参考資料
• GTC JAPAN2015
• 1011:ヤフー音声認識サービス「YJVOICE」におけるディープラーニング
活用事例
• https://youtu.be/PzyV7cPe5bk
• ICASSP 2016 : Plenary talk
(http://2016.ieeeicassp.org/PlenarySpeakers.asp)
• Li Deng - Microsoft Research
“Deep Learning for AI: From Machine Perception to Machine
Cognition”
• http://2016.ieeeicassp.org/SP16_PlenaryDeng_Slides.pdf
29
30.
参考資料
• Baidu Research: Deep Speech 2
Amodei, Dario, et al. "Deep speech 2: End-to-end speech recognition in
english and mandarin." Proceedings of The 33rd International Conference
on Machine Learning, pp. 173–182, 2016.
• http://jmlr.org/proceedings/papers/v48/amodei16.html
• https://arxiv.org/abs/1512.02595
30
31.
参考資料
• Theano :multi GPU
• https://github.com/Theano/Theano/wiki/Using-Multiple-GPUs
• https://github.com/uoguelph-mlrg/theano_multi_gpu
• Using multiple GPUs — Theano 0.8.2 documentation
• http://deeplearning.net/software/theano/tutorial/using_multi_gpu.html
• Chainer User Group
• Free memory of cupy.ndarray - Google グループ
• https://groups.google.com/d/msg/chainer/E5ygPRt-hD8/YHIz7FHbBQAJ
• ミニバッチ学習でのデータシャッフルの方法 (GPUを使って学習する場合) - Google
グループ
• https://groups.google.com/d/msg/chainer/ZNyjR2Czo1c/uNVeHuTXAwAJ
31
32.
参考資料
• Baidu Research: Persistent RNNs
Diamos, Gregory, et al. "Persistent RNNs: Stashing Recurrent Weights On-Chip."
Proceedings of The 33rd International Conference on Machine Learning, pp. 2024–2033,
2016.
• https://svail.github.io/persistent_rnns/
• http://jmlr.org/proceedings/papers/v48/diamos16.html
• https://github.com/baidu-research/persistent-rnn
• Microsoft : 1bit-SGD
Seide, Frank, et al. "1-bit stochastic gradient descent and its application to data-parallel
distributed training of speech DNNs." INTERSPEECH. 2014.
• https://www.microsoft.com/en-us/research/publication/1-bit-stochastic-
gradient-descent-and-application-to-data-parallel-distributed-training-of-
speech-dnns/
• http://www.isca-speech.org/archive/interspeech_2014/i14_1058.html
32





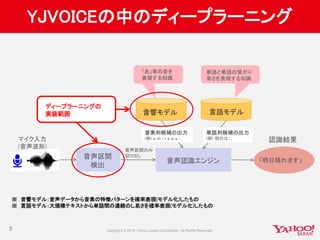

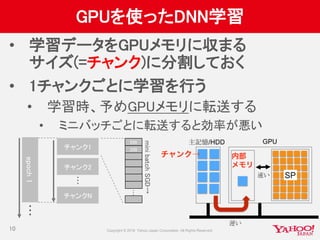




![ChainerでマルチGPU試行錯誤 その2
GPUに送ったチャンクデータ(cupy.ndarray)からVariableを
作成しようとするとエラー
• 原因:cupy.ndarrayにx[1,9,5]のようなアクセスができない
• どうやらcupyが未対応だった(v1.6)
• チュートリアルのインデックスをシャッフルするやり方をそのまま
使用していた
• 対応:GPUに送る前に学習データtrain_x, train_y(numpy)に同じシャッフルをし
ておく
• numpy.random.get_state()/numpy.random.set_state()
• こちらもフォーラムに情報あり
17](https://image.slidesharecdn.com/20160702cm3-yj-yjvoice-160714092952/85/GPU-17-320.jpg)
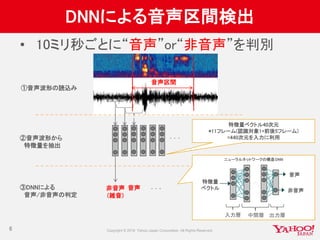
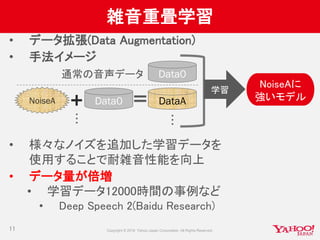
![マルチGPU結果(1)
1GPUの場合より遅
い
• モデルパラメータの
同期がボトルネック
• ミニバッチサイズを
大きくすることで改
善
→同期回数を減少
18
0
50
100
150
200
250
single-512
multi-256
single-1024
multi-512
single-2048
multi-1024
single-4096
multi-2048
512 1024 2048 4096
[sec]
synctime calctime
Theano, TITAN X *2,1024x5
0
50
100
150
200
250
300
350
400
single-512
multi-256
single-1024
multi-512
single-2048
multi-1024
single-4096
multi-2048
512 1024 2048 4096
Chainer, M2090*2,1024x4
ERROR](https://image.slidesharecdn.com/20160702cm3-yj-yjvoice-160714092952/85/GPU-18-320.jpg)
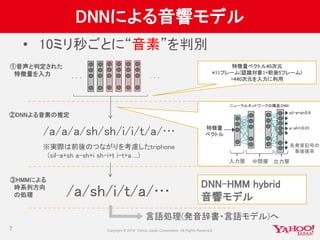
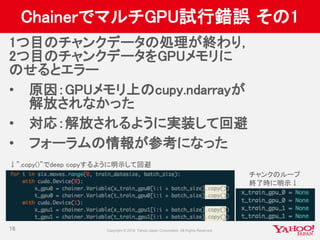
![マルチGPU結果(2)
実験2: ミニバッチサイズとマルチGPUによる速度変化
19
• TheanoとTensorFlow(TITAN X*4, 同期SGD)を比較
• MAX:ミニバッチサイズ64倍&GPU*4で処理速度約4.7倍
• (まだまだ改良中:データ転送の効率化でもう少し高速化できそう)
• 注:初期バッチサイズと同等の精度が出ない
• 適切な学習率や初期値などのパラメータ探索が必要
74.2
23.7
25.9
15.8
0
10
20
30
40
50
60
70
80
256(x1) 16384(x64) 16384(x64) 16384(x64)
1GPU 1GPU 4GPU
Theano TensorFlow
1sampleあたりの処理時間[usec]
3.1倍 1.6倍](https://image.slidesharecdn.com/20160702cm3-yj-yjvoice-160714092952/85/GPU-19-320.jpg)

































































![[Whisper論文紹介]Robust Speech Recognition via Large-Scale Weak Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/whisper-250612044133-e22fcae0-thumbnail.jpg?width=640&height=640&fit=bounds)




































