10
Tesla p100
Most Advanceddata center gpu for
mixed-app hpc
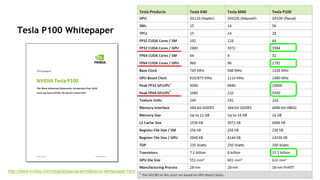
CoWoS with HBM2
PAGE MIGRATION ENGINE
18.7 TF HP ∙ 9.3 TF SP ∙ 4.7 TF DP
New Deep Learning Instructions
More Registers & Cache per SM
Tesla P100 for PCIe-based Servers
PASCAL
Up to 720 GB/Sec Bandwidth
Up to 16 GB Memory Capacity
ECC with Full Performance & Capacity
Simpler Parallel Programming
Virtually Unlimited Data Size
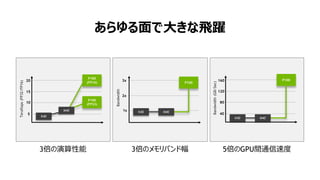
Performance w/ data locality
11.
11
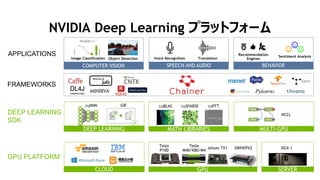
Tesla p100 accelerators
TeslaP100
for NVLink-enabled Servers
Tesla P100
for PCIe-Based Servers
5.3 TF DP ∙ 10.6 TF SP ∙ 21 TF HP
720 GB/sec Memory Bandwidth, 16 GB
4.7 TF DP ∙ 9.3 TF SP ∙ 18.7 TF HP
Config 1: 16 GB, 720 GB/sec
Config 2: 12 GB, 540 GB/sec

















![[GTCJ2018] Optimizing Deep Learning with Chainer PFN得居誠也](https://cdn.slidesharecdn.com/ss_thumbnails/gtcj2018optimizingdeeplearningwithpfnseiyatokui-181009073509-thumbnail.jpg?width=640&height=640&fit=bounds)
![[GTCJ2018]CuPy -NumPy互換GPUライブラリによるPythonでの高速計算- PFN奥田遼介](https://cdn.slidesharecdn.com/ss_thumbnails/gtcj2018cupypfnryosukeokuta-181009073034-thumbnail.jpg?width=640&height=640&fit=bounds)














































![[db analytics showcase Sapporo 2017] B14: GPU コンピューティング最前線 by エヌビディア 佐々木邦暢](https://cdn.slidesharecdn.com/ss_thumbnails/20170630dbassprnvidia-170707074715-thumbnail.jpg?width=640&height=640&fit=bounds)






































