Download as PDF, PPTX



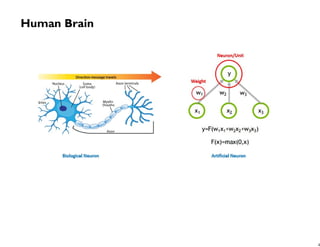




















The document discusses the advancements in machine learning and deep learning, emphasizing the significance of neural networks in classifying data through forward and backward propagation processes. It highlights the benefits and weaknesses of deep learning, including its scalability and requirement for large datasets. Additionally, it mentions the applications of deep learning using the H2O library and references the MNIST handwritten digits dataset for practical implementation.















































































