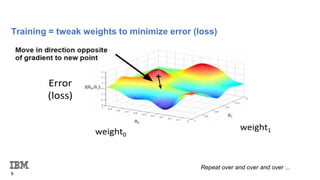
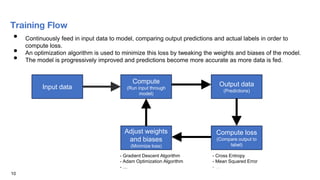
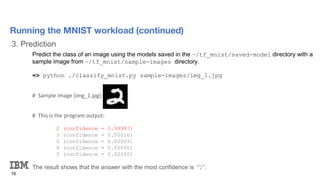
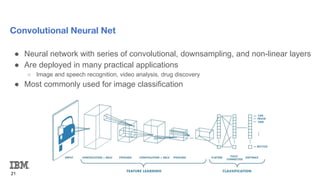
The document provides an overview and agenda for an introduction to running AI workloads on PowerAI. It discusses PowerAI and how it combines popular deep learning frameworks, development tools, and accelerated IBM Power servers. It then demonstrates AI workloads using TensorFlow and PyTorch, including running an MNIST workload to classify handwritten digits using basic linear regression and convolutional neural networks in TensorFlow, and an introduction to PyTorch concepts like tensors, modules, and softmax cross entropy loss.









![Implement Placeholders
18
• Placeholders are input
• x is a 2D array for the images:
• Each row is one flattened 28x28 image
• First dimension is “None”, to be used to pull in a batch of images at a time
(more later)
• y_ is 2D array for the labels:
• Second dimension 10 for the one-hot representation
# Placeholder that will be fed image data.
x = tf.placeholder(tf.float32, [None, 784])
# Placeholder that will be fed the correct labels.
y_ = tf.placeholder(tf.float32, [None, 10])](https://image.slidesharecdn.com/openpowerworkshop20190316cathey-190506085537/85/OpenPOWER-Workshop-in-Silicon-Valley-18-320.jpg)
![Implement Weight and Bias
19
• Weight and Bias are variables: to be tweaked during training
• Weight is a 2D array: 784 x 10
• Bias is a vector: 10
• Initialized with certain values: important for optimization algorithm
def weight_variable(shape):
"""Generates a weight variable of a given shape."""
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
"""Generates a bias variable of a given shape."""
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
# Define weight and bias.
W = weight_variable([784, 10])
b = bias_variable([10])](https://image.slidesharecdn.com/openpowerworkshop20190316cathey-190506085537/85/OpenPOWER-Workshop-in-Silicon-Valley-19-320.jpg)
![Implement Regression and Loss Optimizer
20
• Neural network: Regression + SoftMax
• Loss function: how far off is the prediction from the label
• Optimizer algorithm: how to tweak the variables
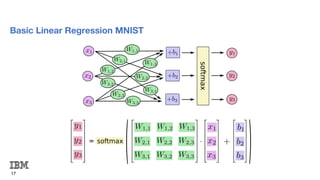
# Here we define our model which utilizes the softmax regression.
y = tf.nn.softmax(tf.matmul(x, W) + b)
# Define our loss.
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y), reduction_indices=[1]))
# Define our optimizer.
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)](https://image.slidesharecdn.com/openpowerworkshop20190316cathey-190506085537/85/OpenPOWER-Workshop-in-Silicon-Valley-20-320.jpg)













![[Update] PyTorch Tutorial for NTU Machine Learing Course 2017](https://cdn.slidesharecdn.com/ss_thumbnails/pytorchtutorial-2017-1103-171103060015-thumbnail.jpg?width=640&height=640&fit=bounds)











![[PR12] PR-036 Learning to Remember Rare Events](https://cdn.slidesharecdn.com/ss_thumbnails/pr12pr-036learningtoremeberrareevents-170917140144-thumbnail.jpg?width=640&height=640&fit=bounds)








![Deep learning in python ommunic [CNN].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearninginpythoncnn-251207084743-a5c807e1-thumbnail.jpg?width=640&height=640&fit=bounds)




















































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)





