Downloaded 5,394 times




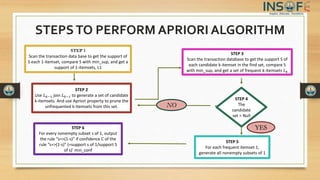


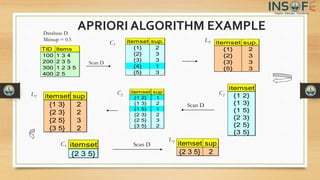







The document discusses the Apriori algorithm, which is used for mining frequent itemsets from transactional databases. It begins with an overview and definition of the Apriori algorithm and its key concepts like frequent itemsets, the Apriori property, and join operations. It then outlines the steps of the Apriori algorithm, provides an example using a market basket database, and includes pseudocode. The document also discusses limitations of the algorithm and methods to improve its efficiency, as well as advantages and disadvantages.



































































































