Download as PDF, PPTX












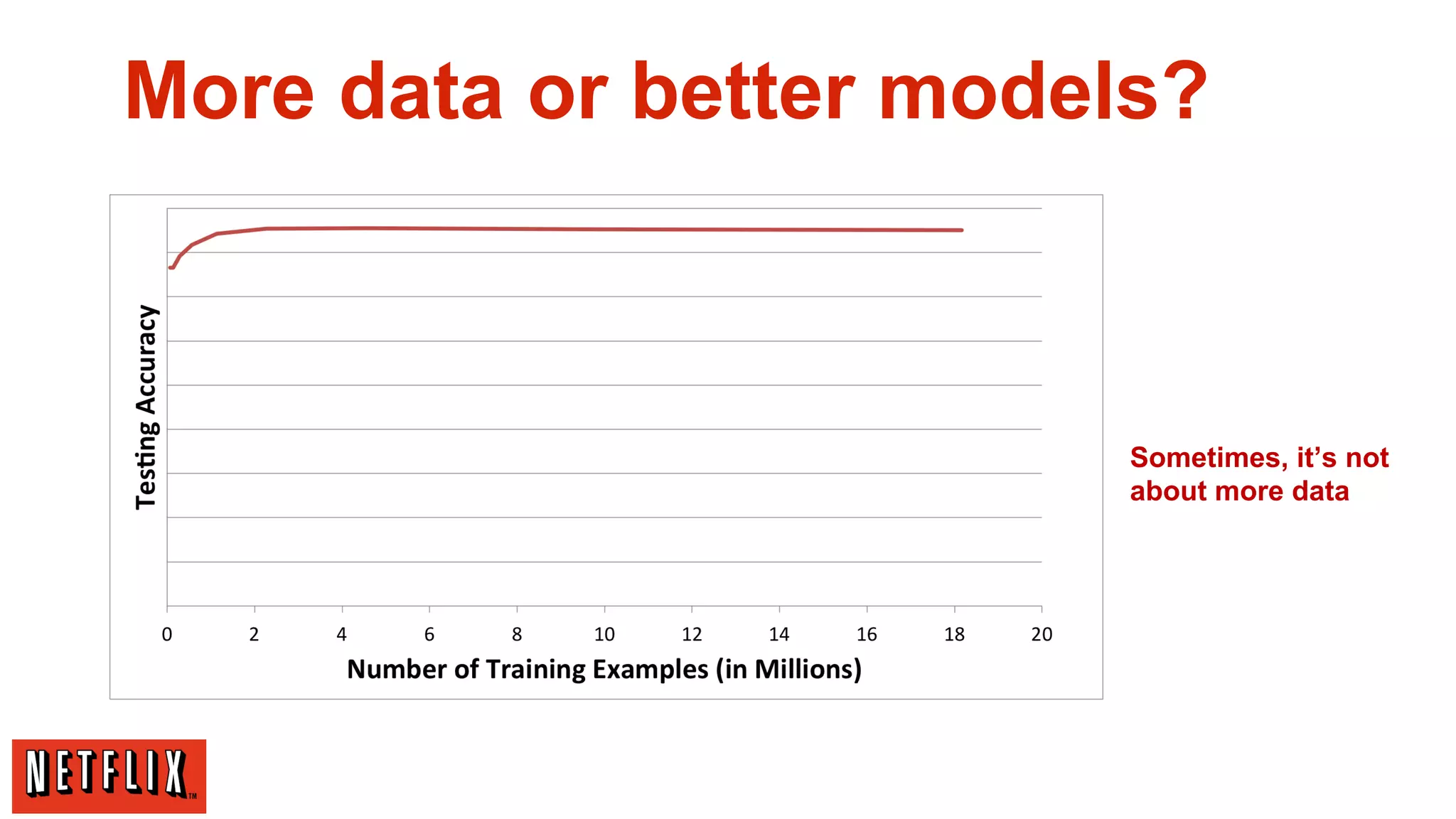
![More data or better models?
[Banko and Brill, 2001]
Norvig: “Google does not
have better Algorithms,
only more Data”
Many features/
low-bias models](https://image.slidesharecdn.com/qcon-xavier-131118142118-phpapp01/75/Qcon-SF-2013-Machine-Learning-Recommender-Systems-Netflix-Scale-23-2048.jpg)



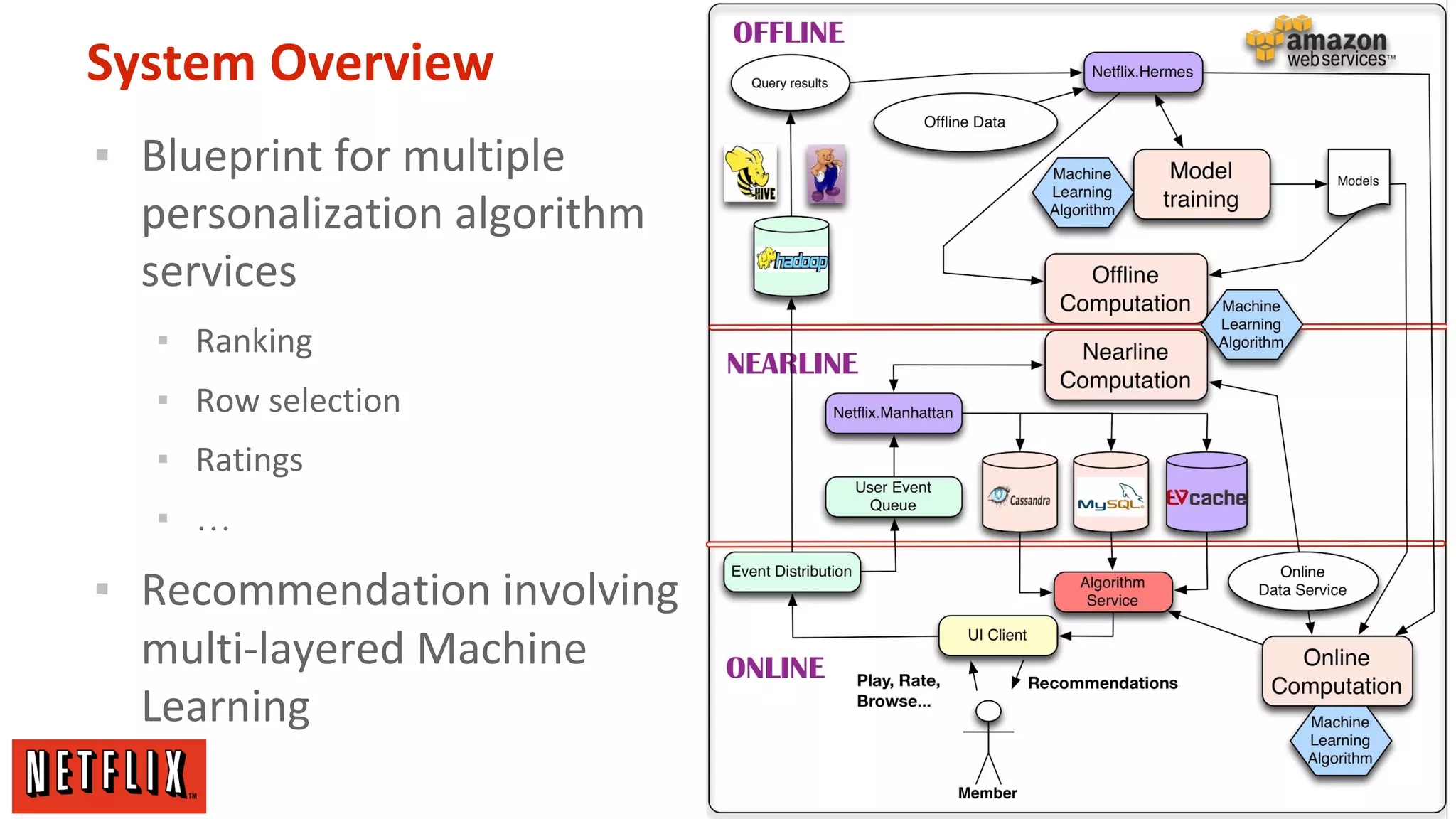
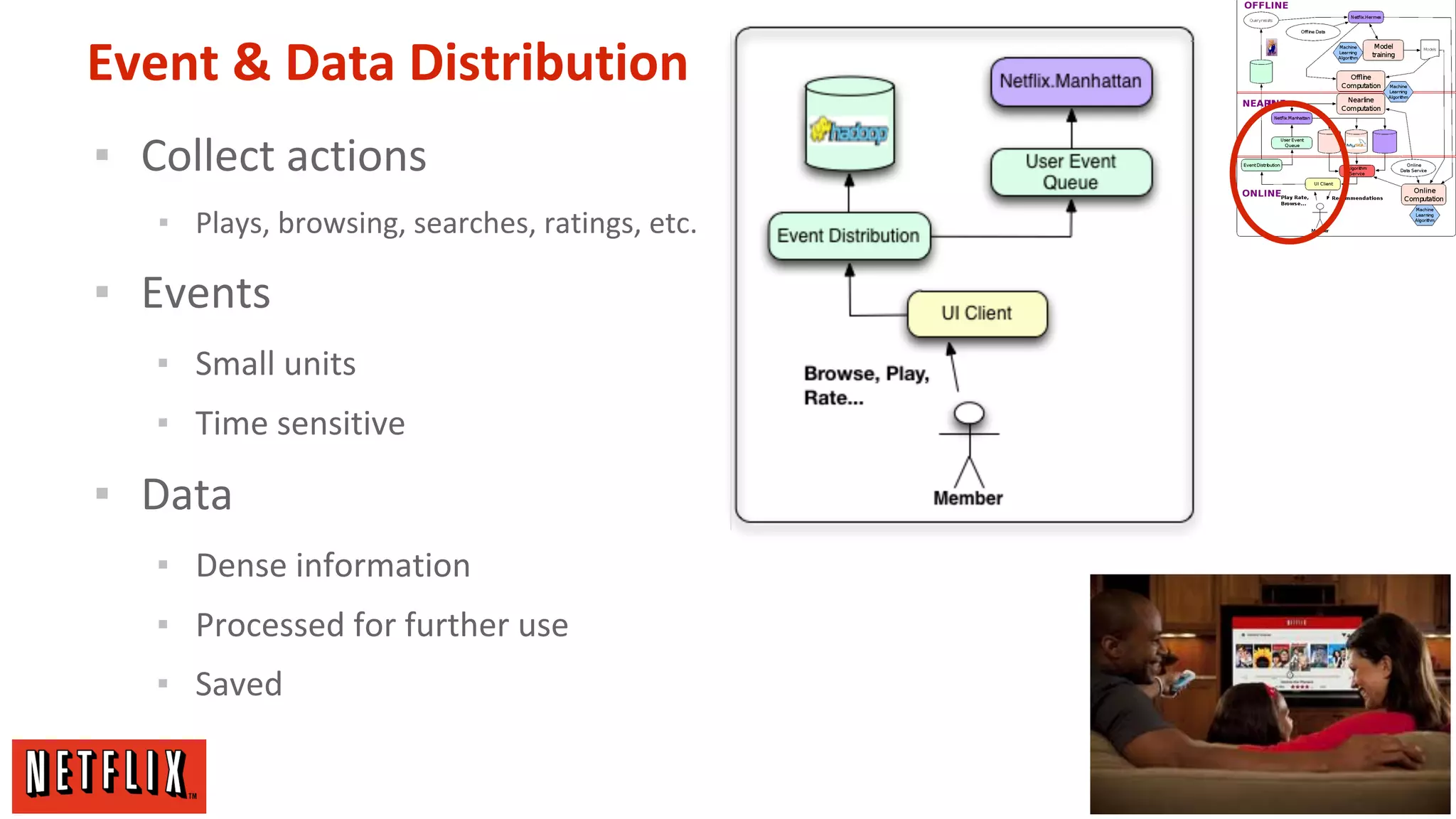
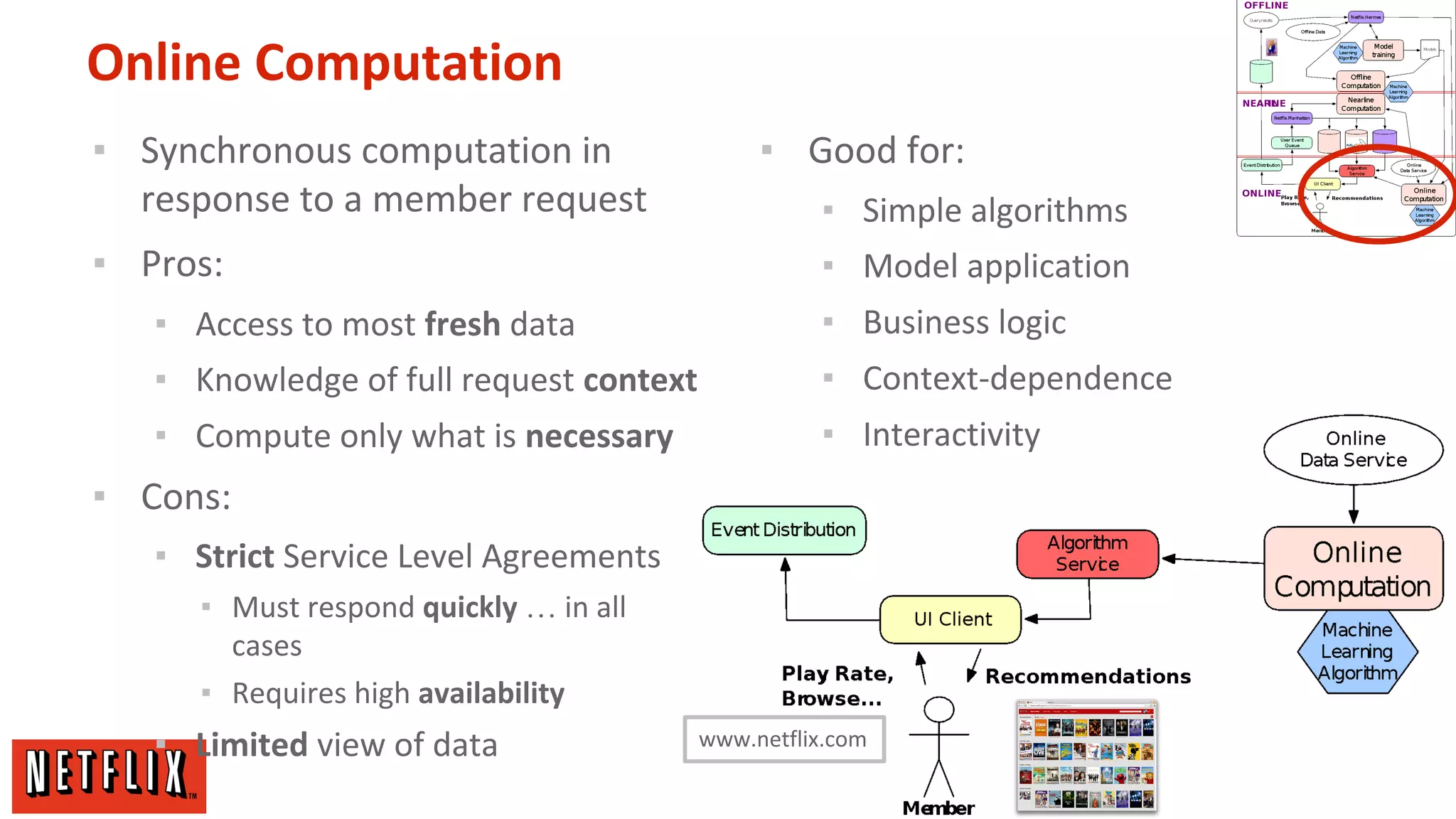
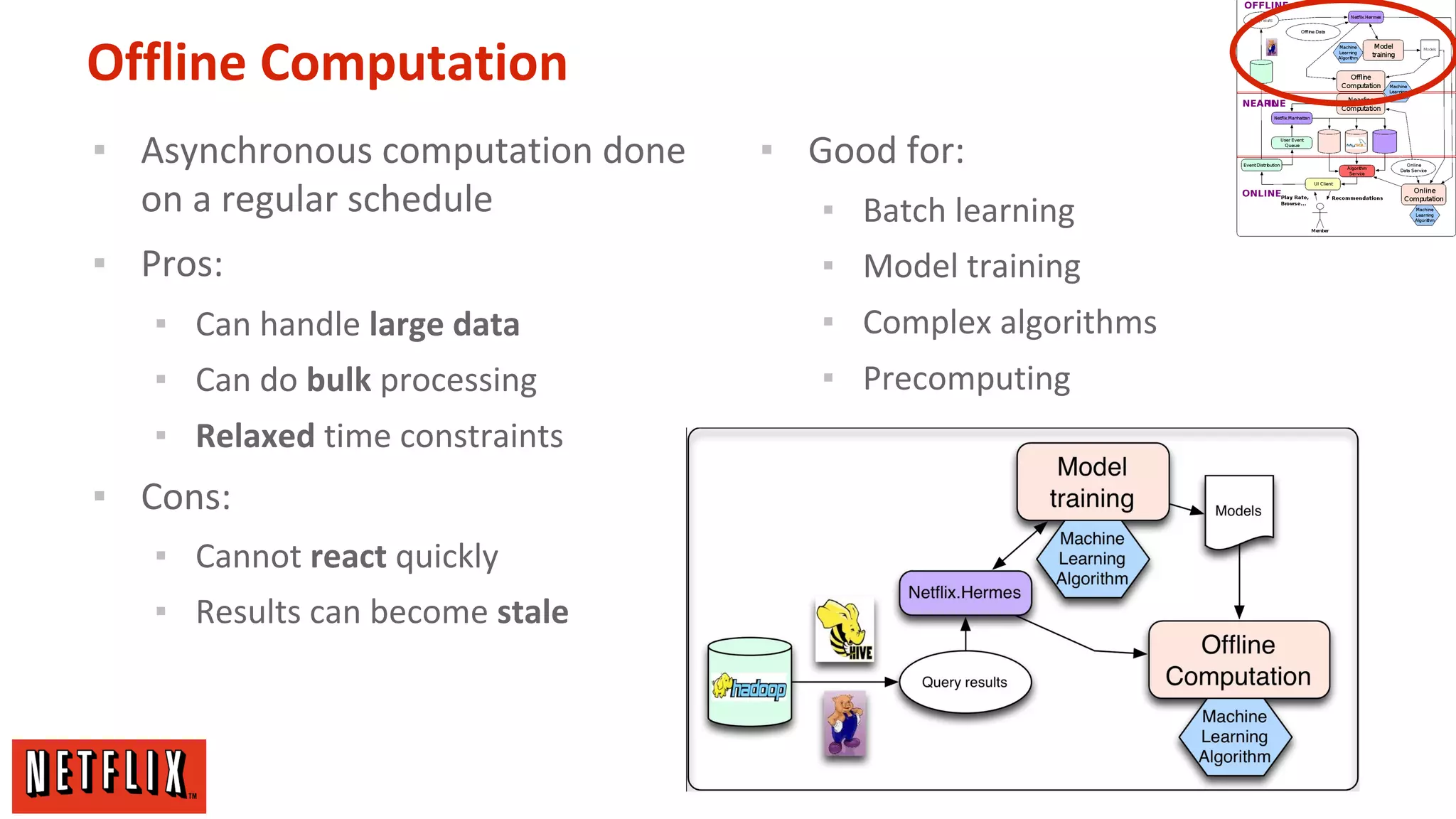
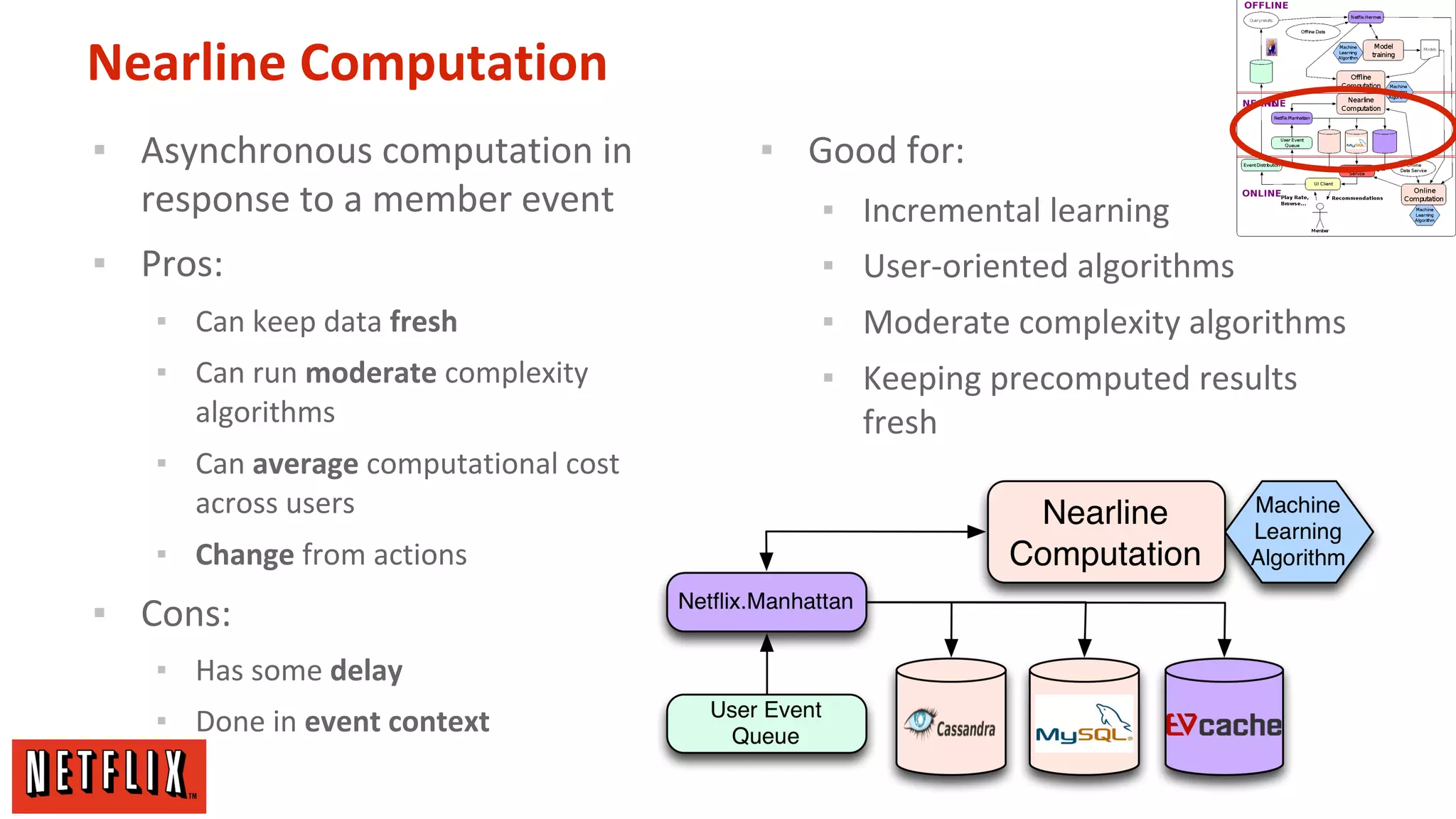
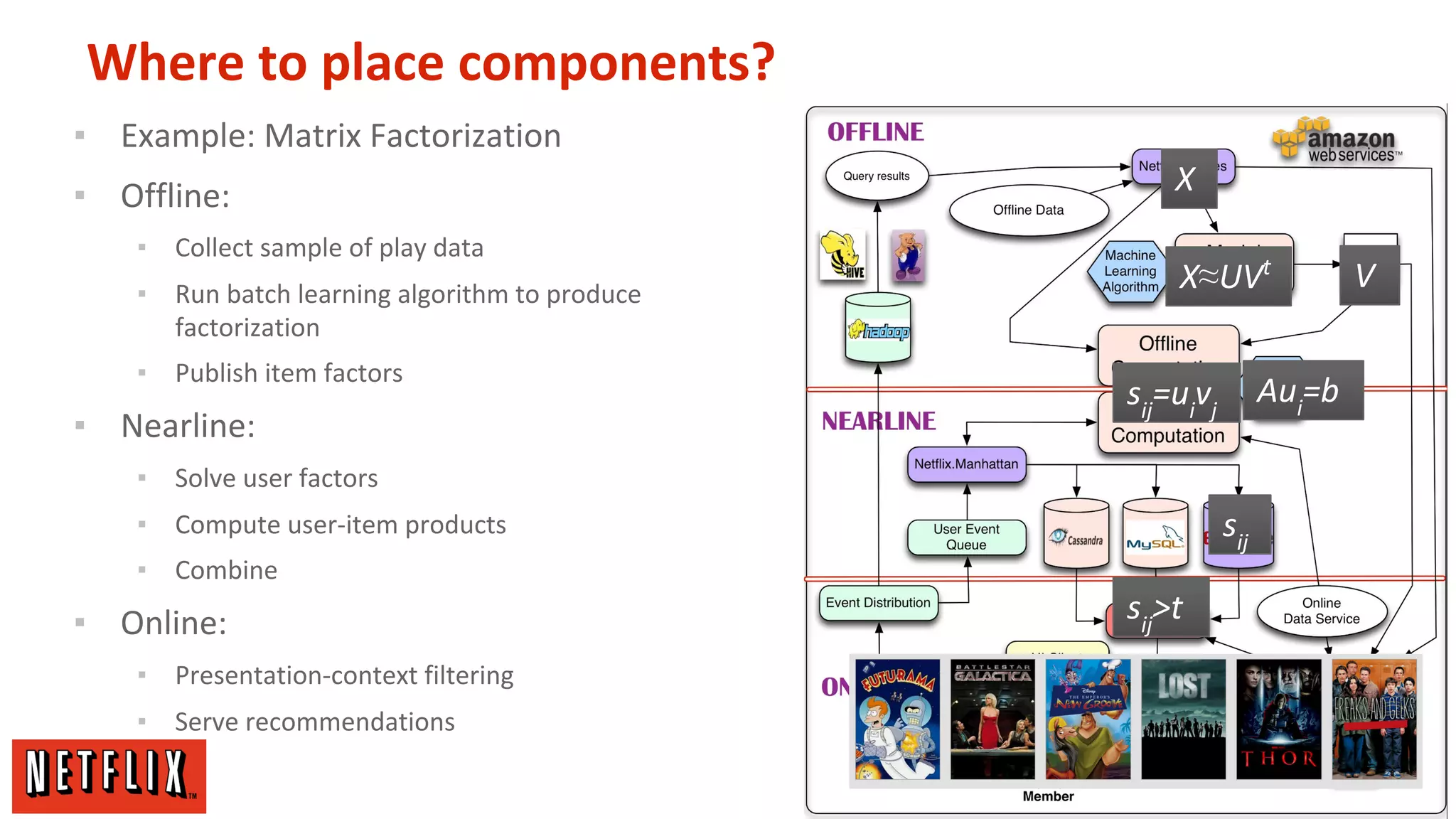
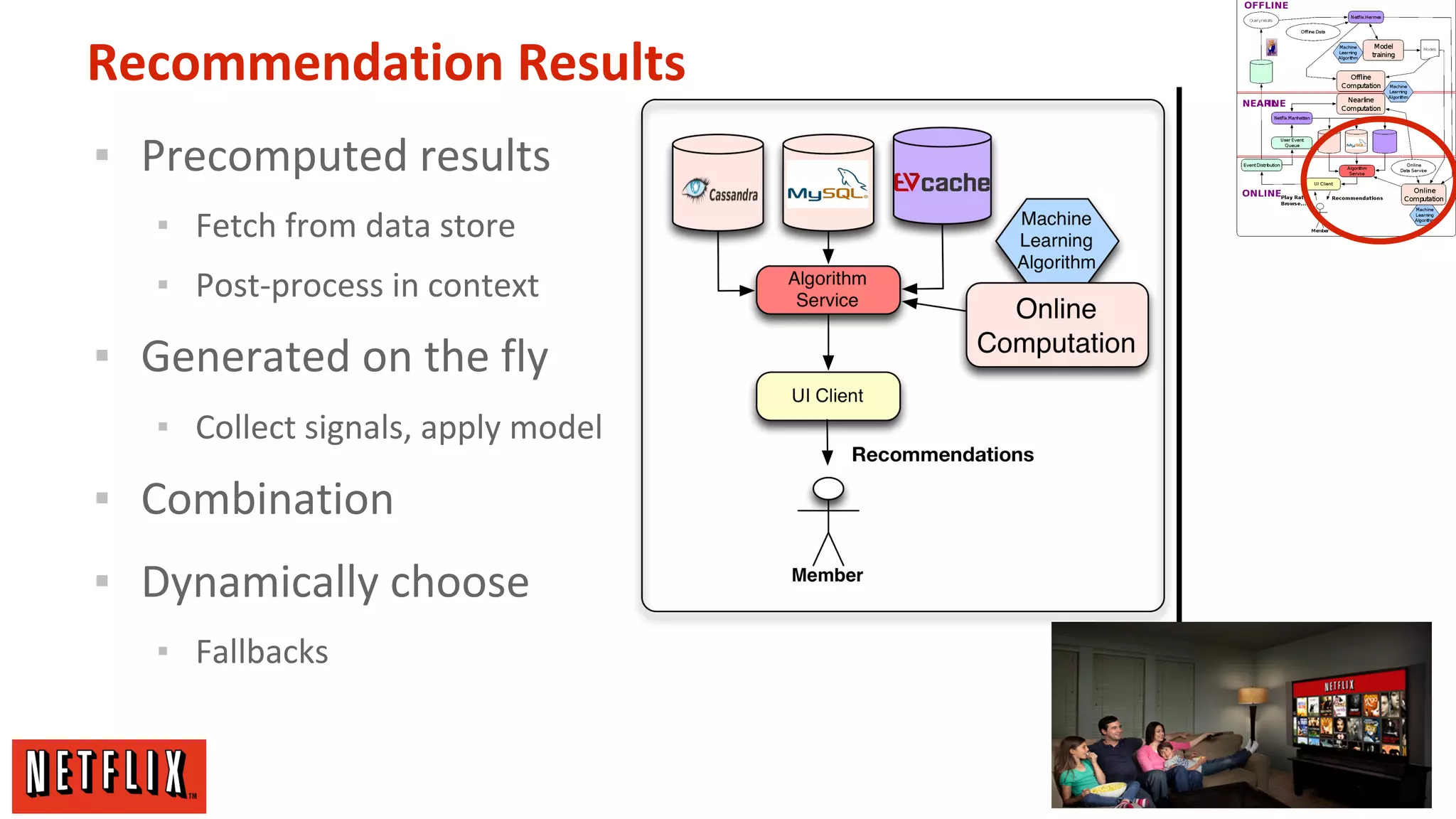




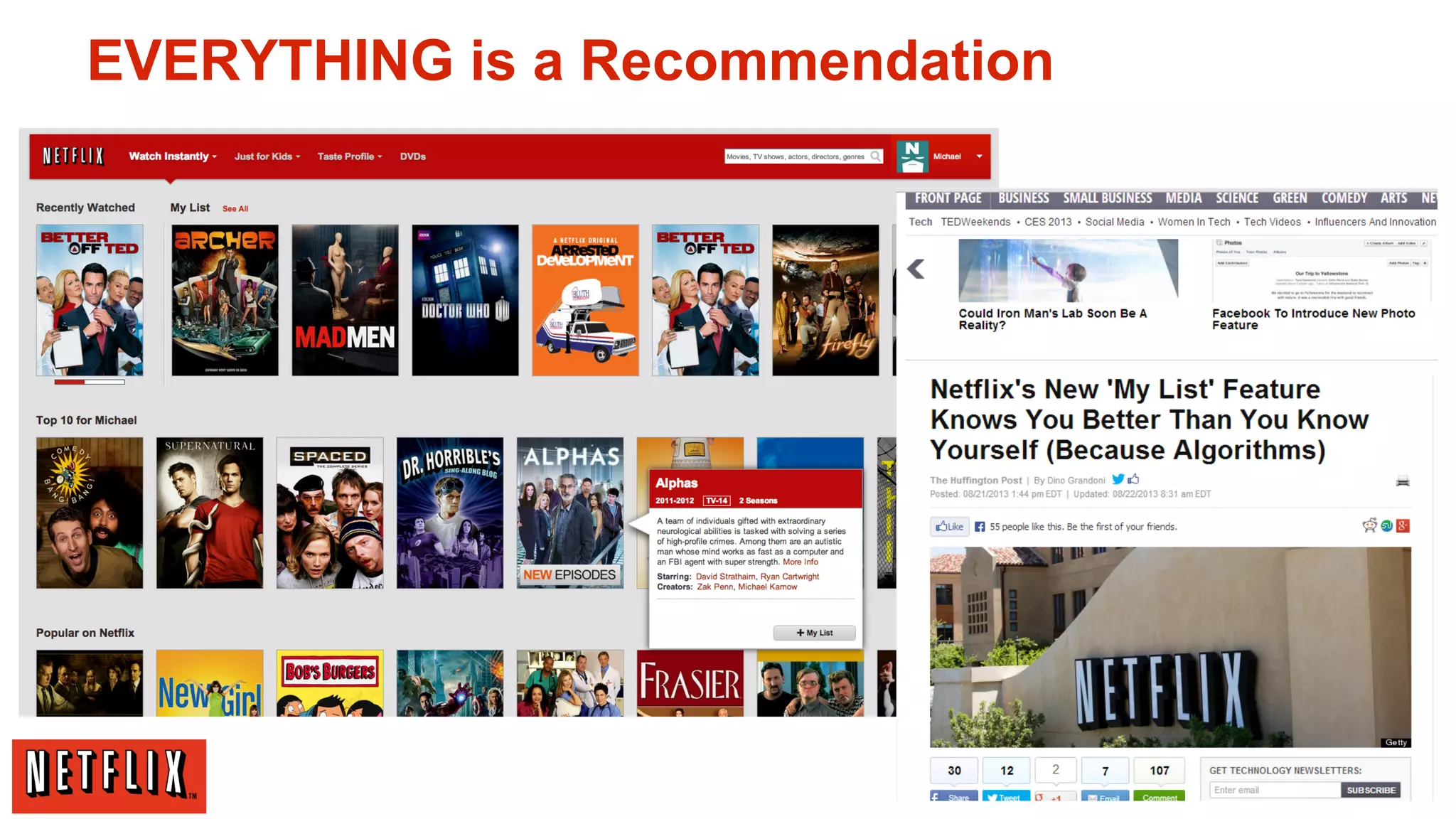
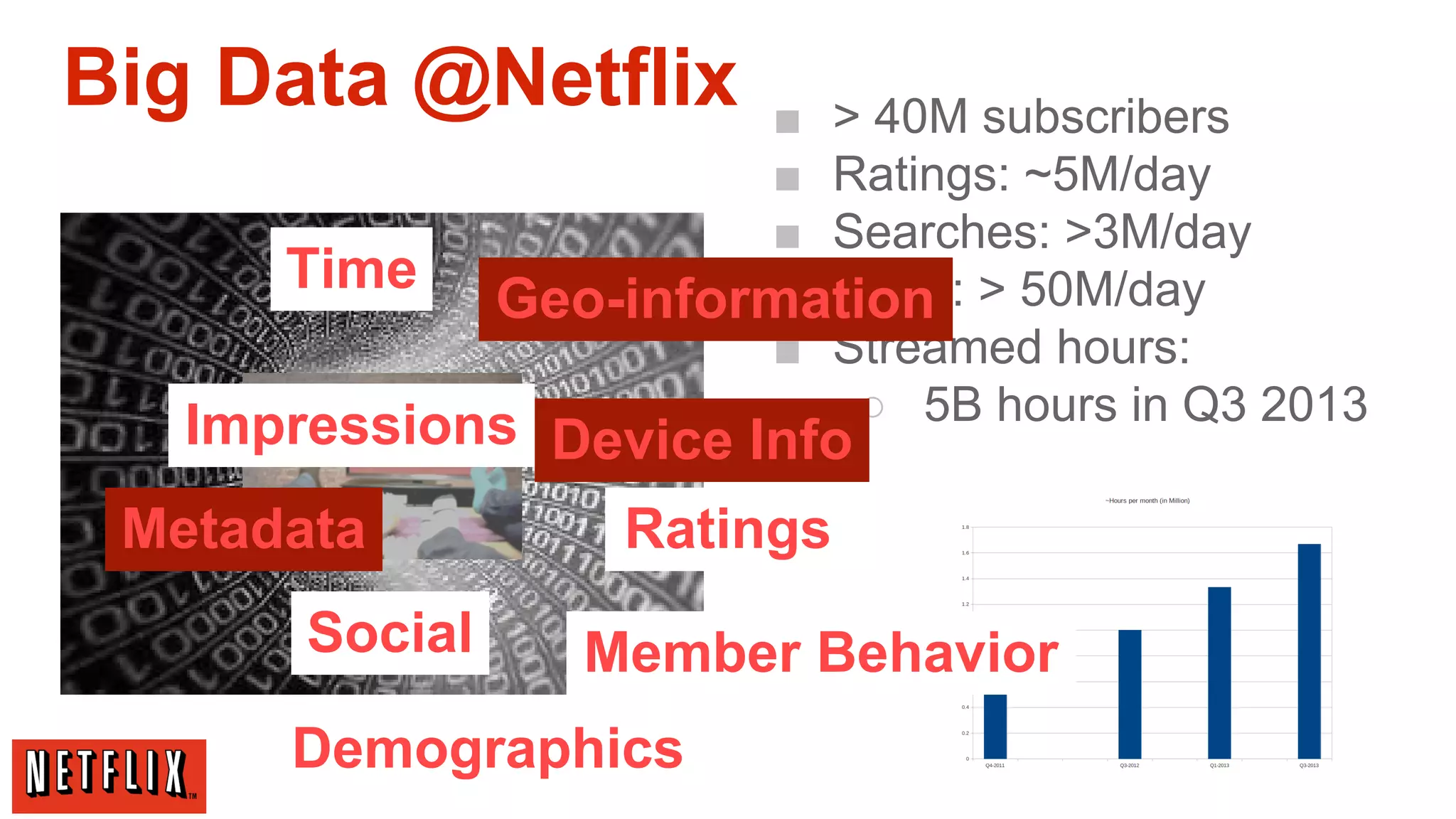
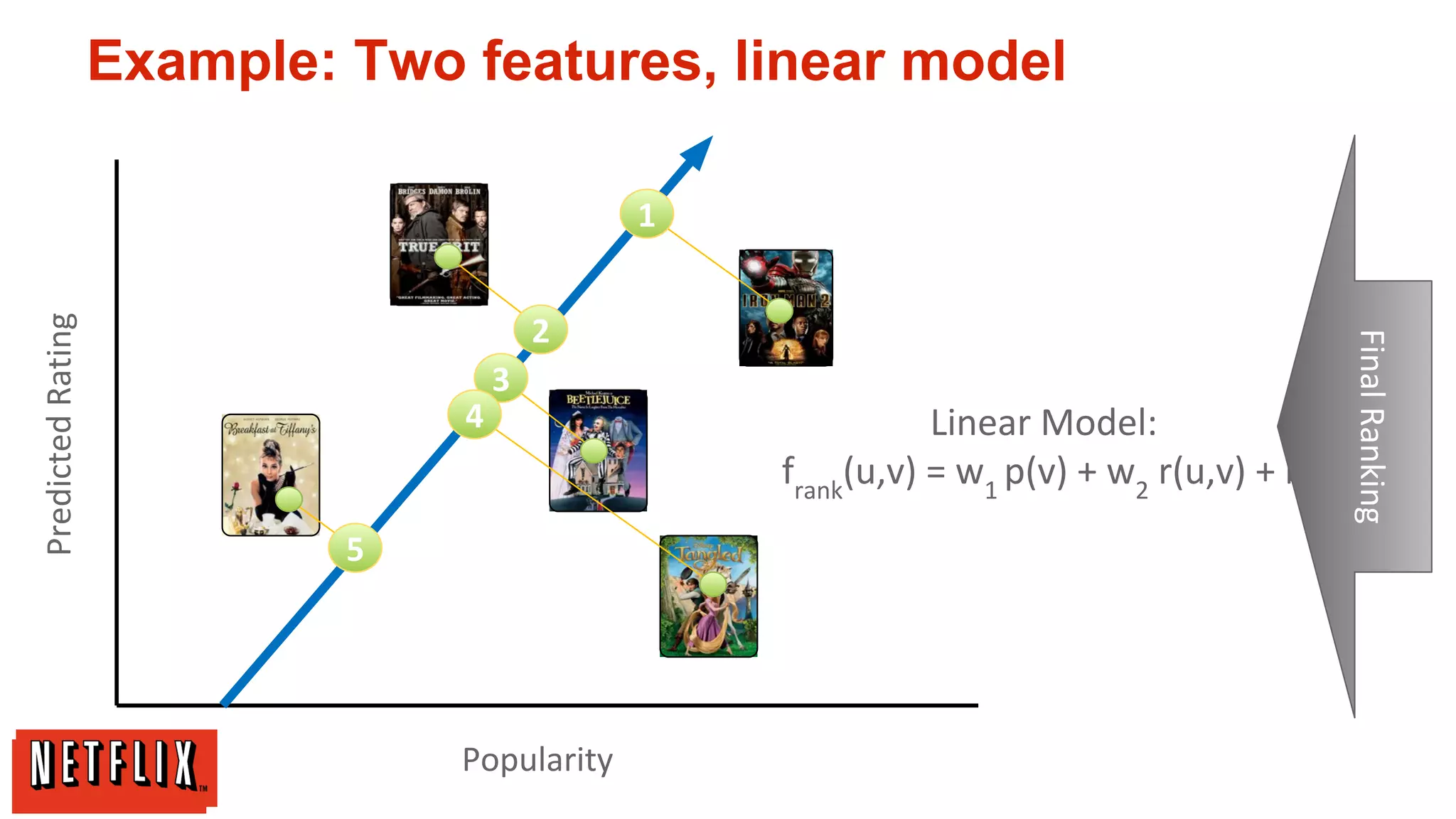
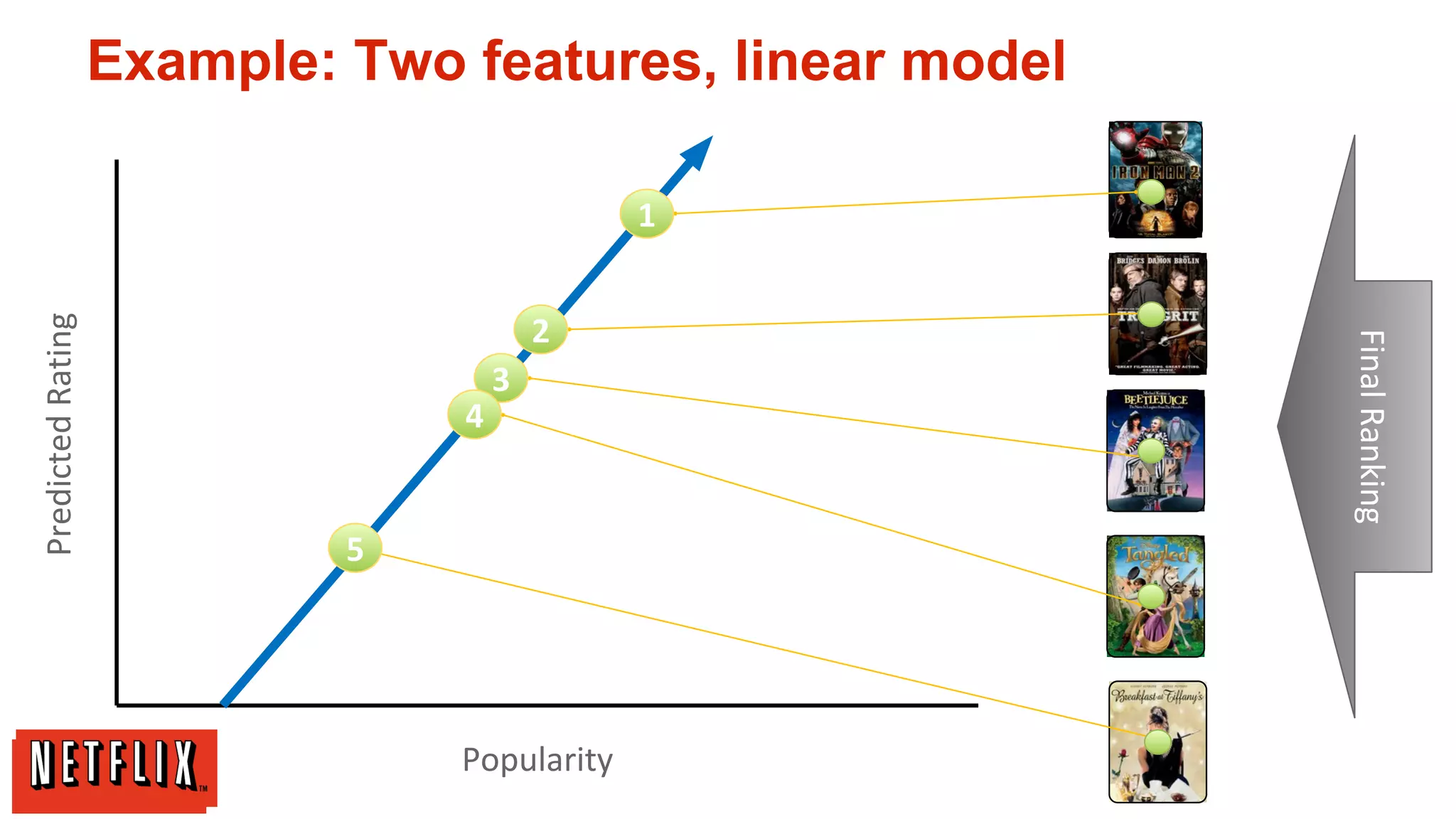
The document summarizes Netflix's approach to machine learning and recommender systems. It discusses how Netflix uses algorithms like SVD and Restricted Boltzmann Machines on a massive scale to power highly personalized recommendations. Over 75% of what people watch on Netflix comes from recommendations. Netflix collects a huge amount of data from over 40 million subscribers and uses both offline, online, and nearline computation across cloud services to train models and power recommendations in real-time at scale. The key is combining more data, smarter models, accurate metrics, and optimized system architectures.






















































































