Downloaded 16 times














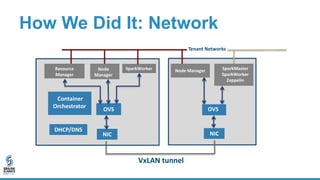




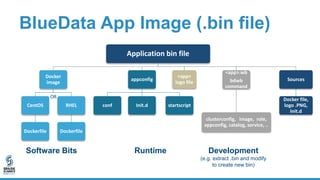


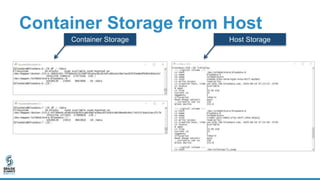

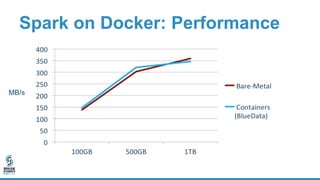
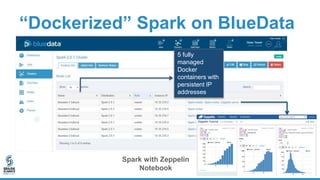

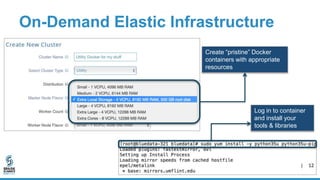






The document discusses lessons learned from dockerizing Spark workloads, emphasizing the benefits of using Docker containers for agility, portability, and efficient resource utilization in multi-tenant environments. It outlines various challenges, including network and storage complexities, and highlights best practices for security and configuration management. Key takeaways stress the importance of deploying enterprise-ready solutions and suggest that while DIY efforts can be time-consuming, platforms like Bluedata offer streamlined solutions.























































































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)
















