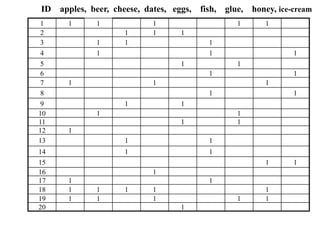
The document discusses the Apriori algorithm for finding frequent itemsets in transactional data. The Apriori algorithm works in two phases:
1. It finds all frequent itemsets of length 1 by scanning the transaction database. It then generates candidate itemsets of length k from frequent itemsets of length k-1, and tests them against the database to determine which are frequent.
2. It uses the found frequent itemsets to generate association rules between items. The confidence and support of each rule is calculated to determine how interesting it is.
The algorithm efficiently finds all rules and itemsets that meet a minimum support threshold by generating candidates in a way that prunes subsets that cannot be frequent. This allows