Download as PDF, PPTX


















![def findLargeShardIds(sc: SparkContext, threshold: Long, …..): Set[Int] = {
val shardSizesRDD = sc.textFile(shardCountsFile)
.map {
case line =>
val Array(indexStr, countStr) = line.split('t')
(indexStr.toInt, countStr.toLong)
}
val largeShardIds = shardSizesRDD.filter {
case (index, count) => count > threshold
}.map(_._1)
.collect().toSet
return largeShardIds
}](https://image.slidesharecdn.com/6ctejaspatil-170214194733/75/Custom-Applications-with-Spark-s-RDD-Spark-Summit-East-talk-by-Tejas-Patil-29-2048.jpg)

![var iterationId = 0
do {
val currentCounts: RDD[(String, Long)] = allCounts(iterationId - 1)
val partitioner = new PartitionerForNgram(numShards, iterationId)
val shardCountsFile = s"${shard_sizes}_$iterationId"
currentCounts
.map(ngram => (partitioner.getPartition(ngram._1), 1L))
.reduceByKey(_ + _)
.saveAsTextFile(shardCountsFile)
largeShardIds = findLargeShardIds(sc, config.largeShardThreshold, shardCountsFile)
trainer.trainedModel (currentCounts, component, largeShardIds)
.saveAsObjectFile(s"${component.order}_$iterationId")
iterationId + 1
} while (largeShards.nonEmpty)](https://image.slidesharecdn.com/6ctejaspatil-170214194733/75/Custom-Applications-with-Spark-s-RDD-Spark-Summit-East-talk-by-Tejas-Patil-35-2048.jpg)

![Upstream contributions to pipe()
• [SPARK-13793] PipedRDD doesn't propagate exceptions while
reading parent RDD
• [SPARK-15826] PipedRDD to allow configurable char encoding
• [SPARK-14542] PipeRDD should allow configurable buffer size for
the stdin writer
• [SPARK-14110] PipedRDD to print the command ran on non zero
exit](https://image.slidesharecdn.com/6ctejaspatil-170214194733/75/Custom-Applications-with-Spark-s-RDD-Spark-Summit-East-talk-by-Tejas-Patil-38-2048.jpg)


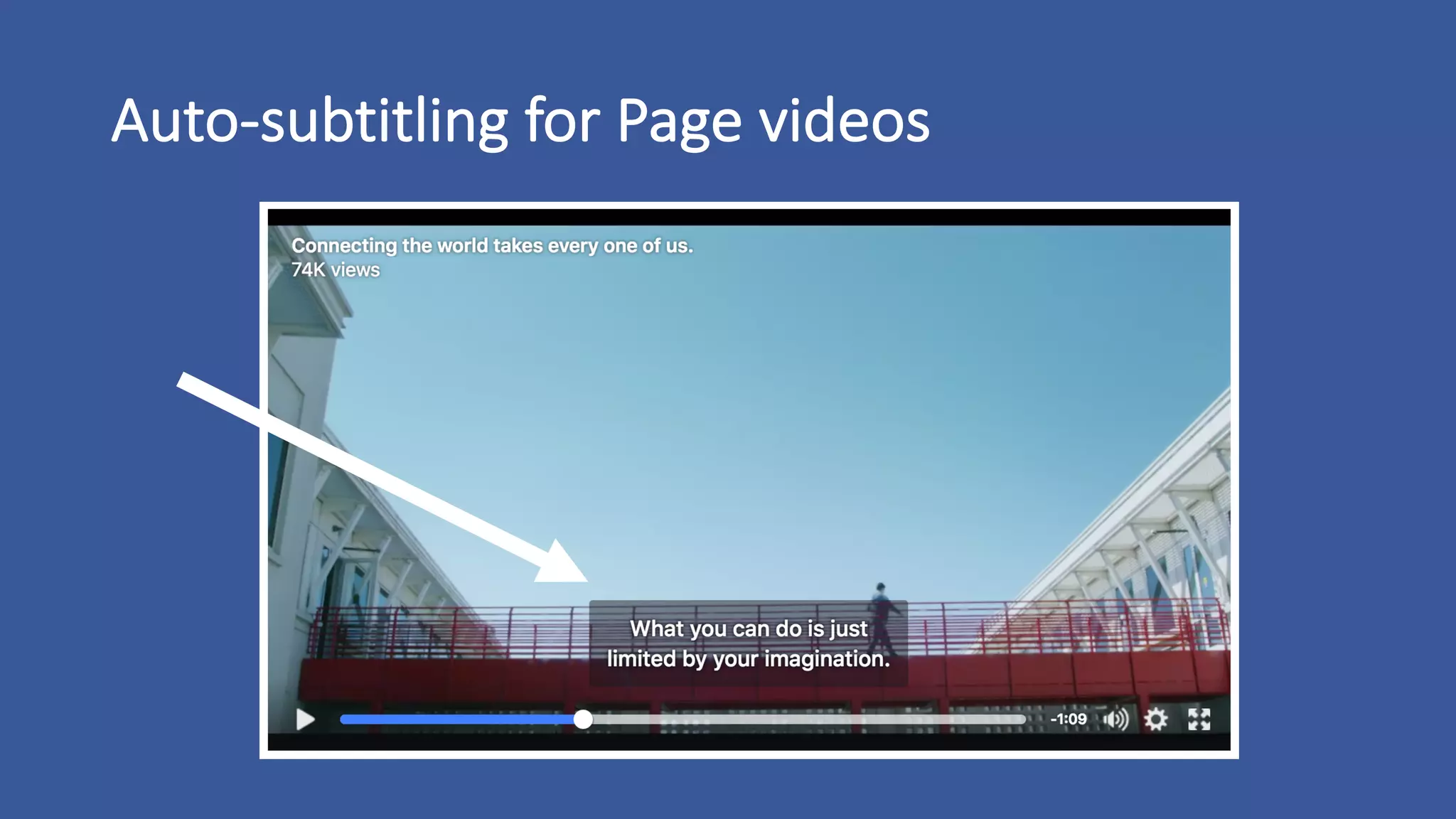
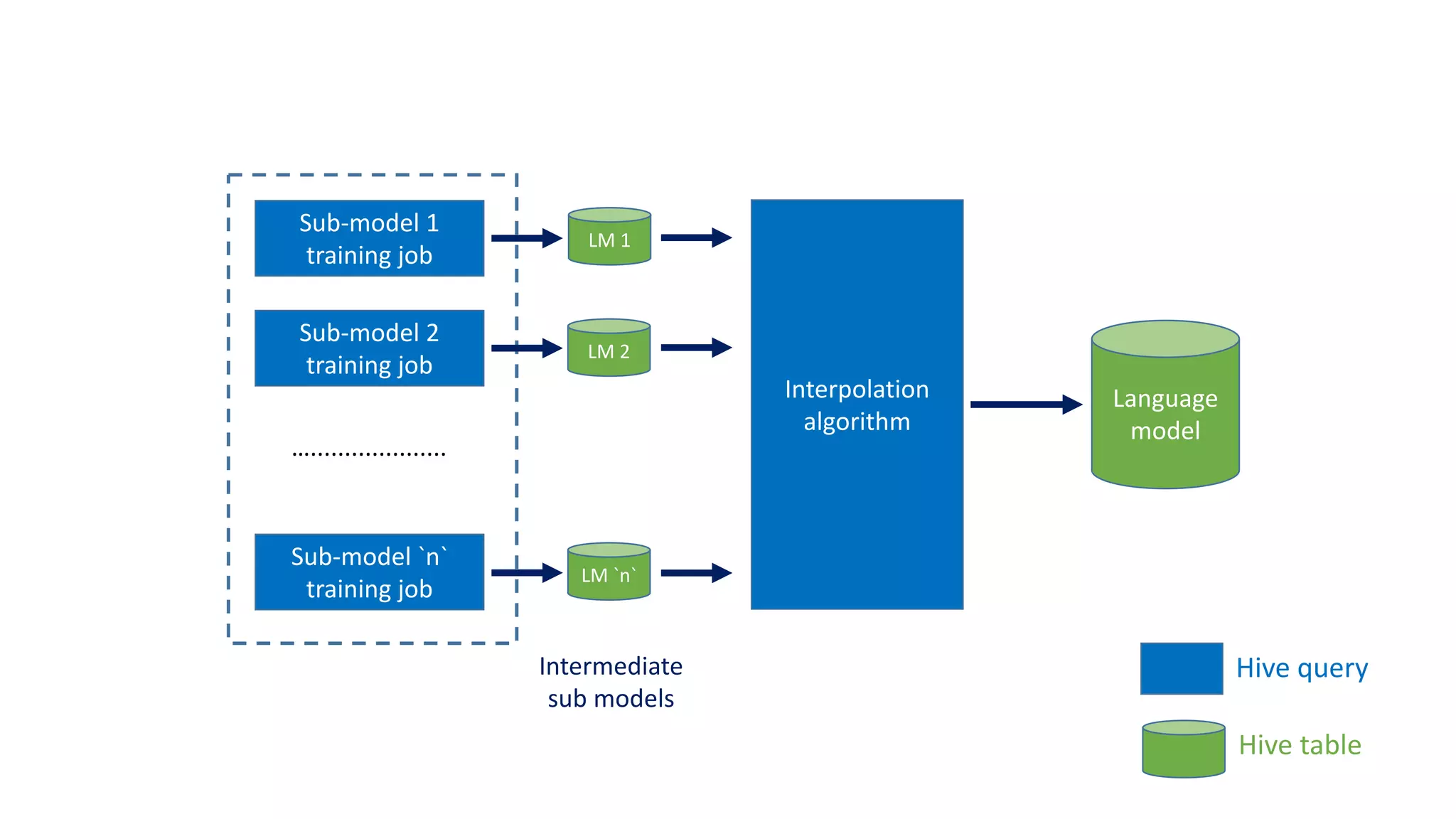
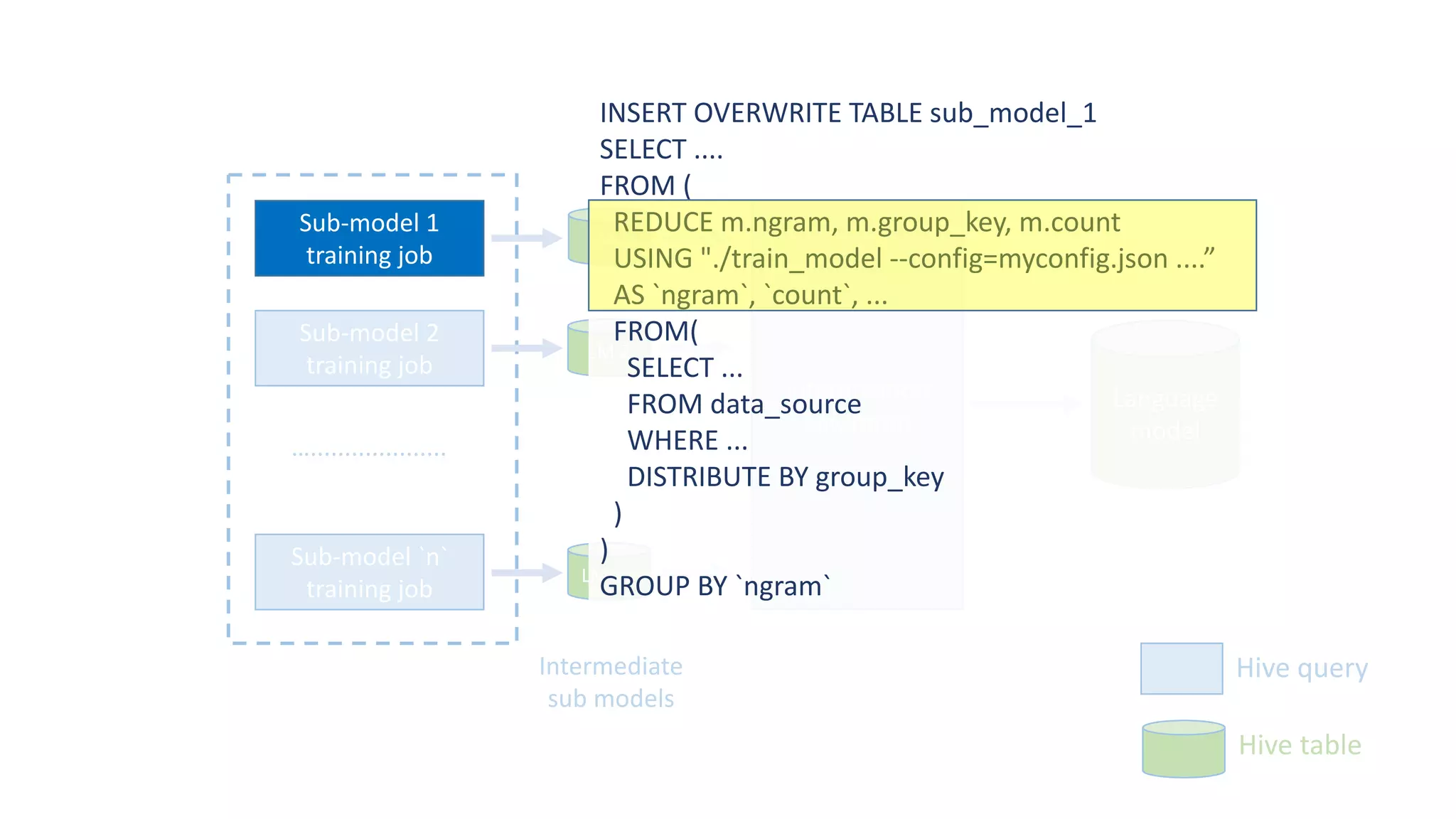
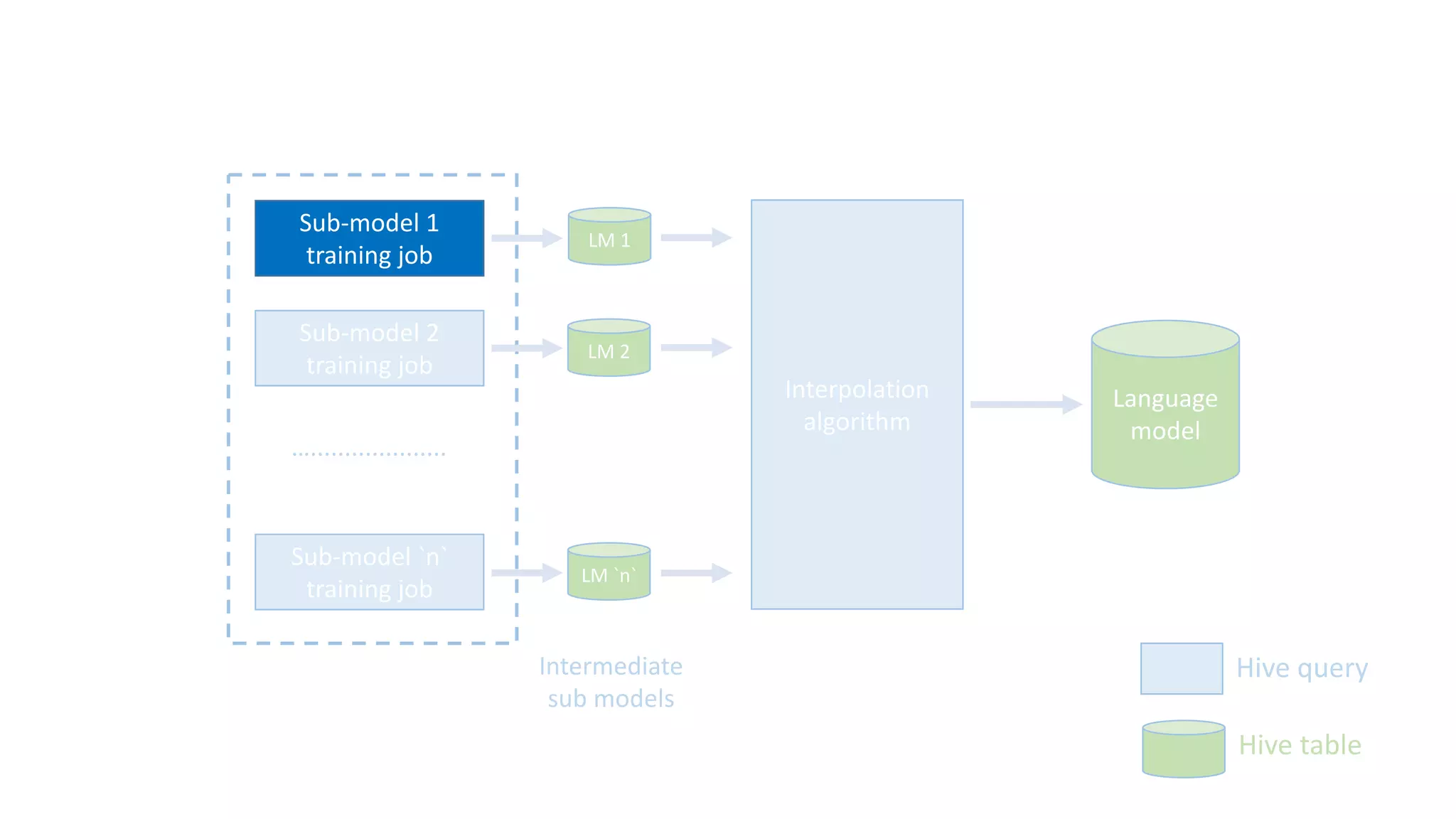
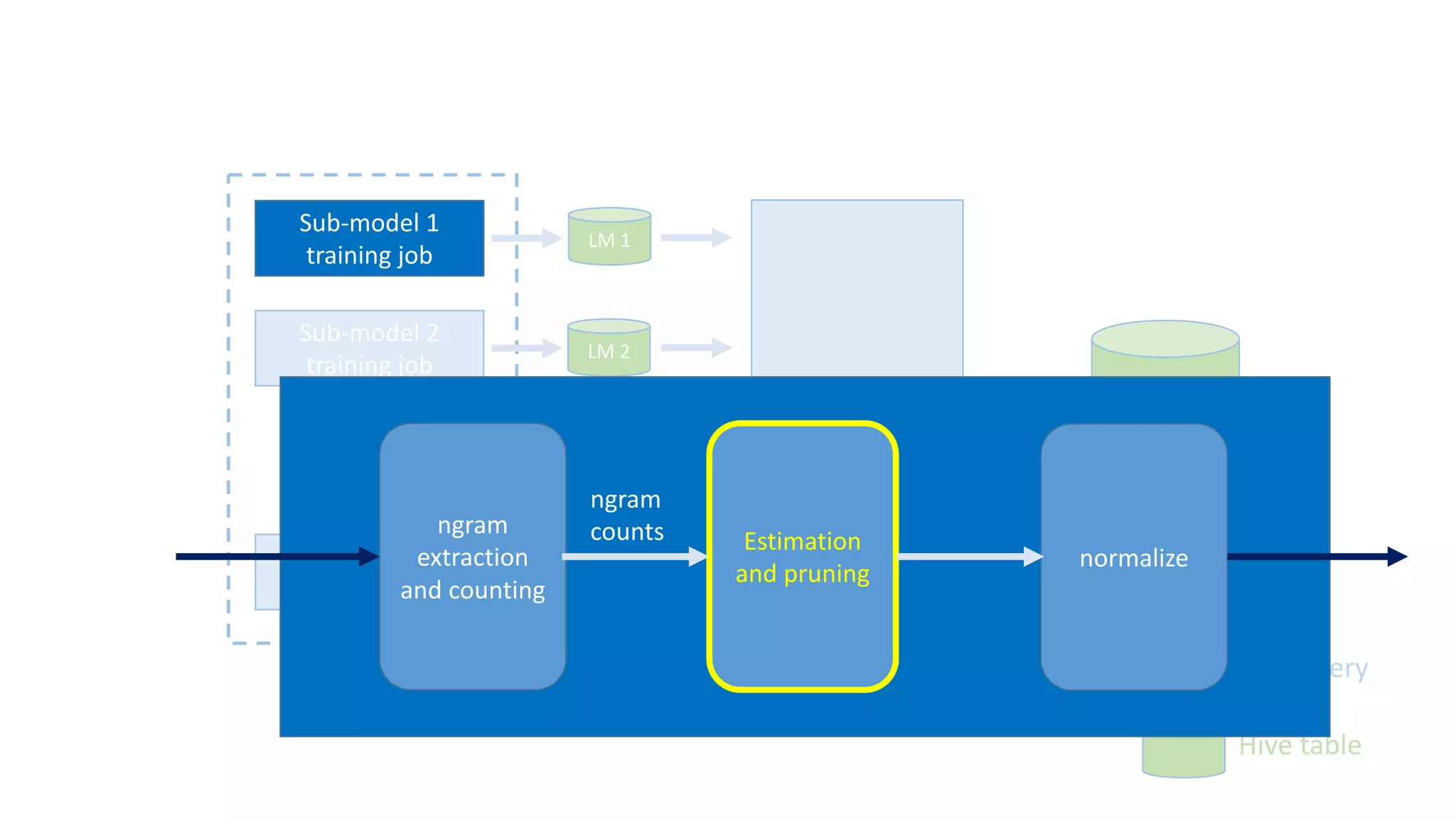
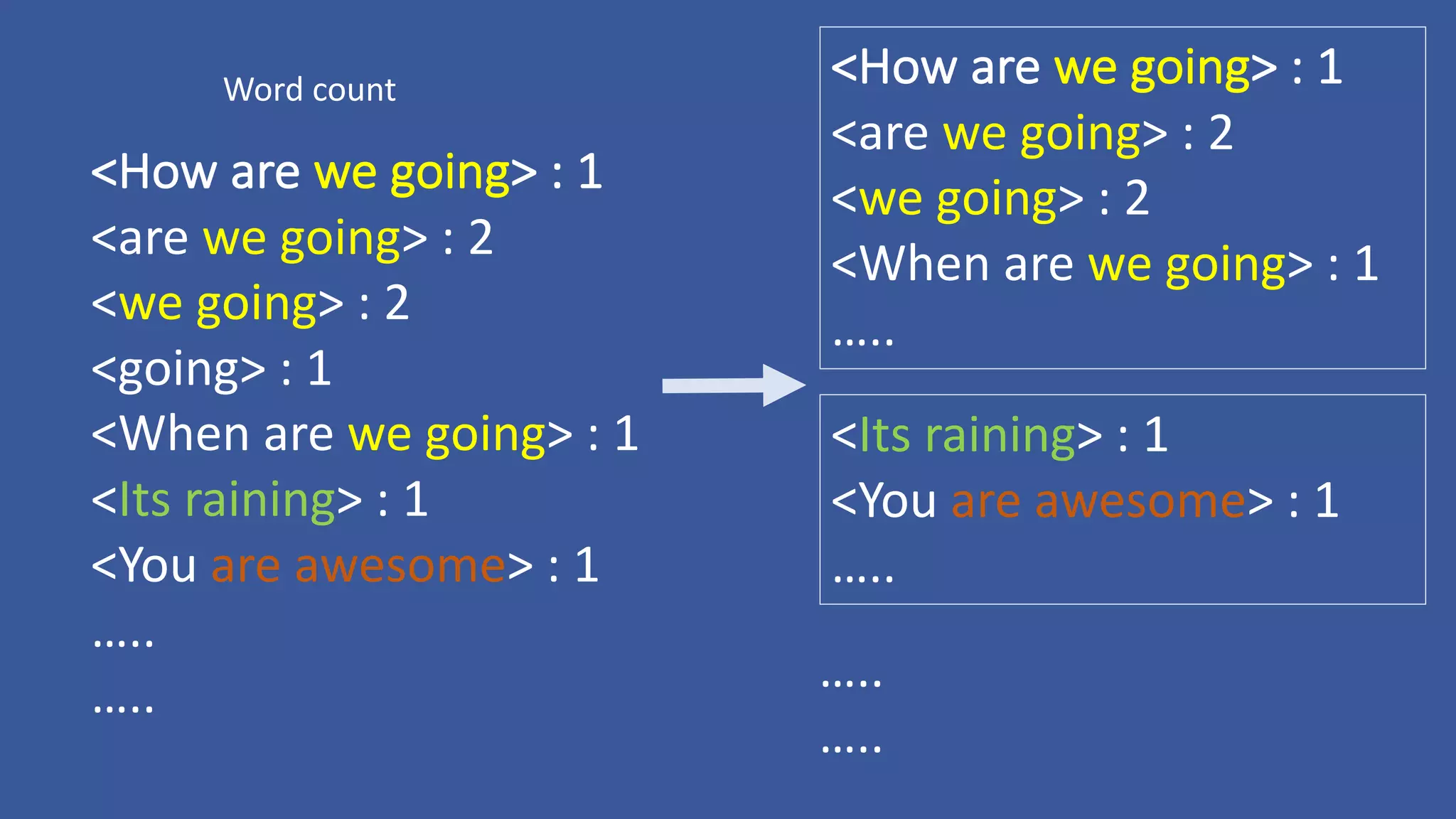
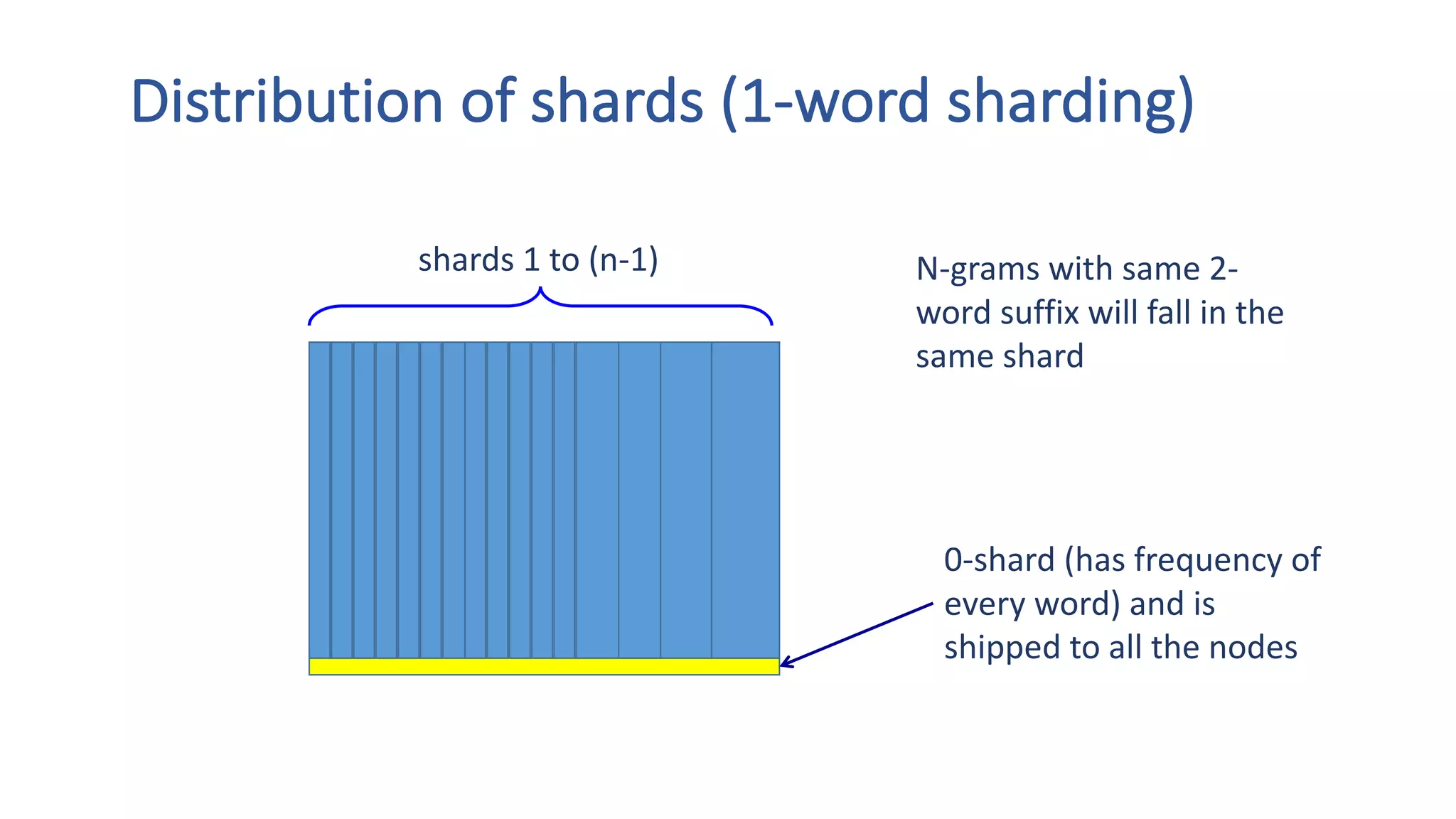
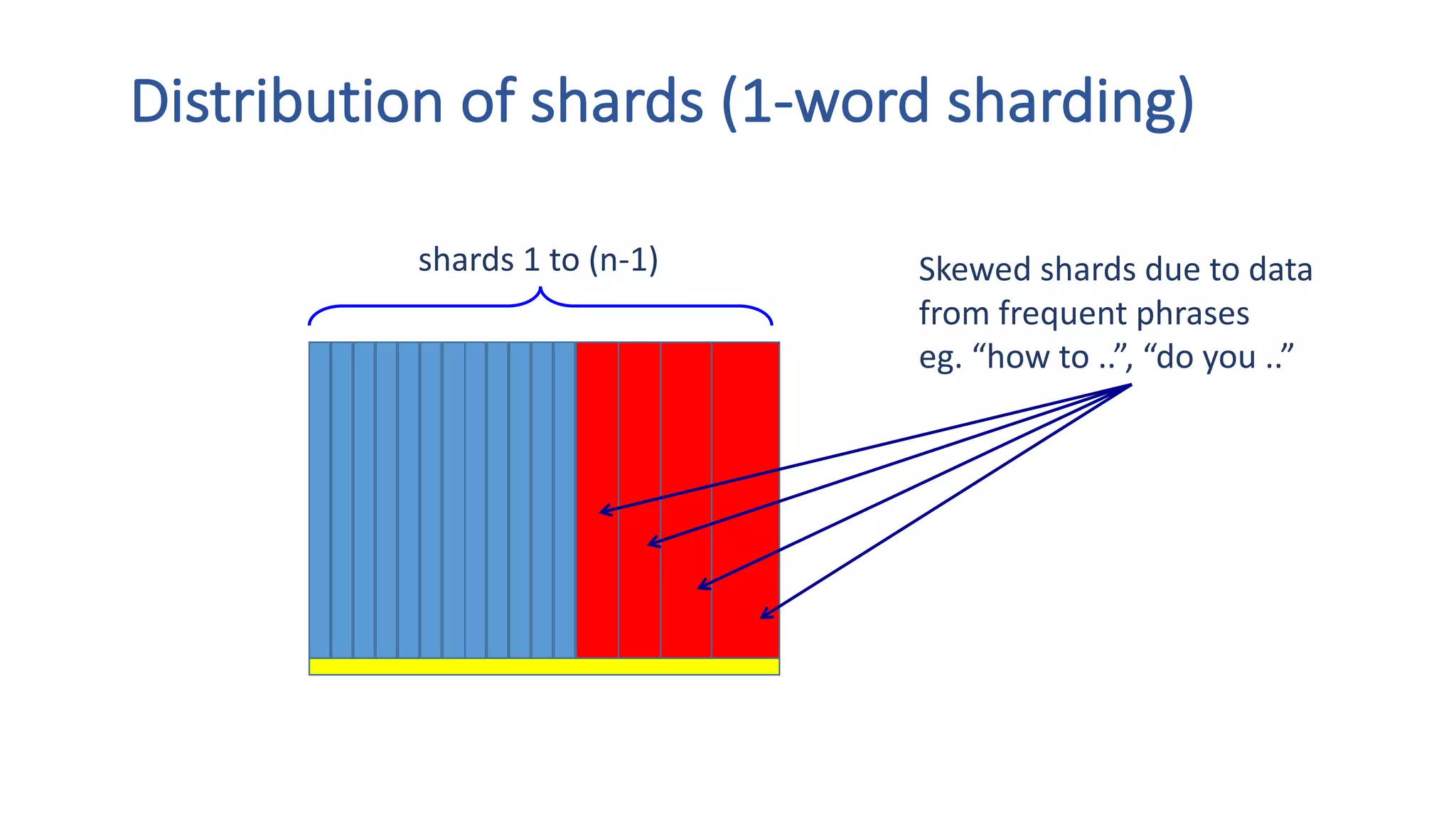
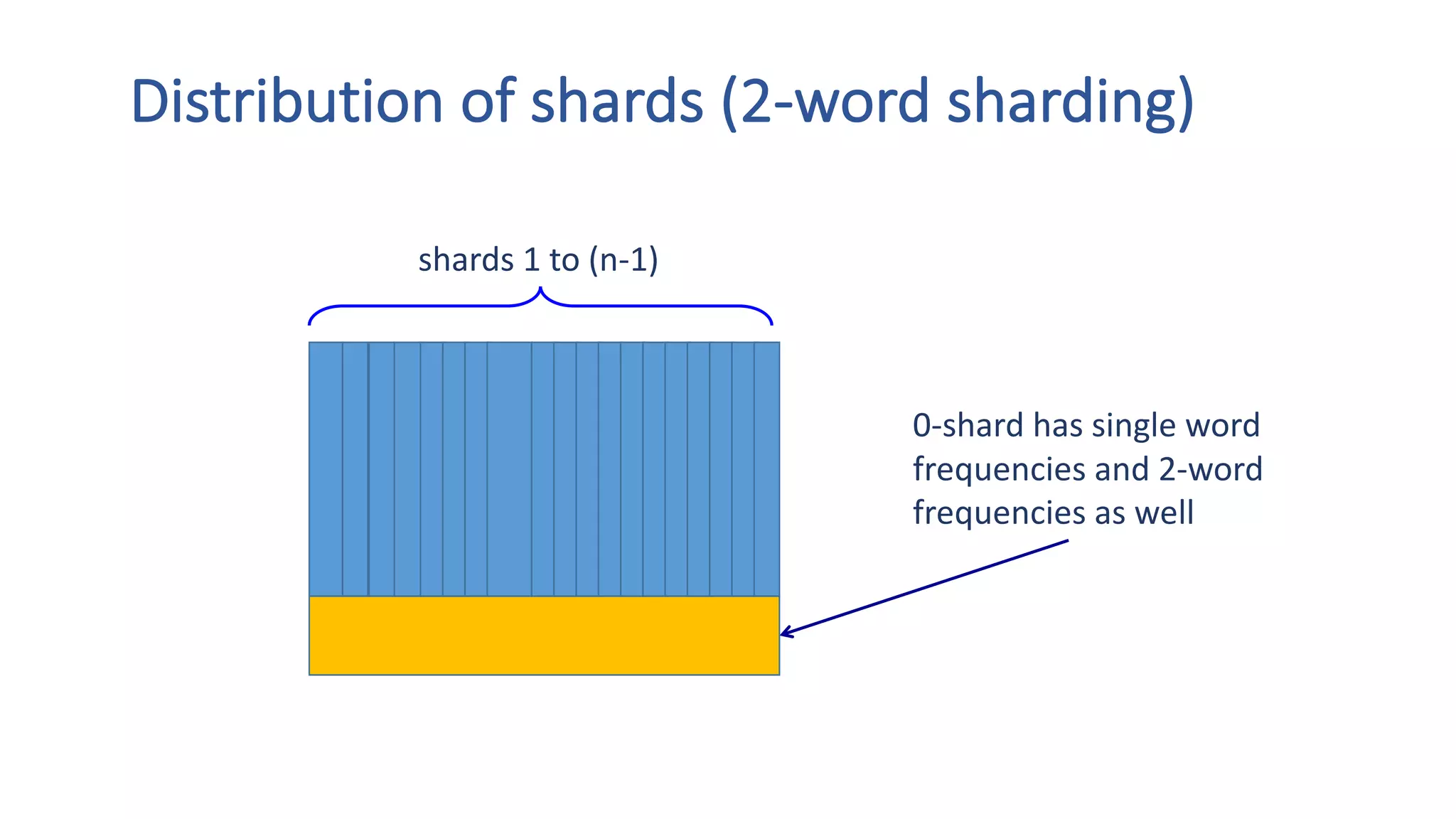
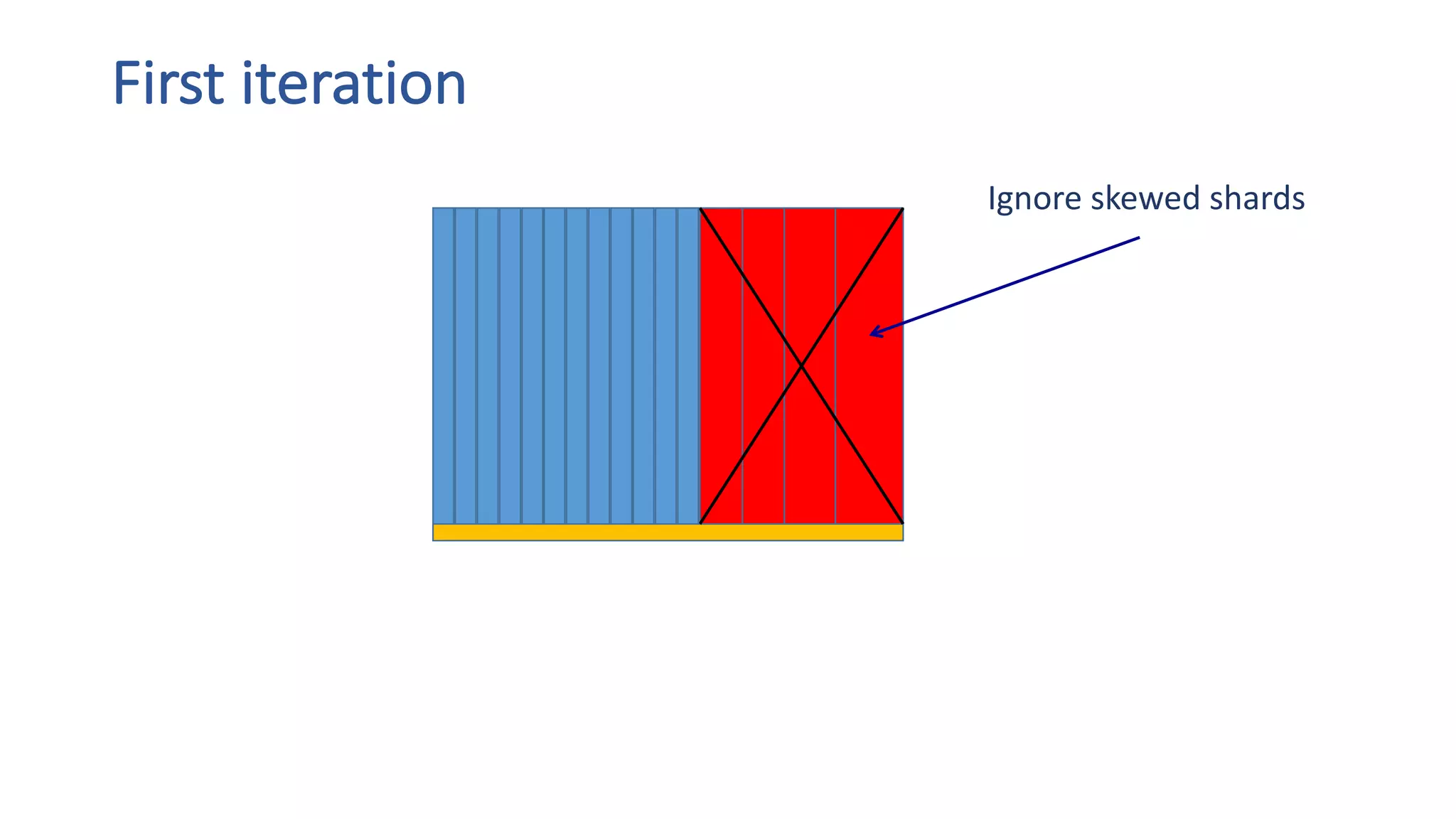
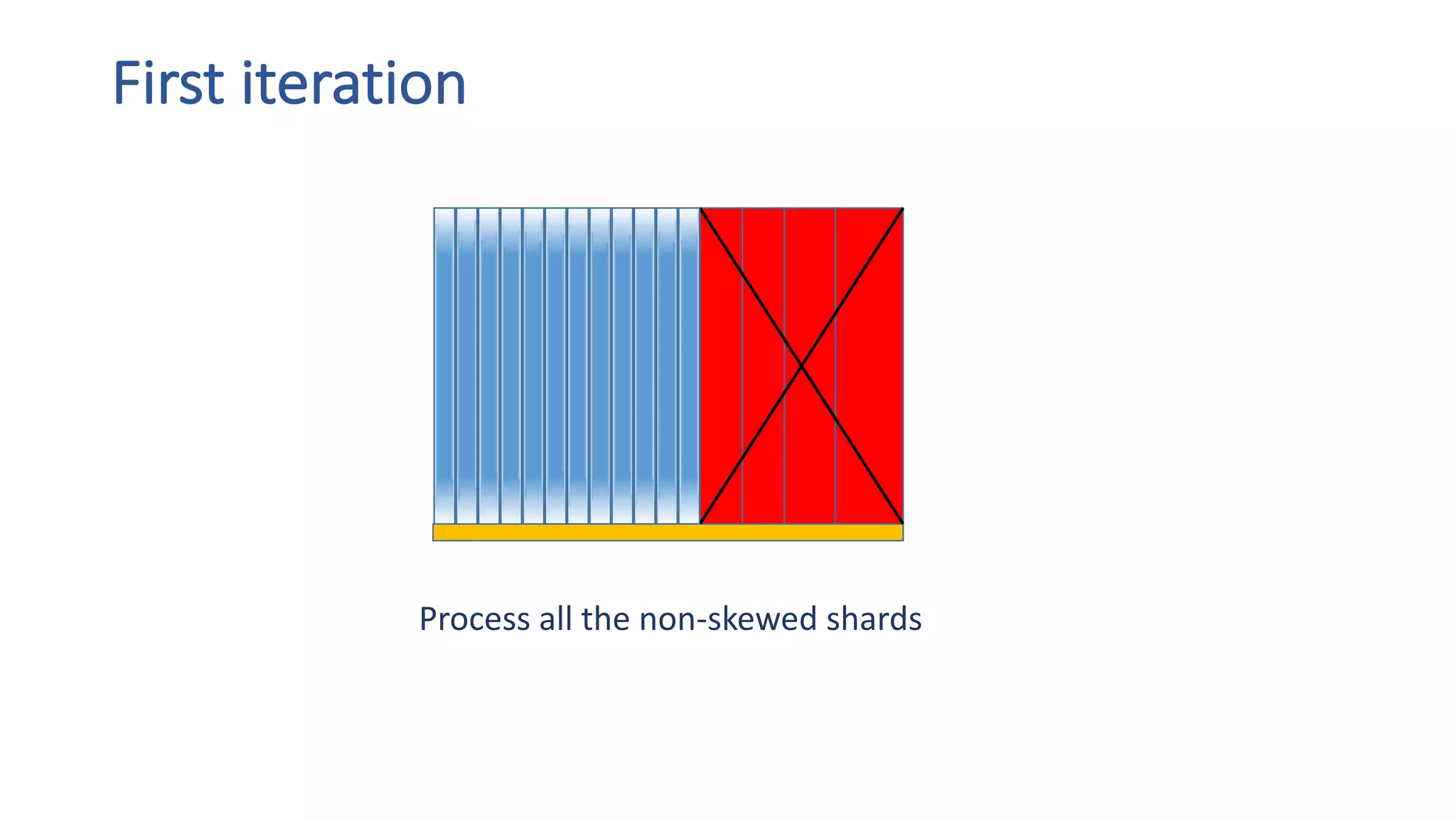
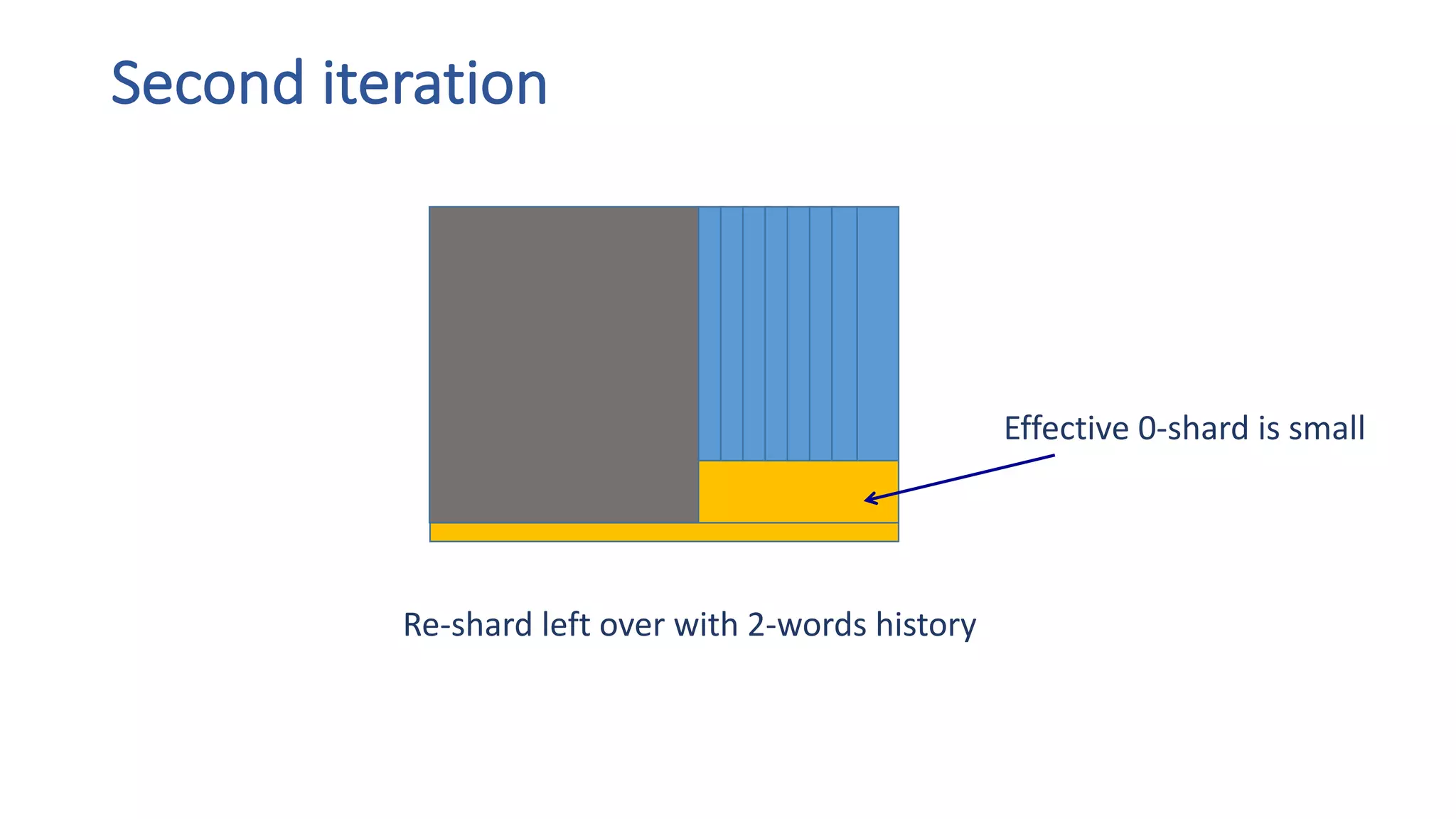
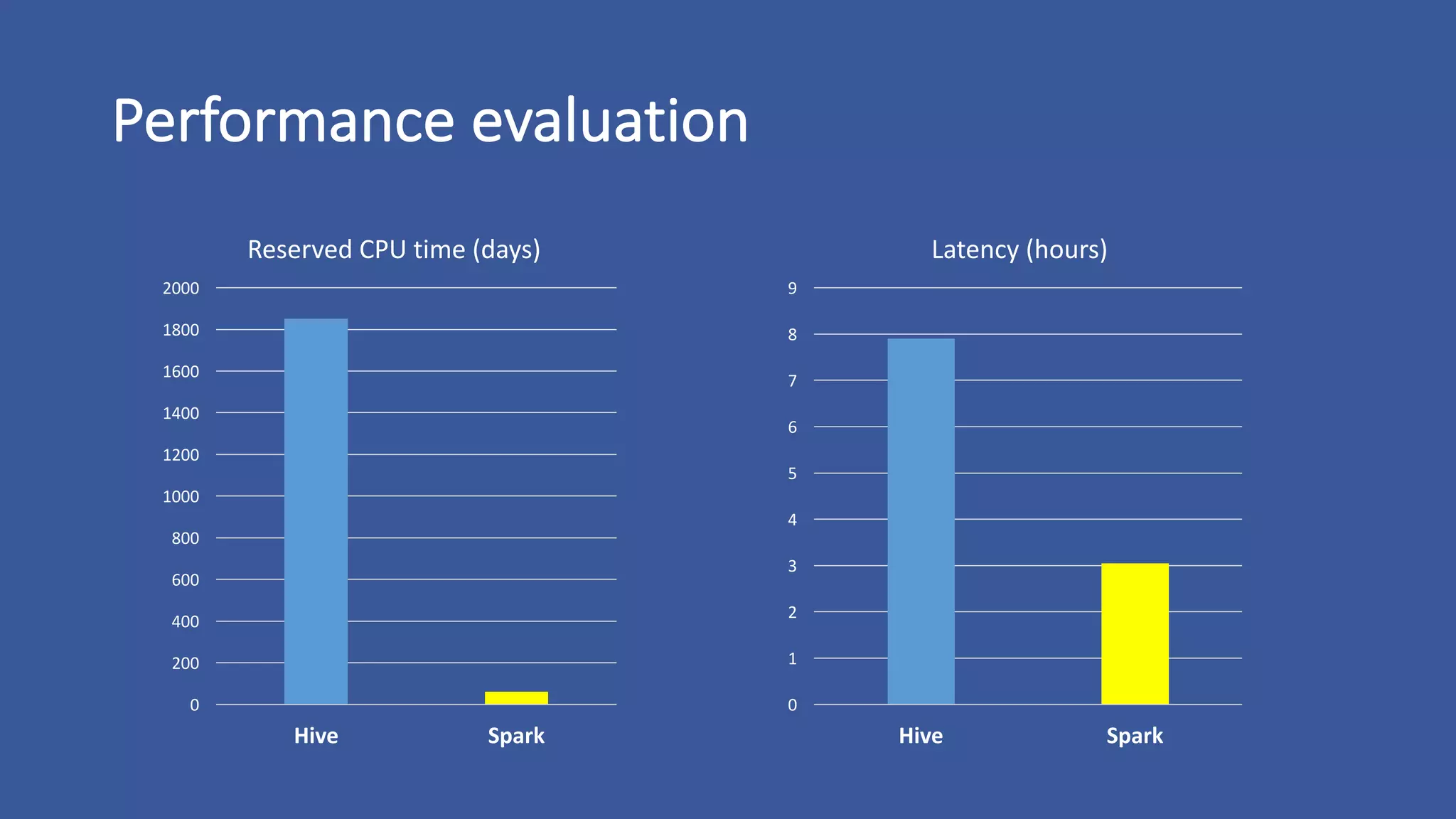
The document discusses the development of custom applications using Spark's RDD, focusing on n-gram language model training for real-world applications such as auto-subtitling and content filtering. It highlights performance issues, scalability challenges, and lessons learned while transitioning from SQL to Spark solutions, emphasizing improvements in modularity and maintainability. The performance evaluation shows a significant increase in efficiency with Spark compared to the previous Hive solution.



















































































![[DSC Europe 25] Nikolay Burlutskiy - Best Practices for Building Enterprise M...](https://cdn.slidesharecdn.com/ss_thumbnails/uirvaiuvq8y1w8hzd9tx-7-251212103249-2619edb4-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Branko Urosevic -Rethinking Financial Talent: Integrating Cod...](https://cdn.slidesharecdn.com/ss_thumbnails/8jjrus8ttko6qj64f58f-3-251212103250-642c6374-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Sara Polak - The Archaeology of Innovation: AI as the Next Cr...](https://cdn.slidesharecdn.com/ss_thumbnails/7ecbscdnt8mlcuqbd2ln-2-sara-polak-ai-creative-industries-251208152533-aa1fcf54-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Branko Dzakula - From Defense to Attack: How AI Redefines Cyb...](https://cdn.slidesharecdn.com/ss_thumbnails/80bdzdxpr3ky2g0qvyk9-8-251211083048-ce5fc1ee-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Milan Zdravkovic - The road less traveled in District Heating...](https://cdn.slidesharecdn.com/ss_thumbnails/nfaboniqwsz4ucyctnmy-2-milan-zdravkovic-dsc2025-the-road-less-traveled-in-district-heating-operation-251208151905-f56388a5-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dusan Nesic - Securing Tomorrow’s Infrastructure: Why Cyber-P...](https://cdn.slidesharecdn.com/ss_thumbnails/qikbszfftyowjm2q6duw-1-251211083848-8f2ead6b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Milan Sekuloski - Data, Defence, and Development: Cybersecuri...](https://cdn.slidesharecdn.com/ss_thumbnails/dfrkwwx4qly6atqpbl4z-4-251209104645-c3d4b0ca-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)

