Downloaded 672 times






























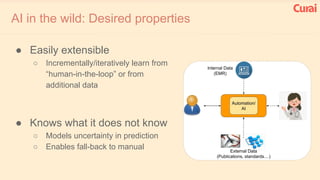


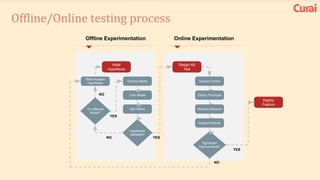

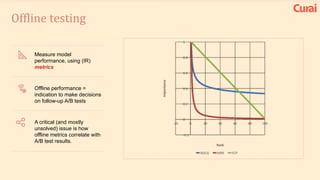













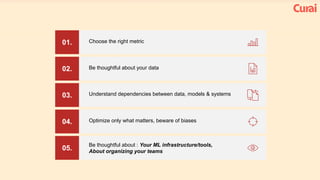


1. There are many lessons to be learned from building practical deep learning systems, including choosing the right evaluation metrics, being thoughtful about your data and potential biases, and understanding dependencies between data, models, and systems. 2. It is important to optimize only what matters and beware of biases in your data. Simple models are often better than complex ones, and feature engineering is crucial. 3. Both supervised and unsupervised learning are important, and ensembles often perform best. Your AI infrastructure needs to support both experimentation and production.






















































































