Downloaded 111 times





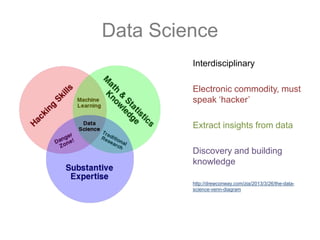








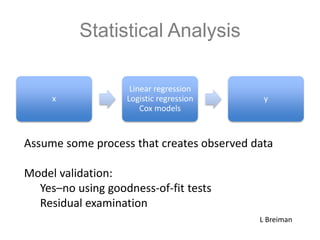
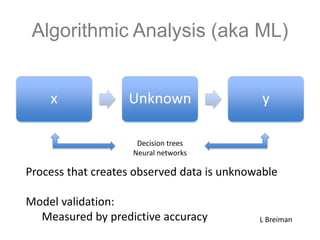

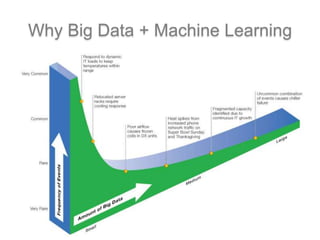


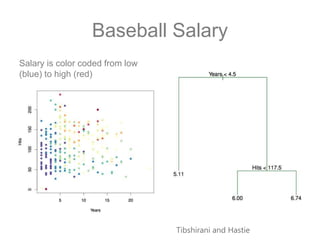
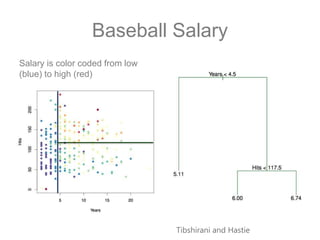


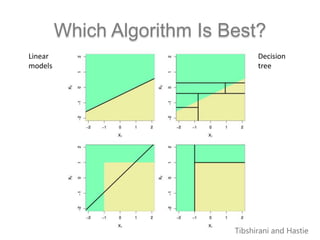




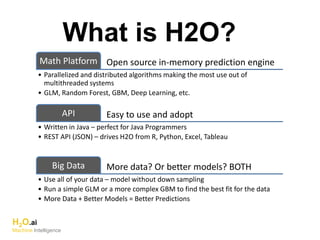





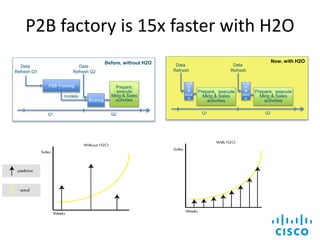


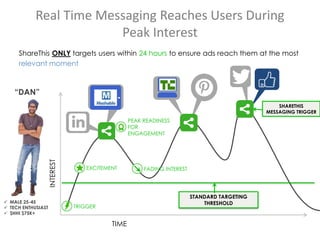
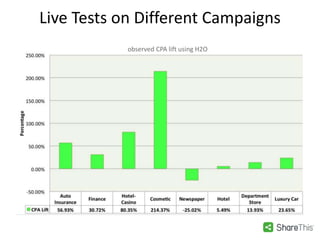



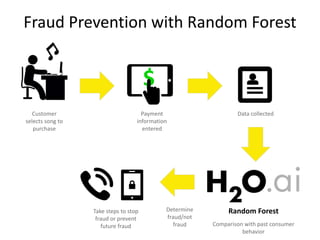




The document discusses scalable machine learning, focusing on algorithmic methods such as decision trees and their applications using the H2O machine learning engine. It highlights the importance of data science in extracting insights and improving predictions through various models, including random forests and gradient boosting. Furthermore, it showcases real-world use cases demonstrating H2O's effectiveness in ad optimization, fraud detection, and predictive modeling for companies.



































































































![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)







