Download as PDF, PPTX









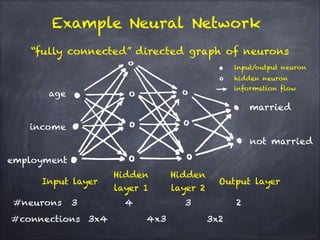
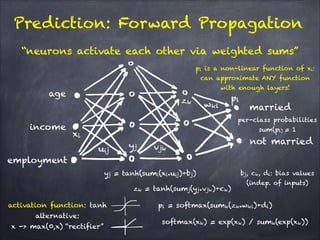
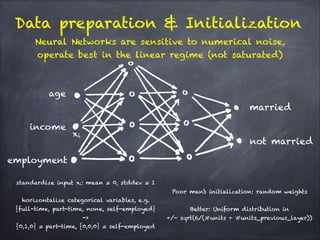

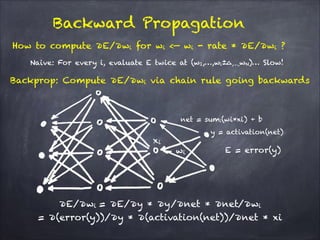
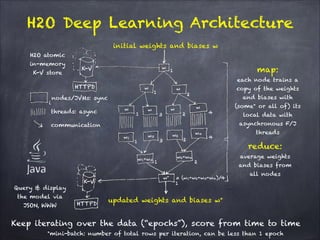


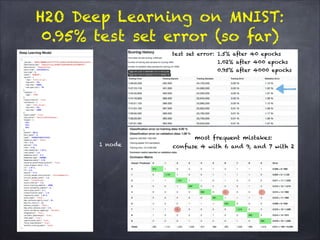

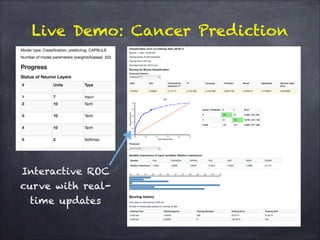
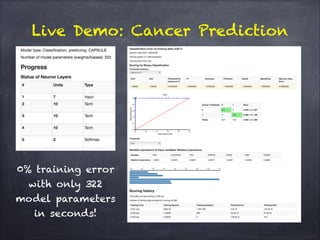






The document discusses H2O.ai's deep learning platform, highlighting its scalable in-memory machine learning capabilities and various applications, such as handwritten digit classification and cancer prediction. It emphasizes the architecture of H2O's deep learning model, the use of distributed processing for speed, and techniques like stochastic gradient descent and regularization to enhance prediction accuracy. Additionally, it offers practical tips for leveraging H2O’s features to optimize model performance in machine learning tasks.






















































![Deep learning in python ommunic [CNN].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearninginpythoncnn-251207084743-a5c807e1-thumbnail.jpg?width=640&height=640&fit=bounds)




















































