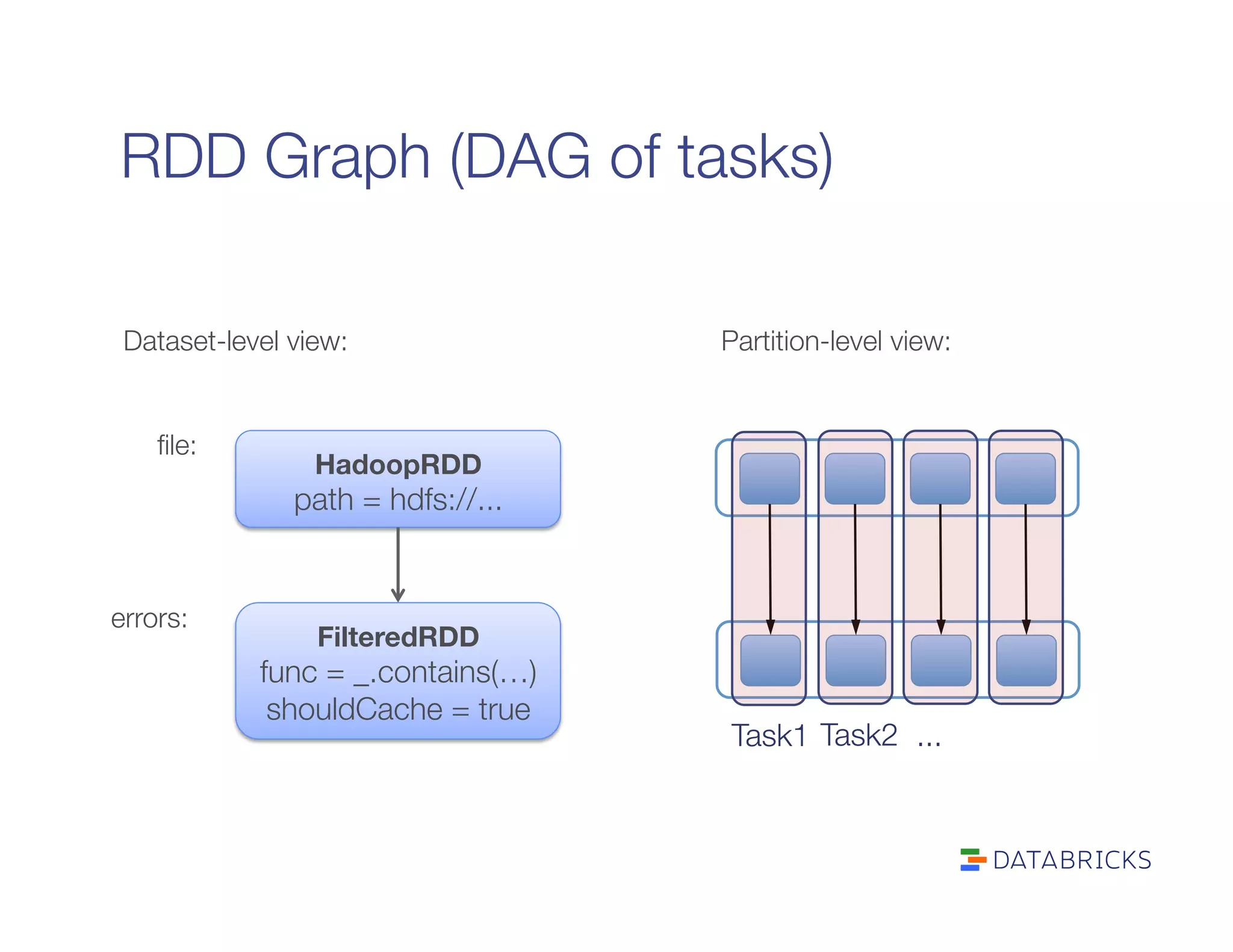
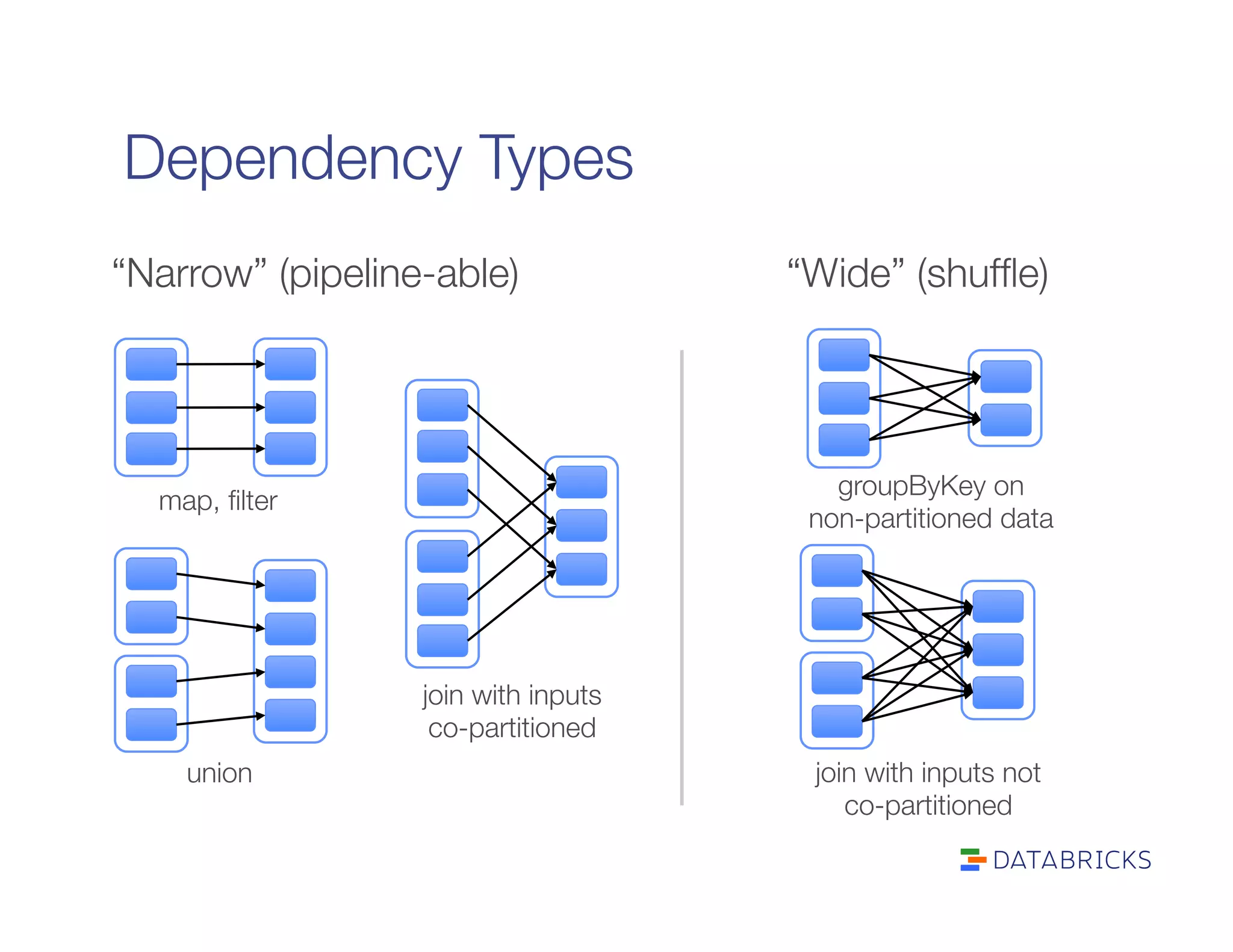
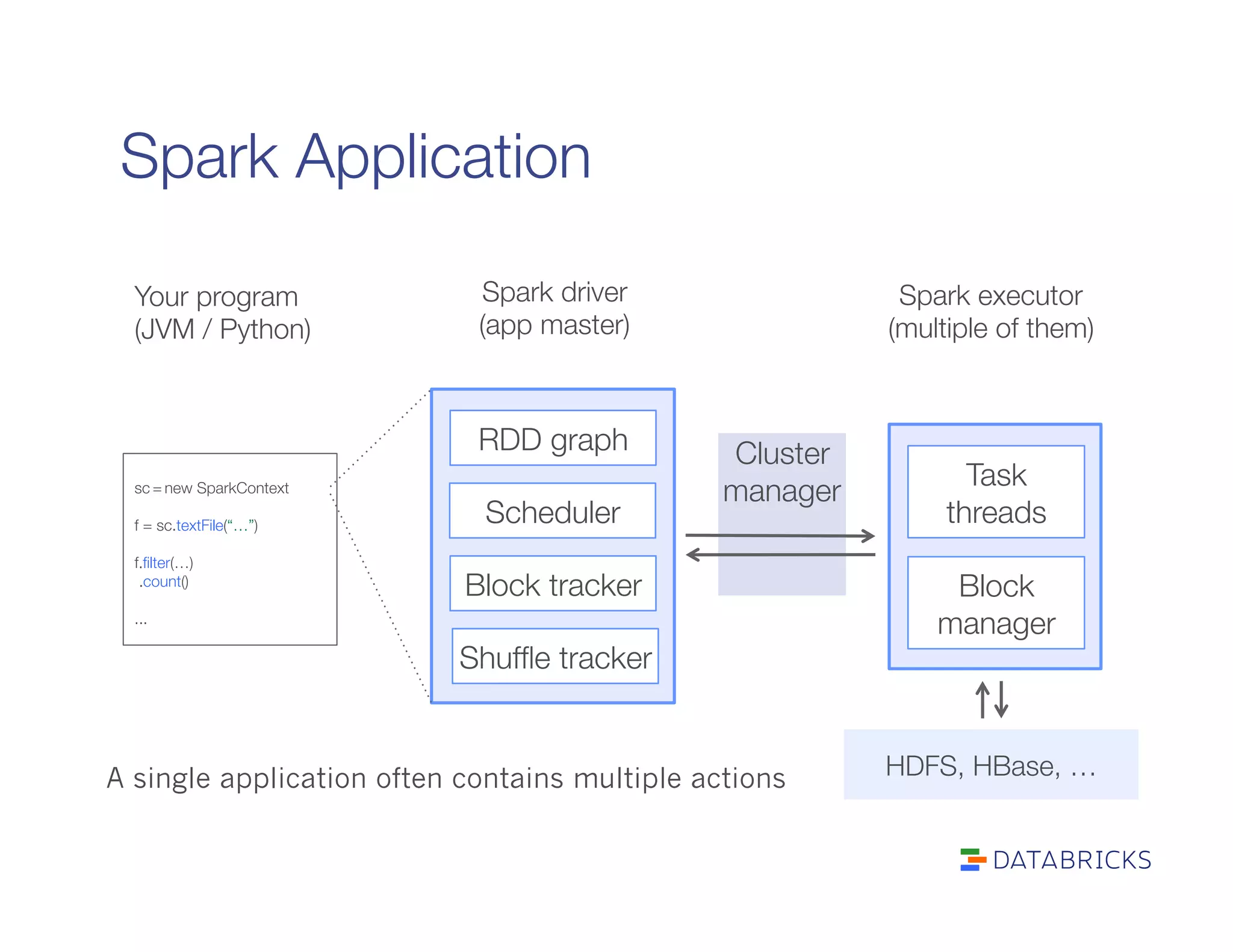
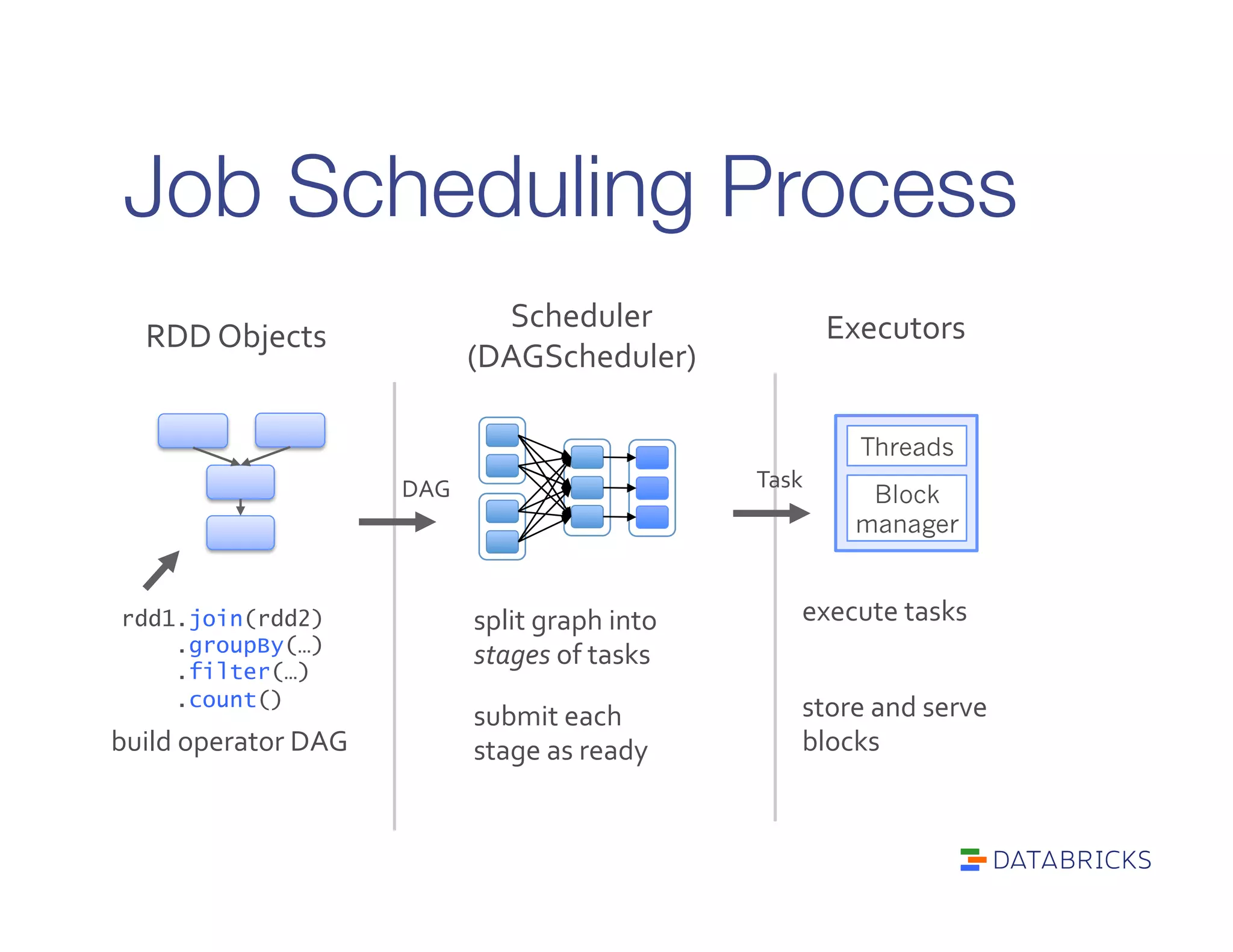
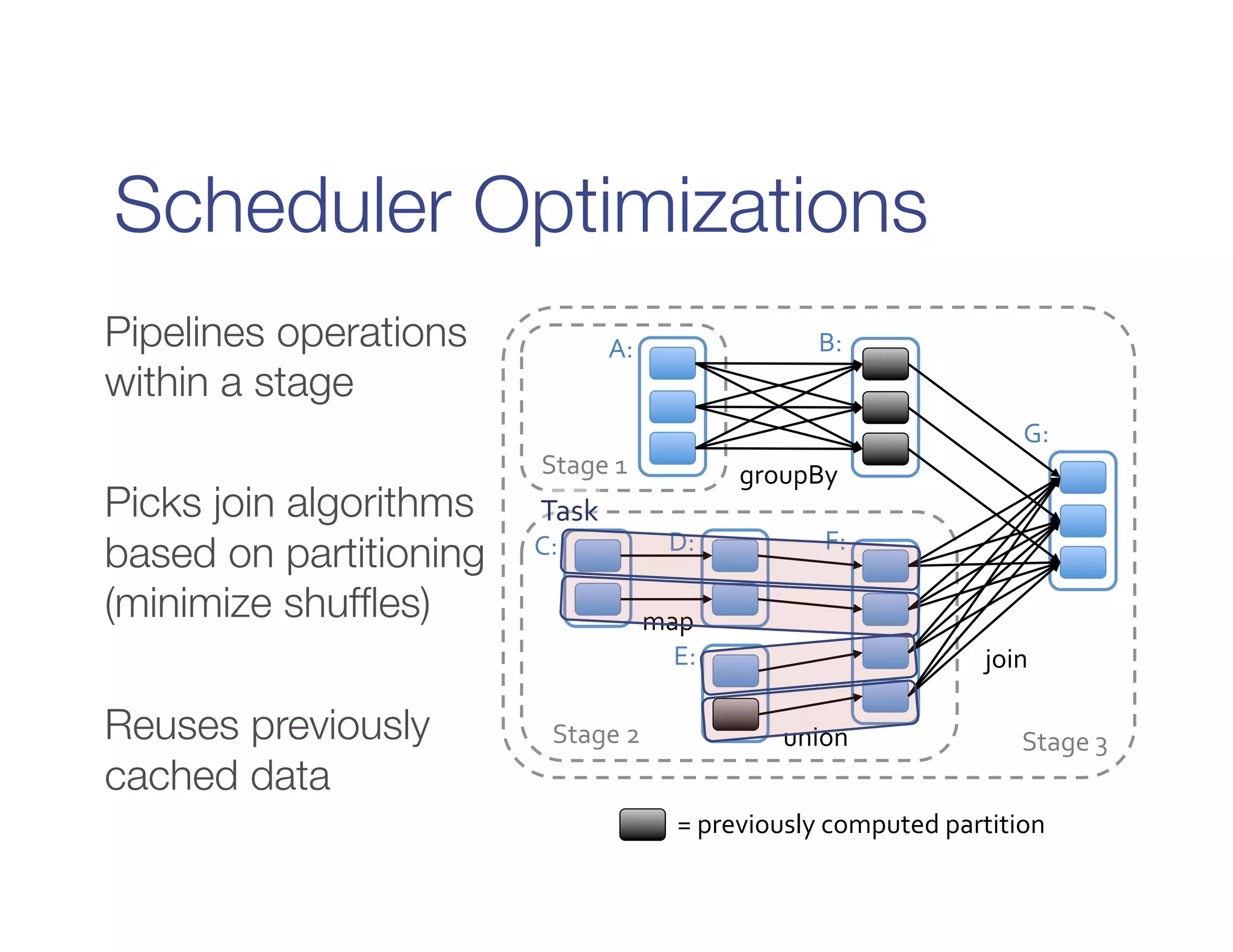
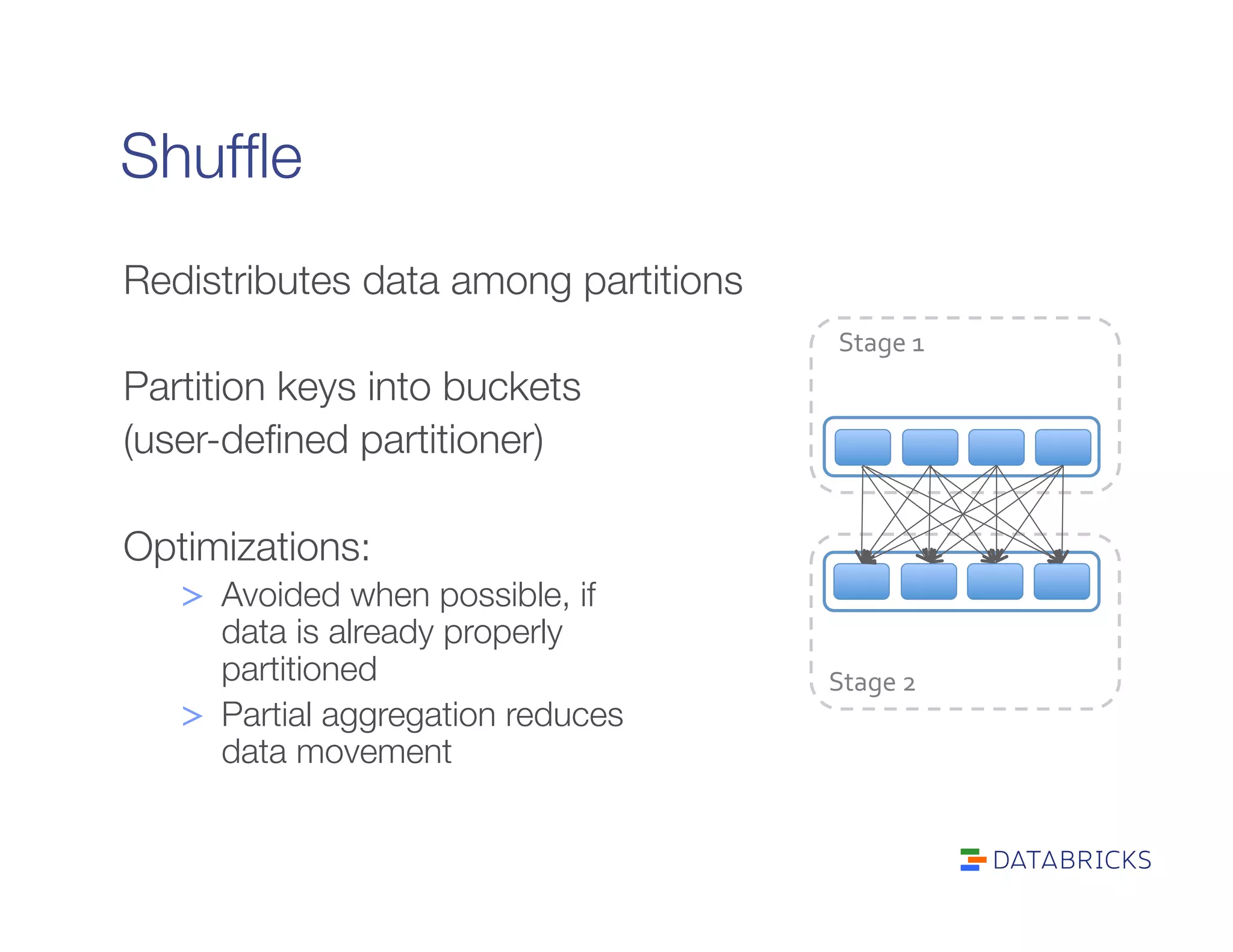
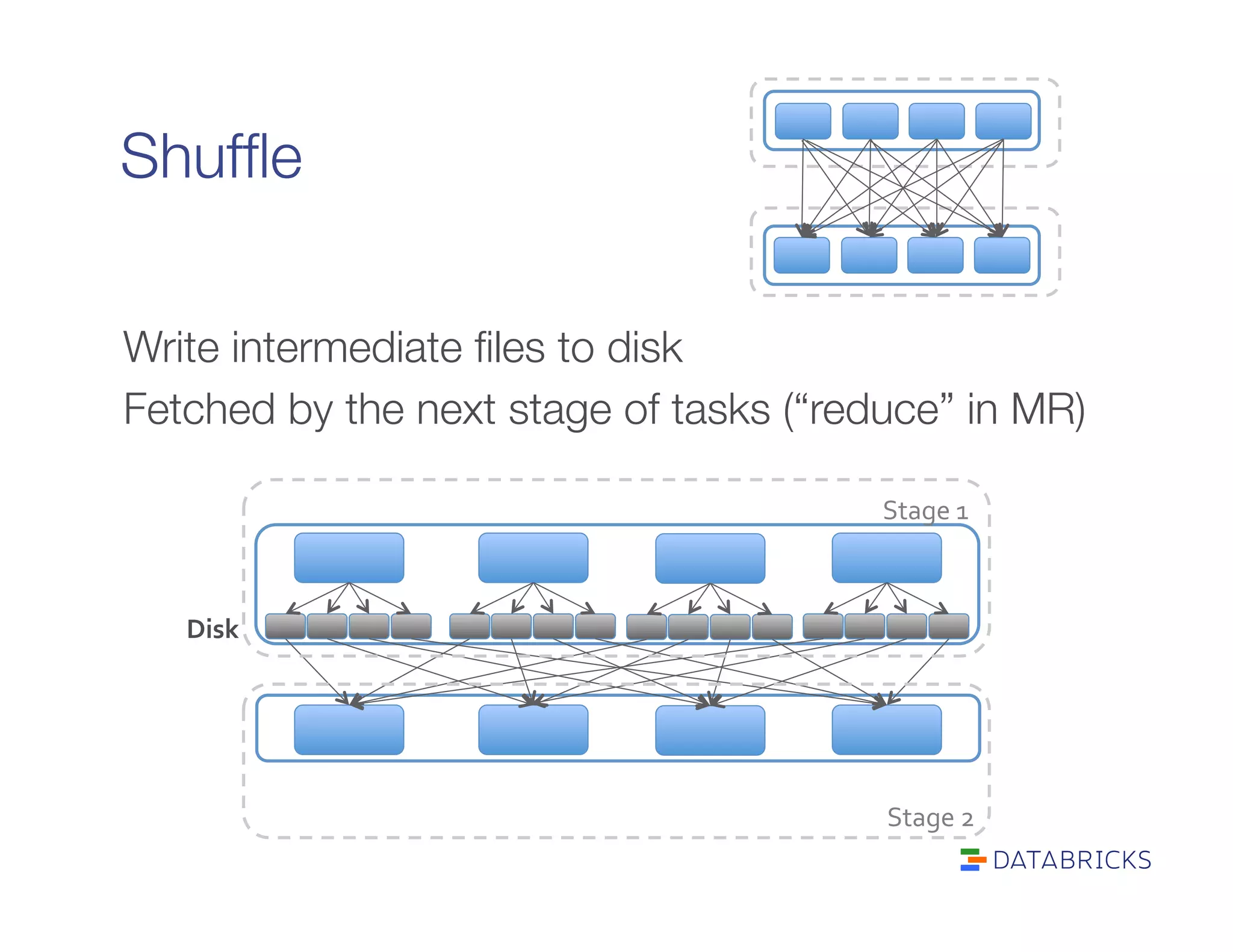
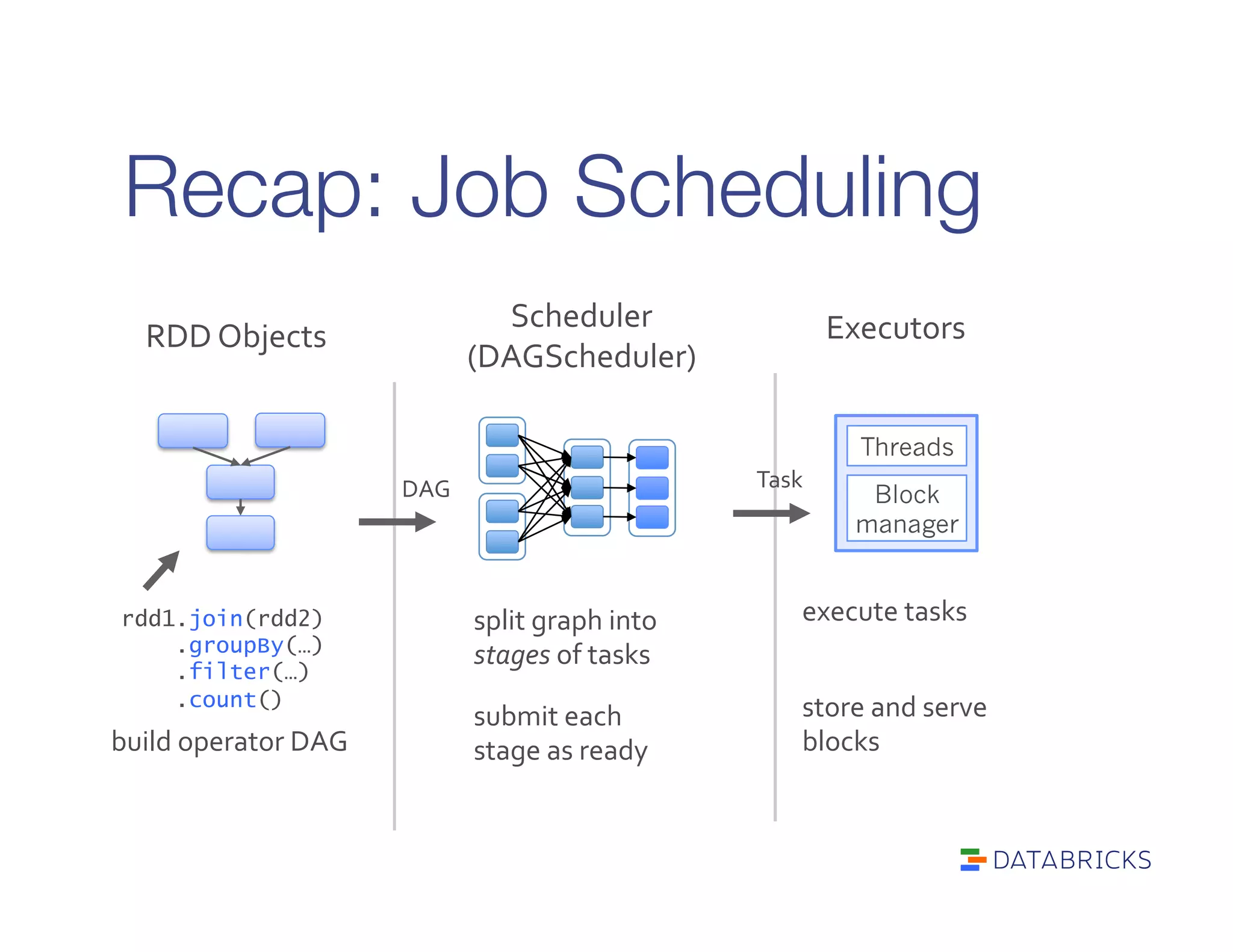
It defines RDDs as distributed collections characterized by partitions, dependencies, a compute function, and optional properties like a partitioner. It describes how Spark builds a DAG of stages from transformations and actions, and schedules tasks across executors.
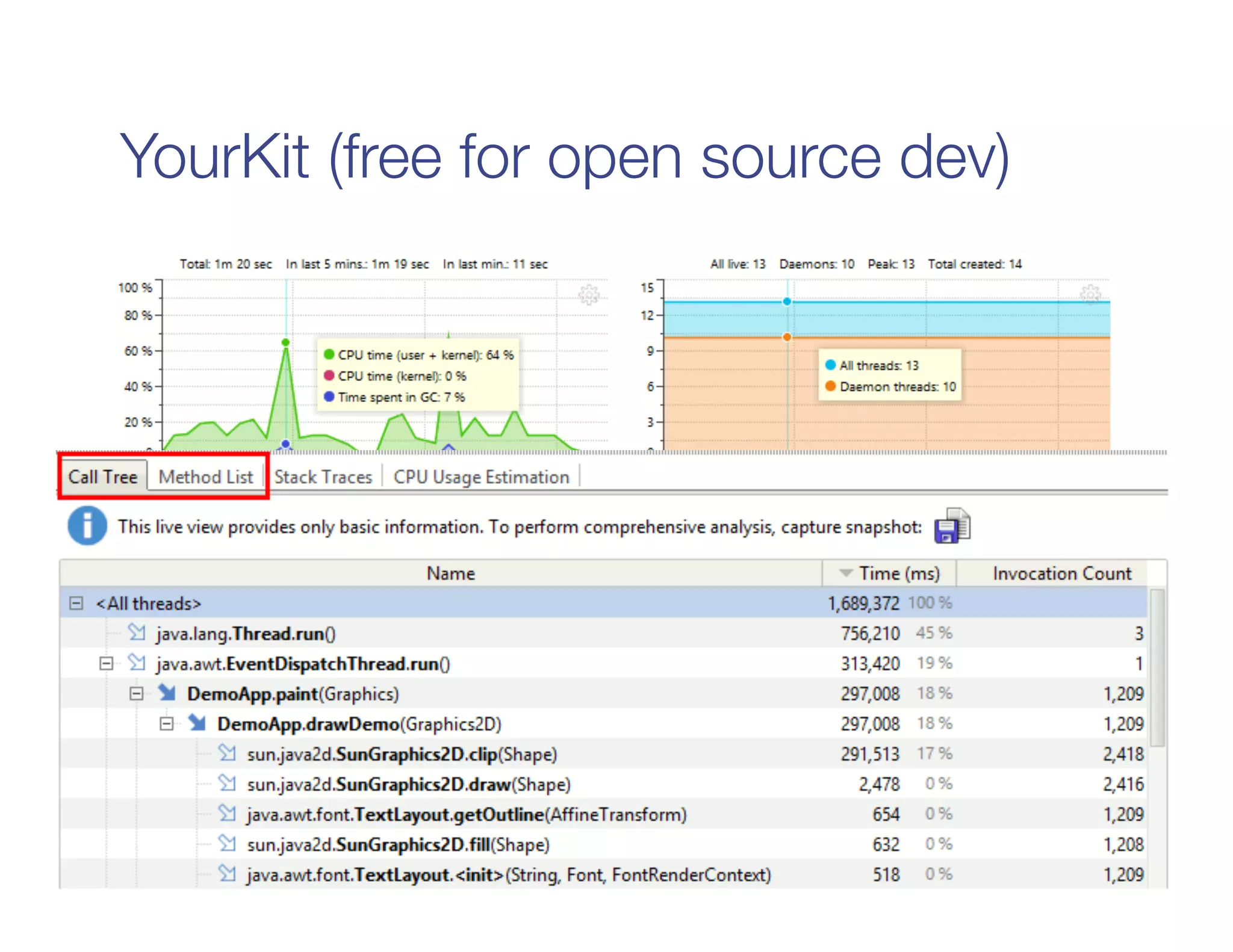
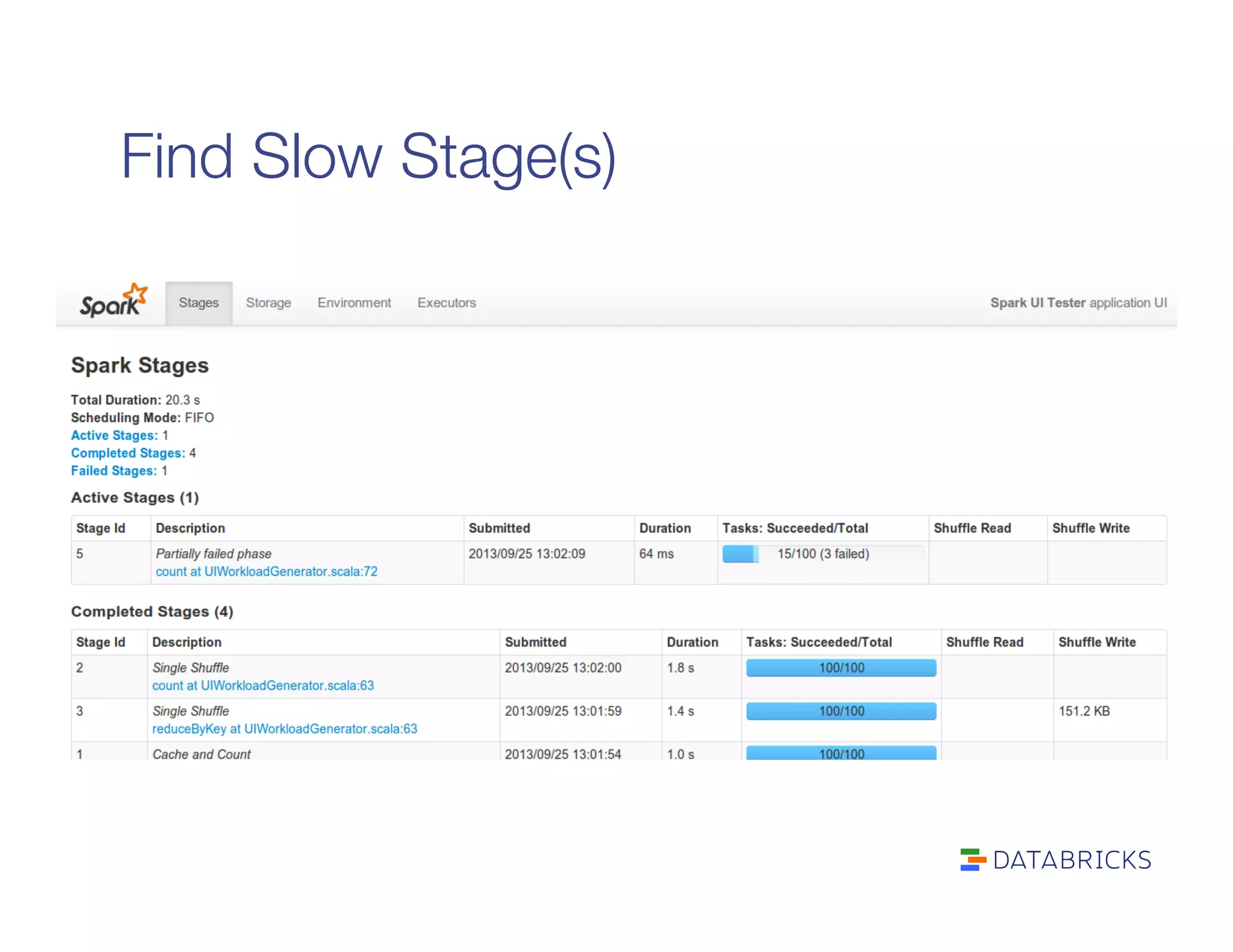
The document also covers performance debugging techniques like identifying slow stages, stragglers, garbage collection issues, and profiling tasks locally. Debugging tools discussed include the Spark UI, executor logs, jstack, and YourKit.























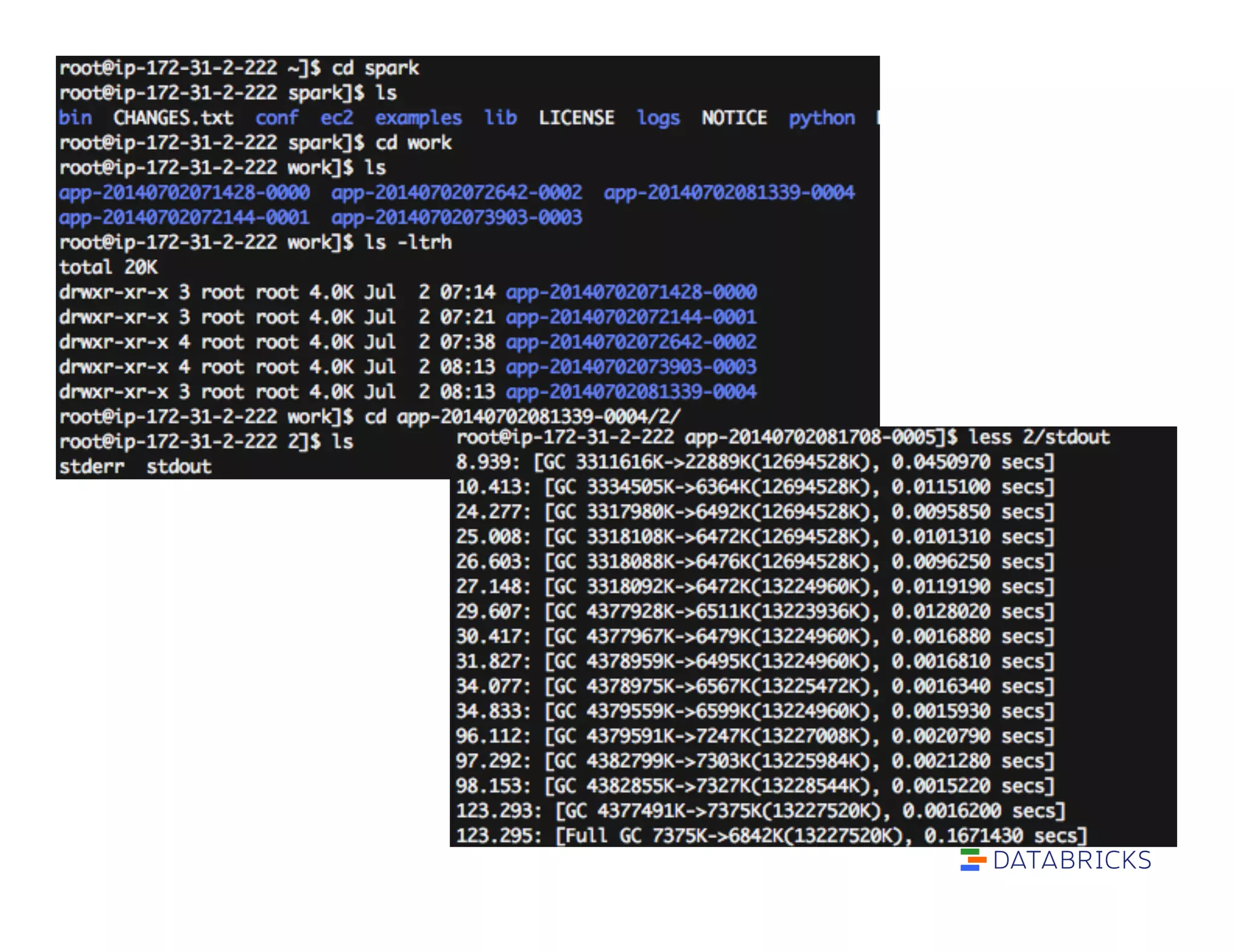
![What if the task is still running?
To discover whether GC is the problem:
1. Set spark.executor.extraJavaOptions to include:
“-XX:-PrintGCDetails -XX:+PrintGCTimeStamps”
2. Look at spark/work/app…/[n]/stdout on
executors
3. Short GC times are OK. Long ones are bad.](https://image.slidesharecdn.com/advancedsparktrainingadvancedsparkinternalsandtuning-reynoldxin-190828031103/75/Advanced-spark-training-advanced-spark-internals-and-tuning-reynold-xin-34-2048.jpg)
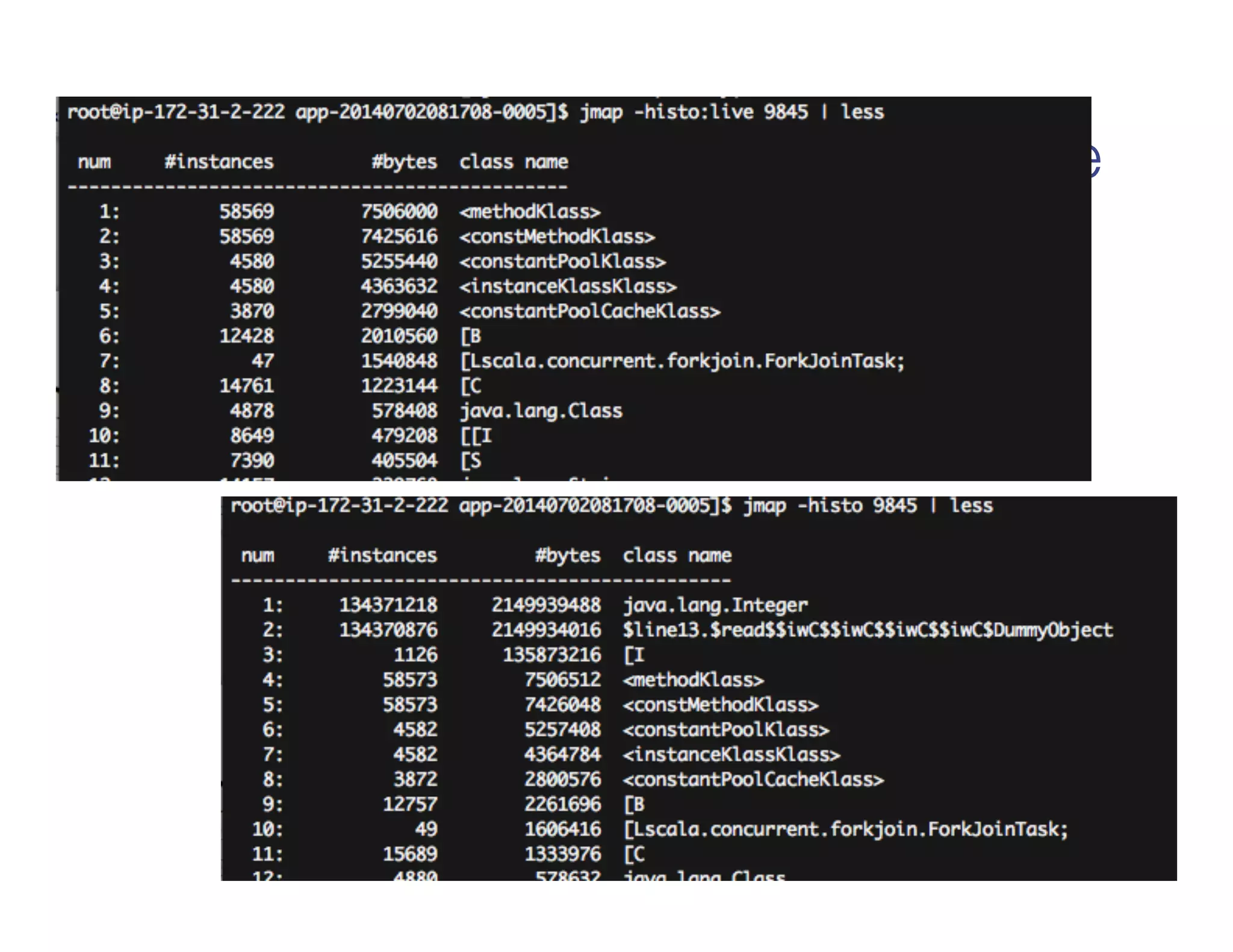
![jmap: heap analysis
jmap -histo [pid]
Gets a histogram of objects in the JVM heap
jmap -histo:live [pid]
Gets a histogram of objects in the heap after GC
(thus “live”)](https://image.slidesharecdn.com/advancedsparktrainingadvancedsparkinternalsandtuning-reynoldxin-190828031103/75/Advanced-spark-training-advanced-spark-internals-and-tuning-reynold-xin-36-2048.jpg)