Download as PDF, PPTX








![SVD - Definition
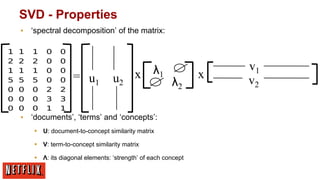
A[n x m] = U[n x r] Λ [ r x r] (V[m x r])T
▪
A: n x m matrix (e.g., n documents, m terms)
▪
U: n x r matrix (n documents, r concepts)
▪
▪
Λ: r x r diagonal matrix (strength of each ‘concept’) (r:
rank of the matrix)
V: m x r matrix (m terms, r concepts)](https://image.slidesharecdn.com/xavieramatriaindiralgorithmsnetflixmlconf2013-131119174850-phpapp02/85/Xavier-amatriain-dir-algorithms-netflix-m-lconf-2013-10-320.jpg)





















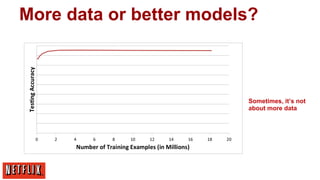
![More data or better models?
[Banko and Brill, 2001]
Norvig: “Google does not
have better Algorithms,
only more Data”
Many features/
low-bias models](https://image.slidesharecdn.com/xavieramatriaindiralgorithmsnetflixmlconf2013-131119174850-phpapp02/85/Xavier-amatriain-dir-algorithms-netflix-m-lconf-2013-42-320.jpg)





The document discusses Netflix's approach to item recommendations through machine learning algorithms, particularly highlighting the use of matrix factorization and various models such as SVD, RBM, and clustering techniques. It emphasizes the importance of ranking, similarity measures, and the trade-off between data quantity and model sophistication. Key insights include the evolution of recommendation systems, challenges in scaling algorithms, and the ongoing pursuit of better metrics and system architectures.























































































