Download as PDF, PPTX




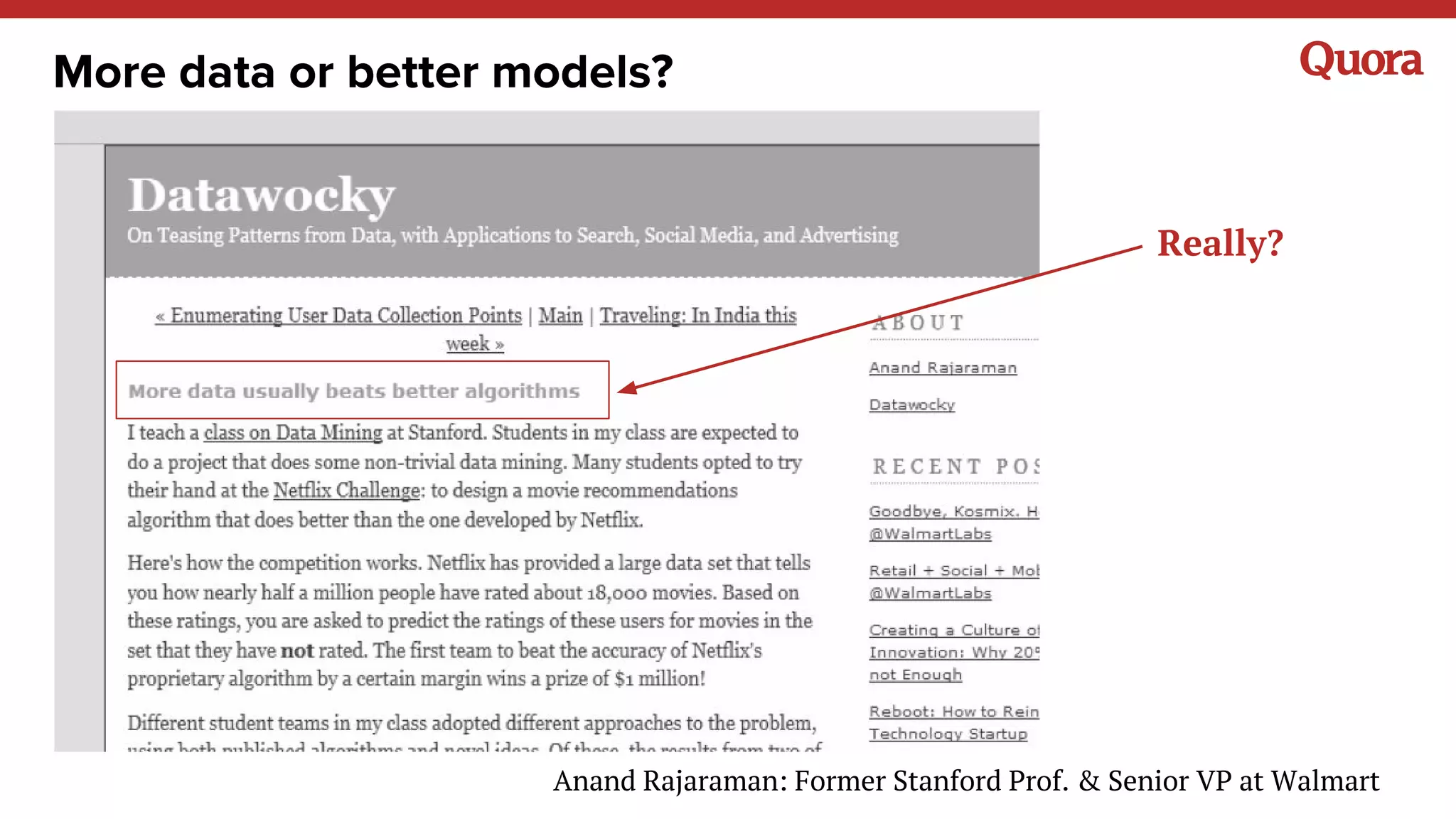

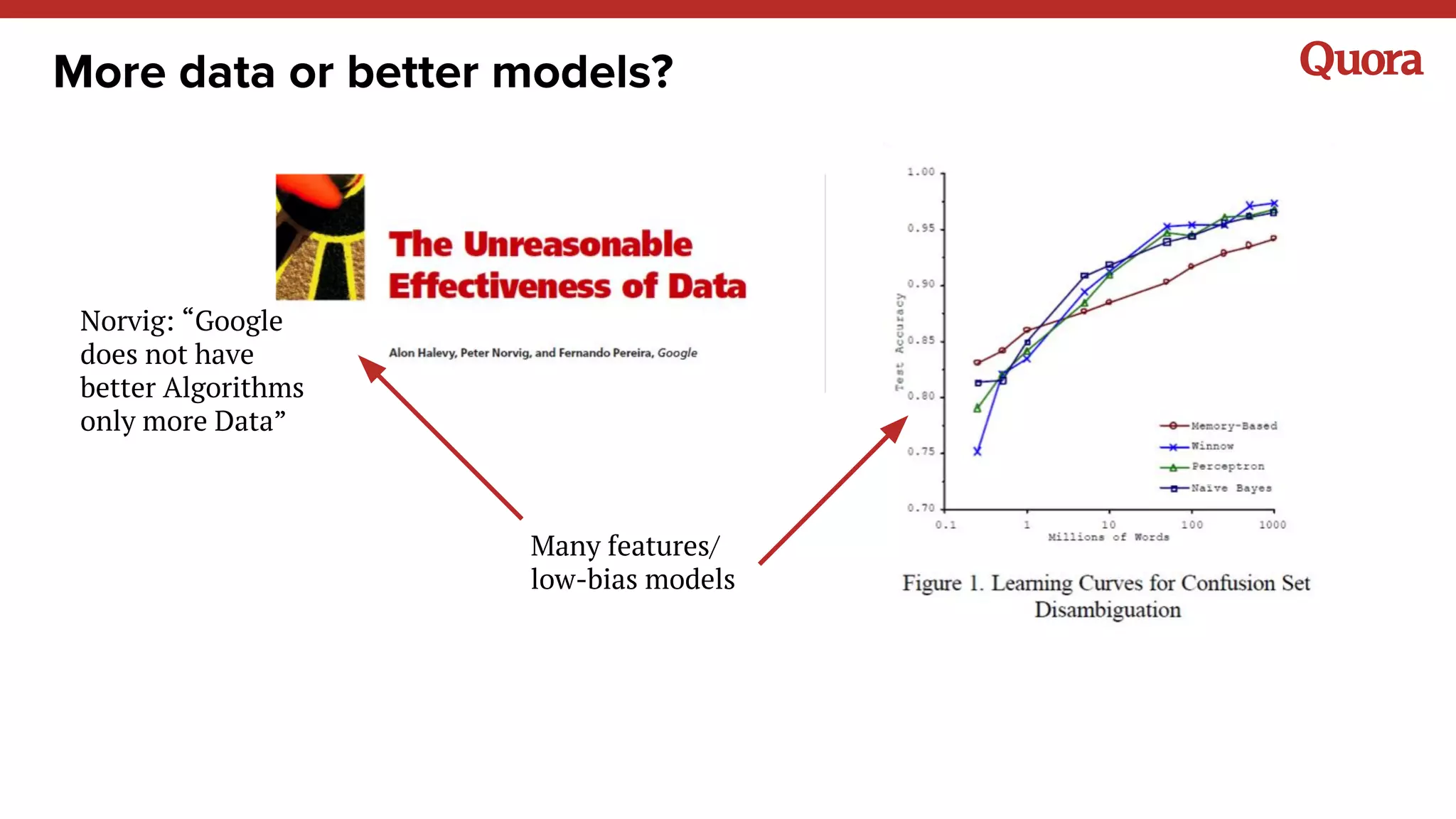
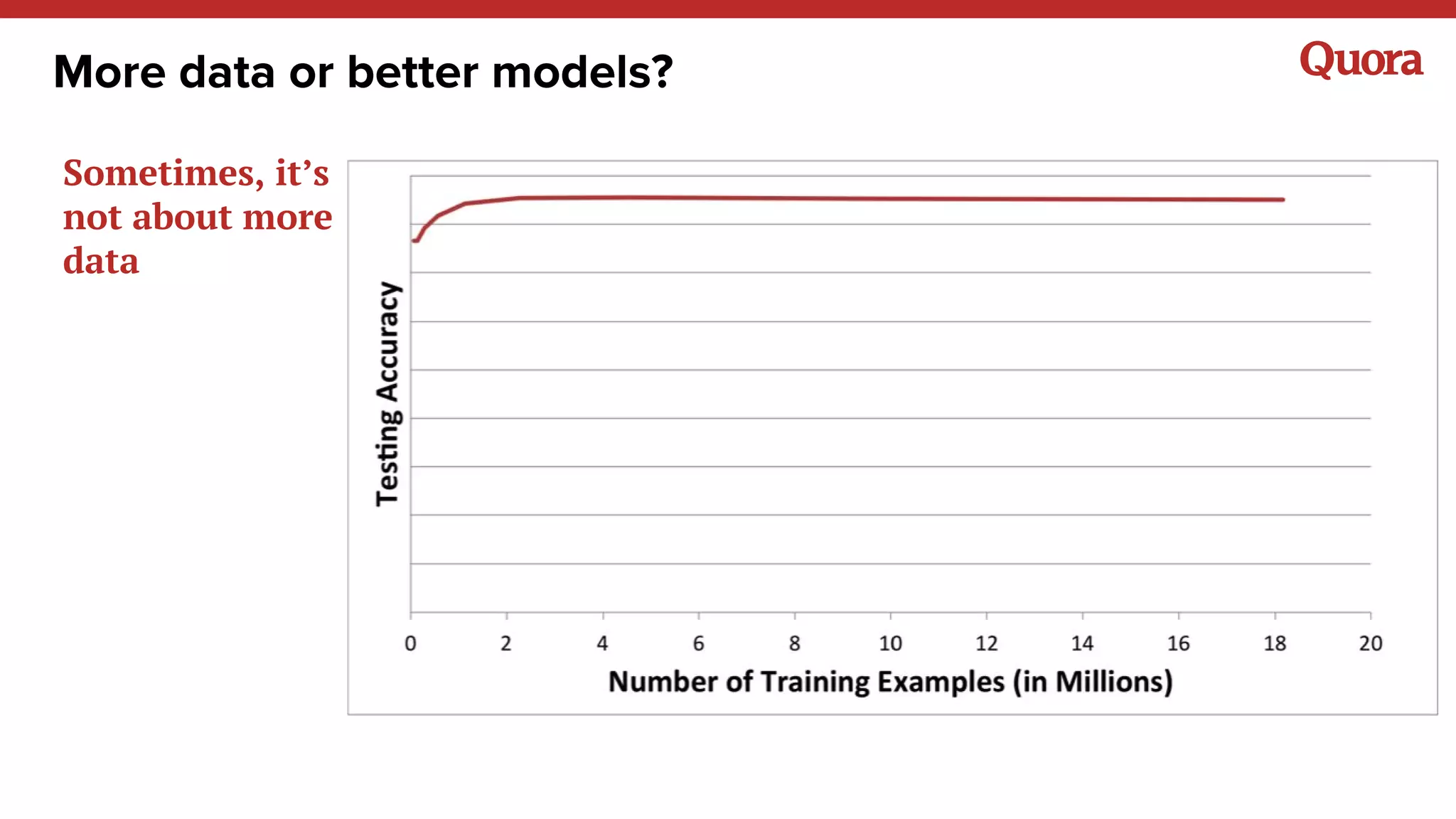





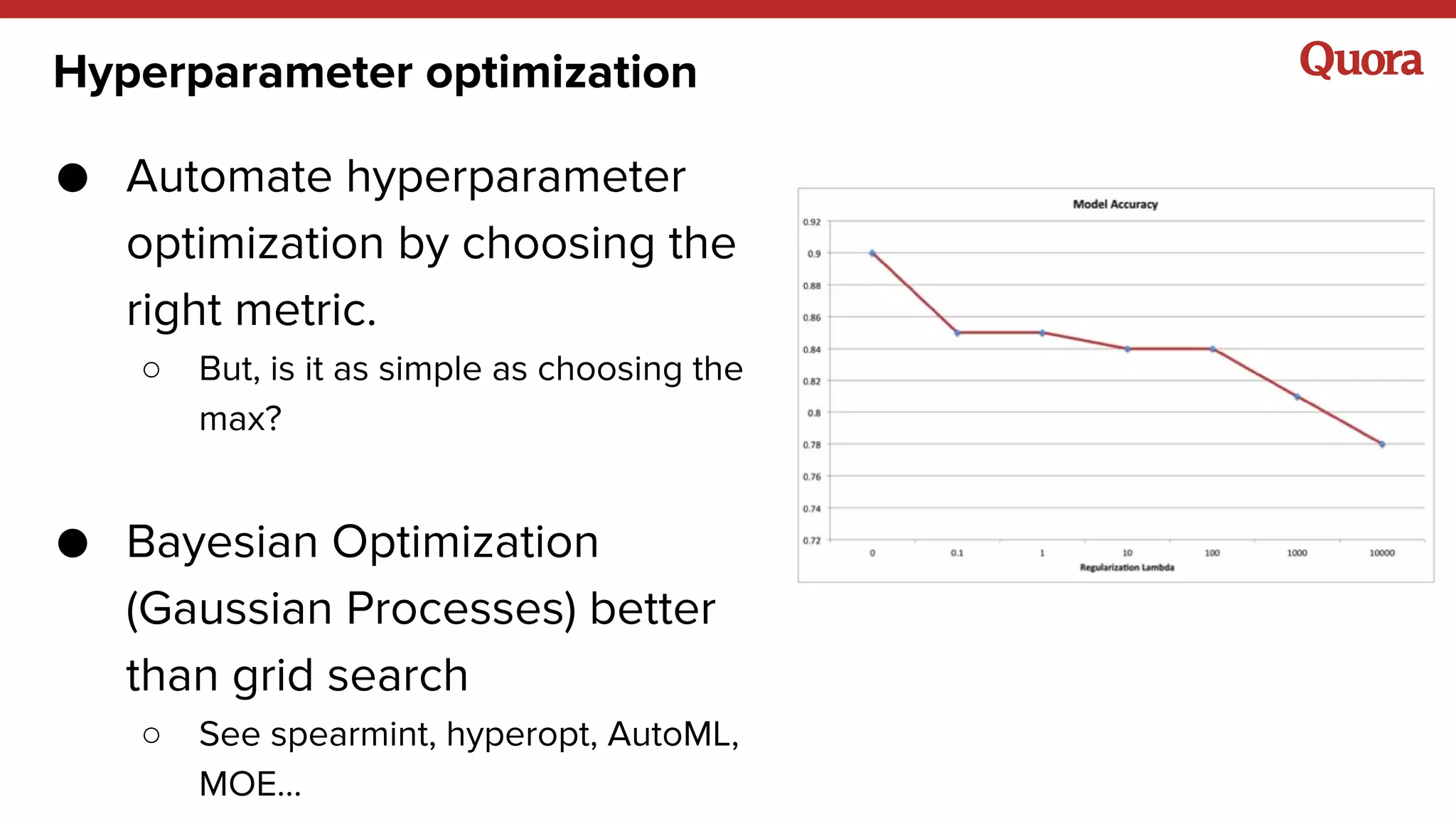




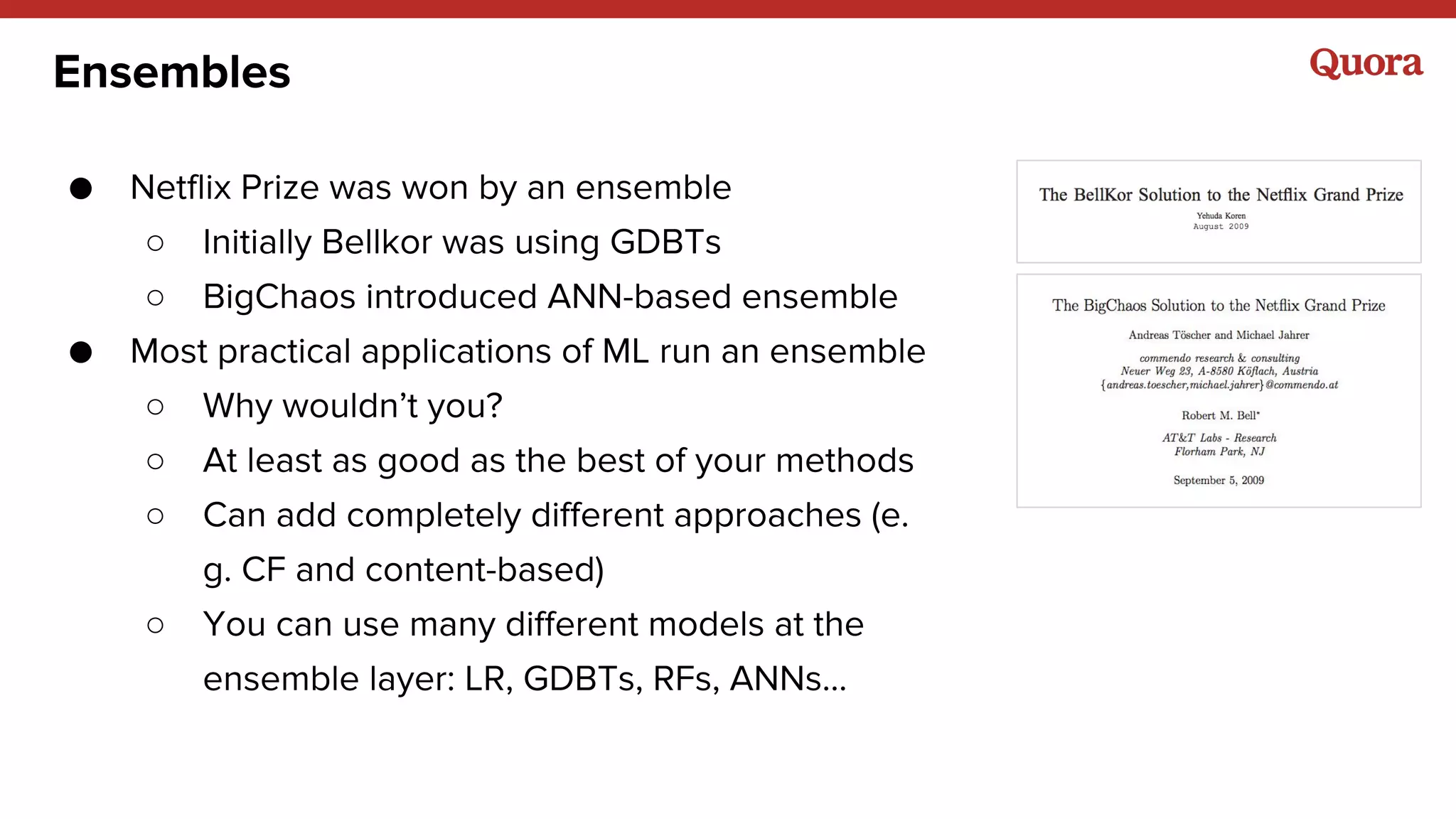








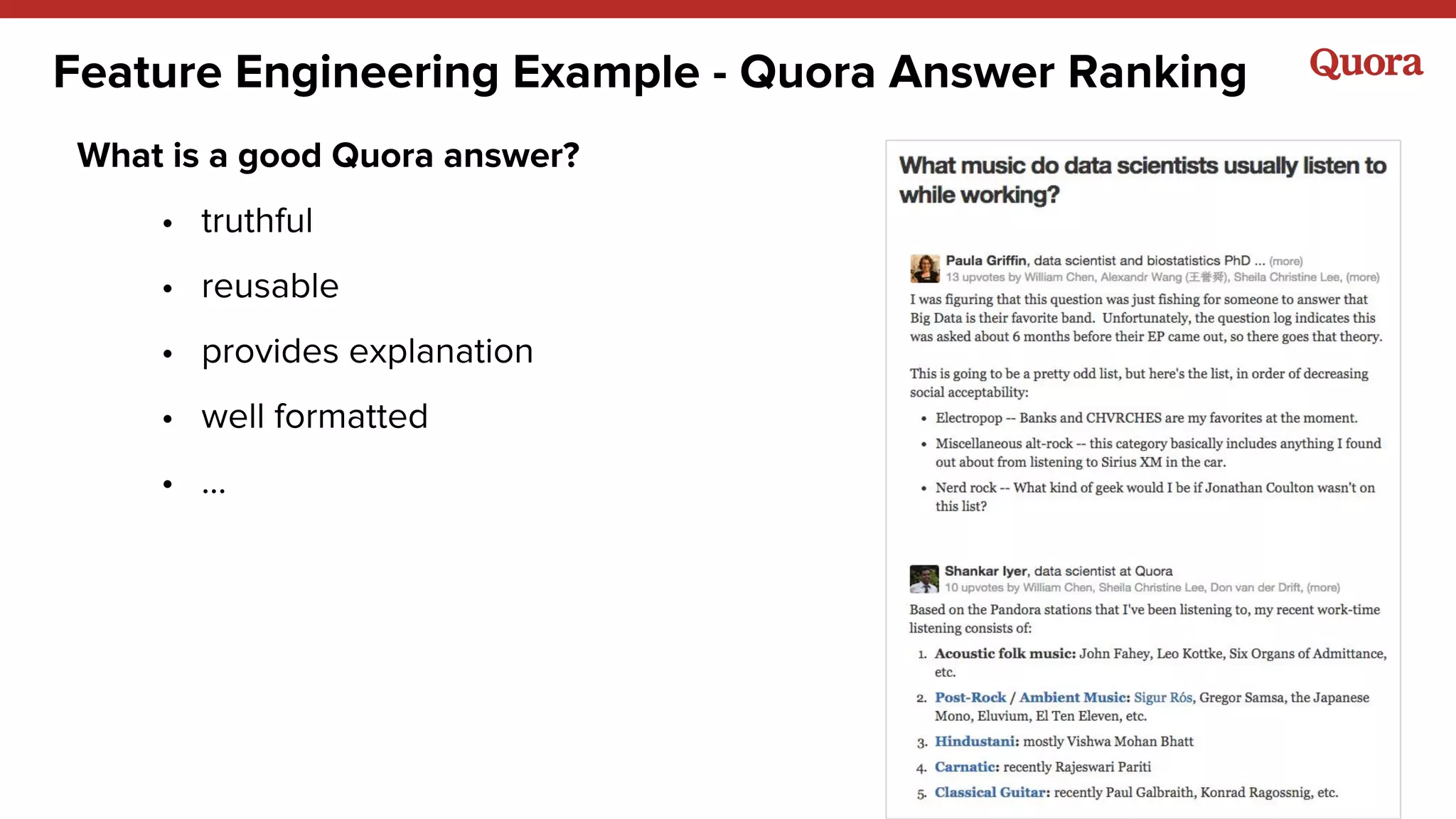
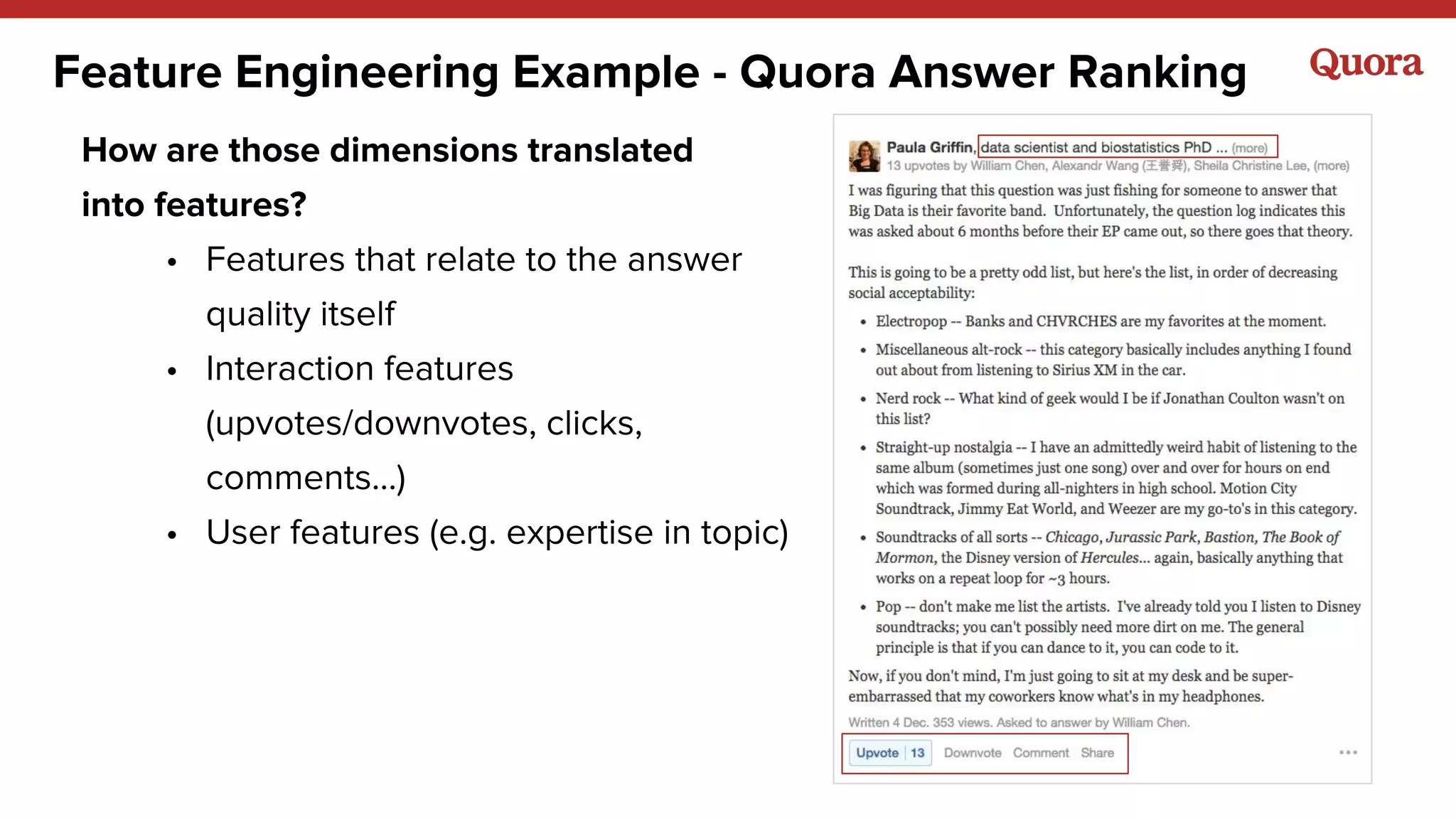











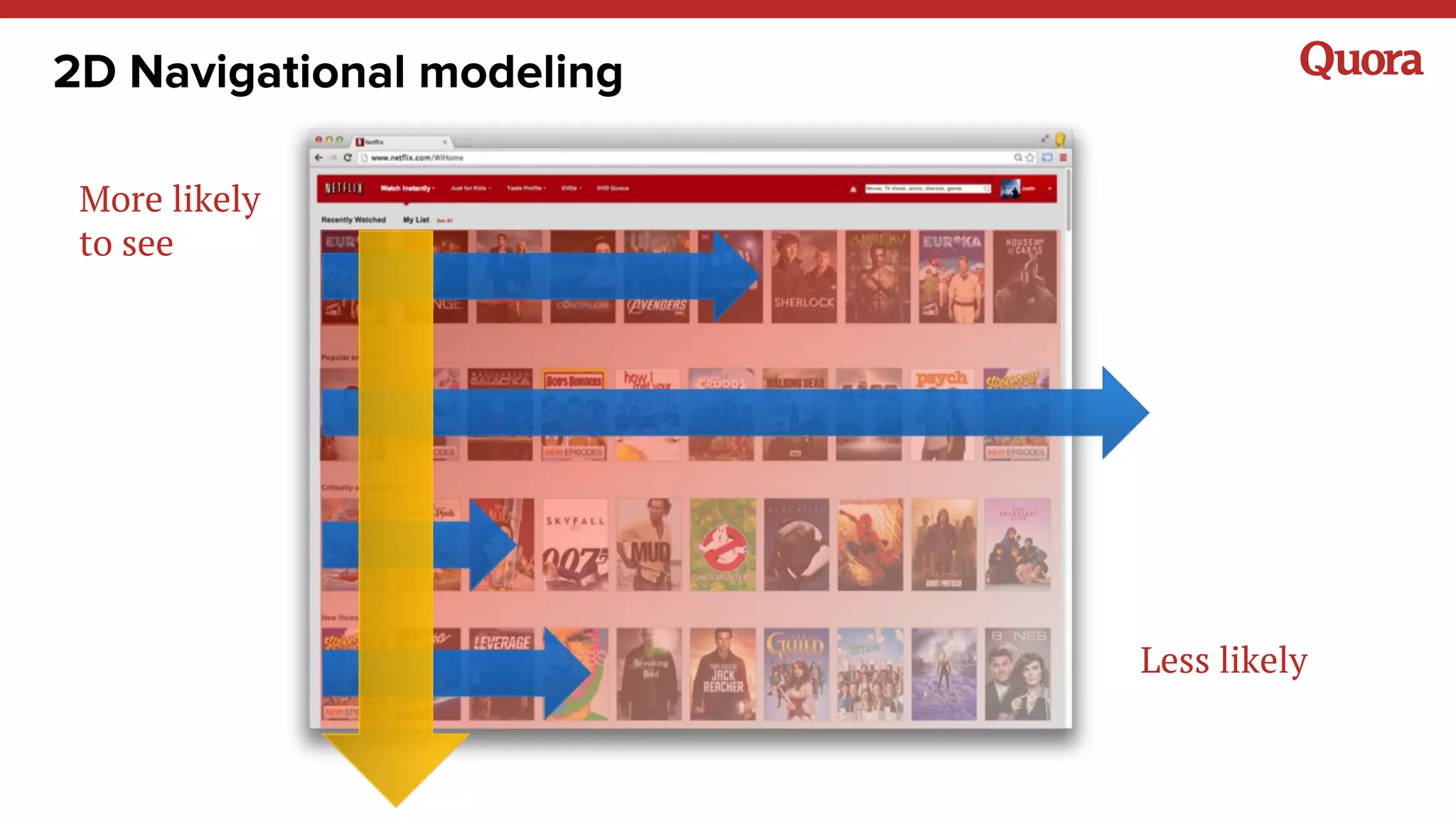


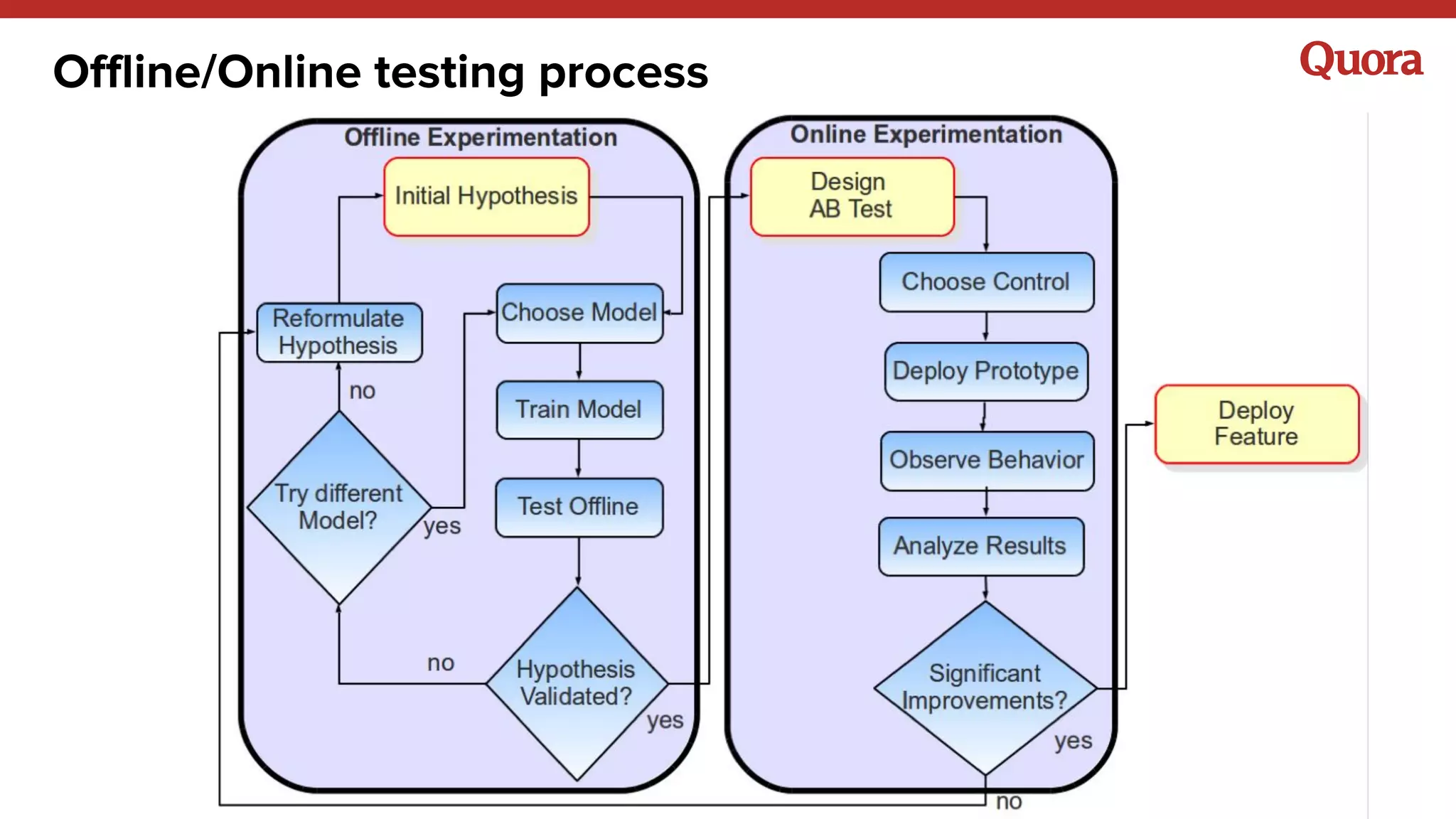

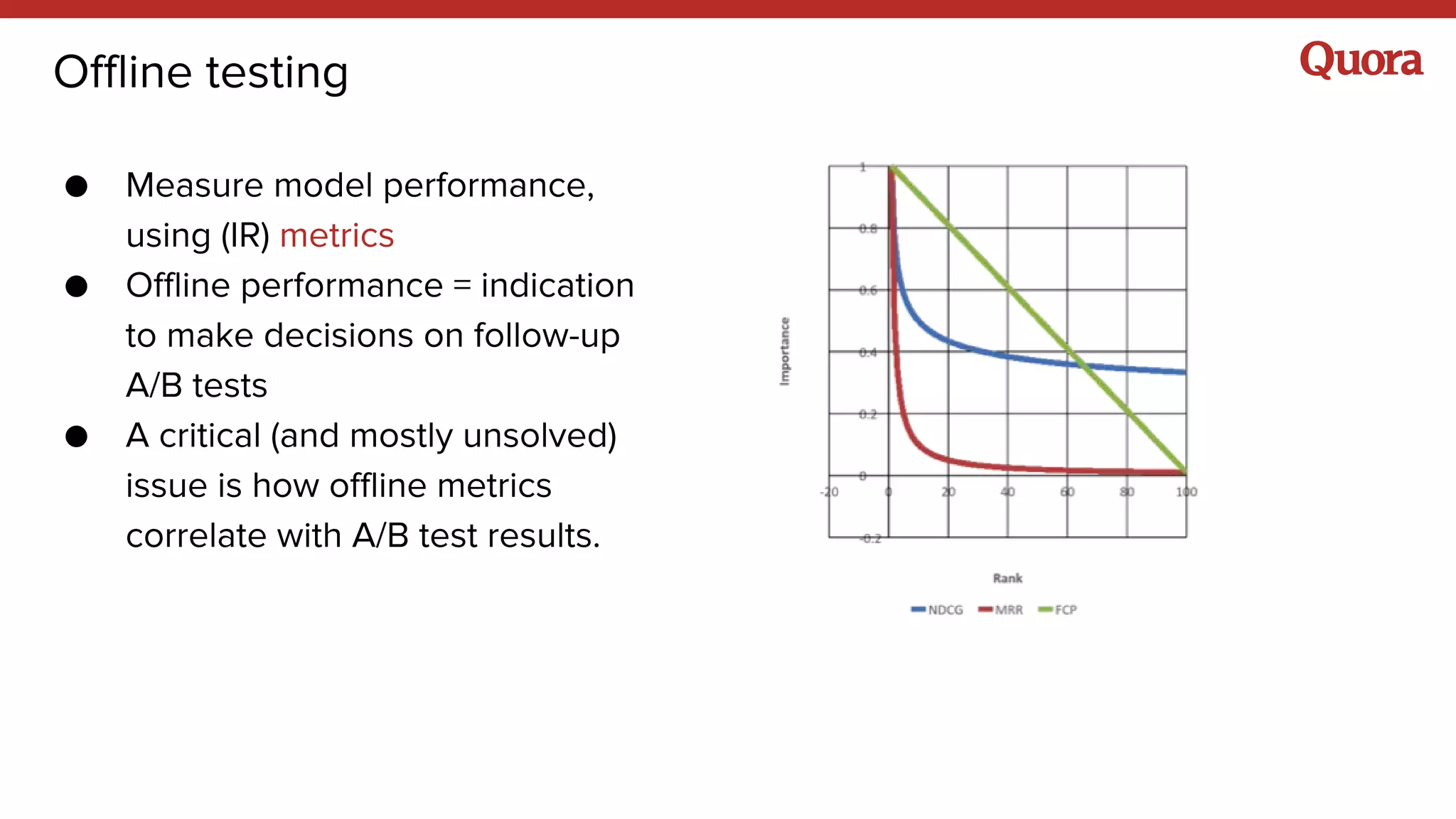






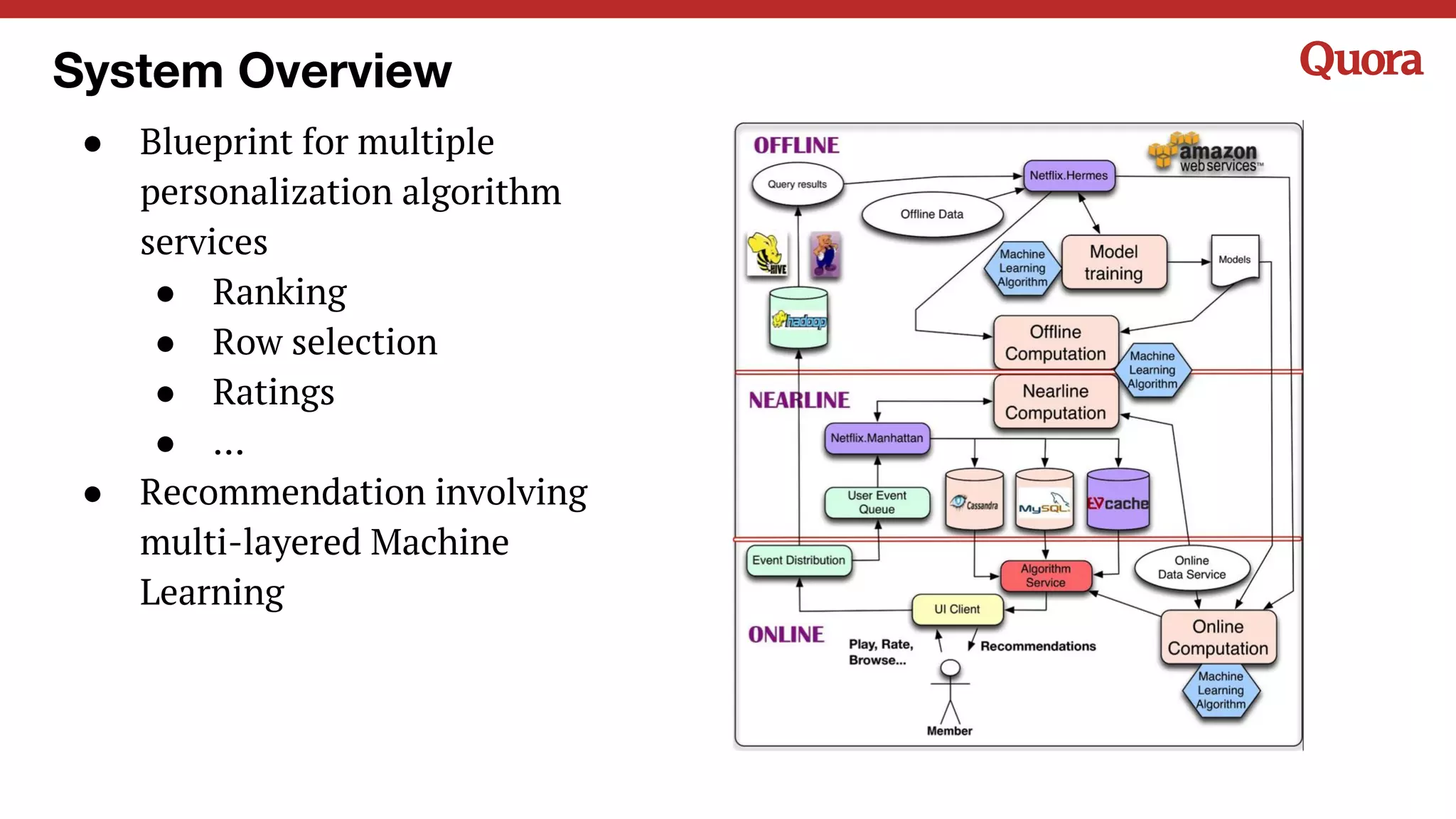
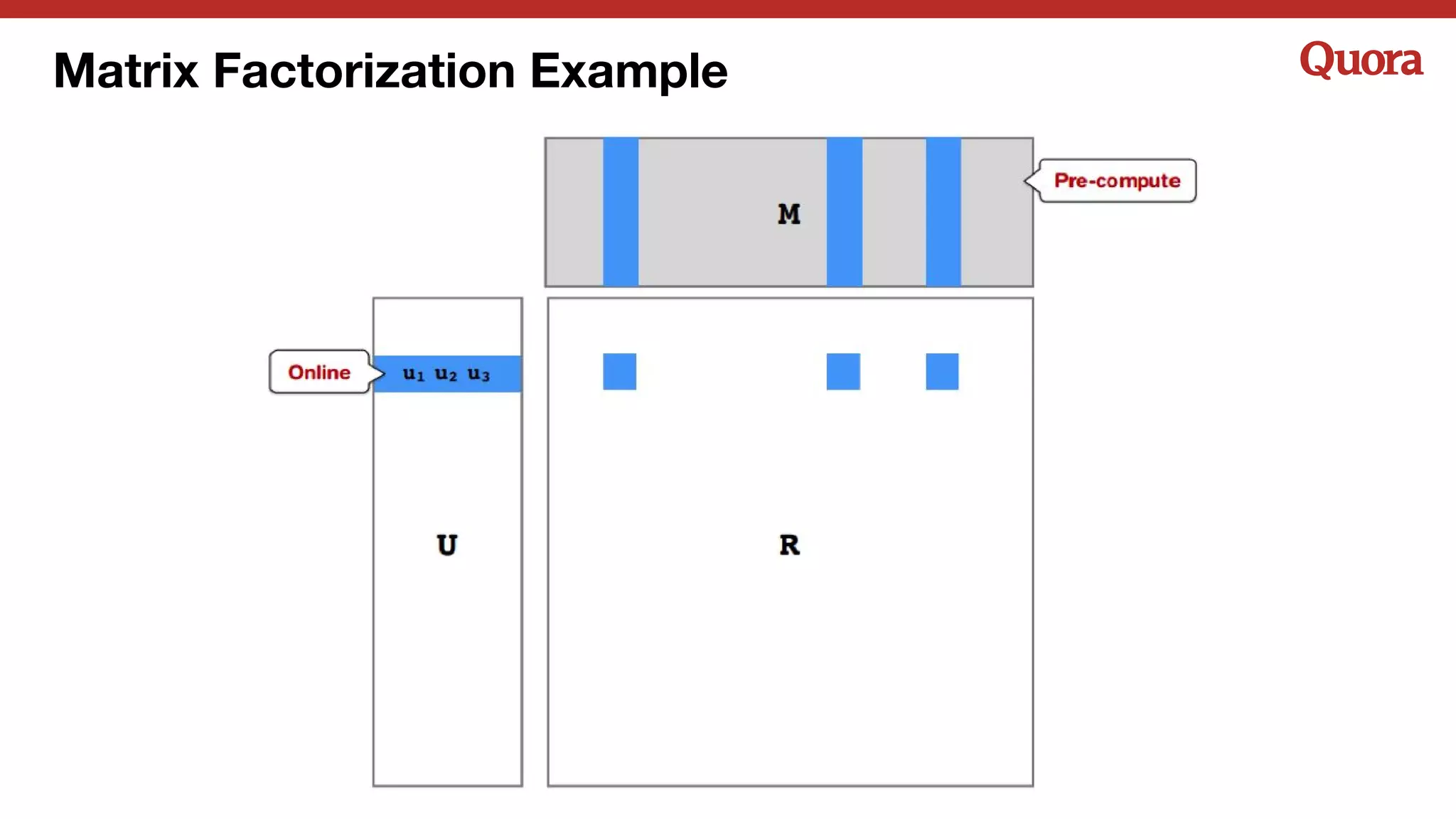







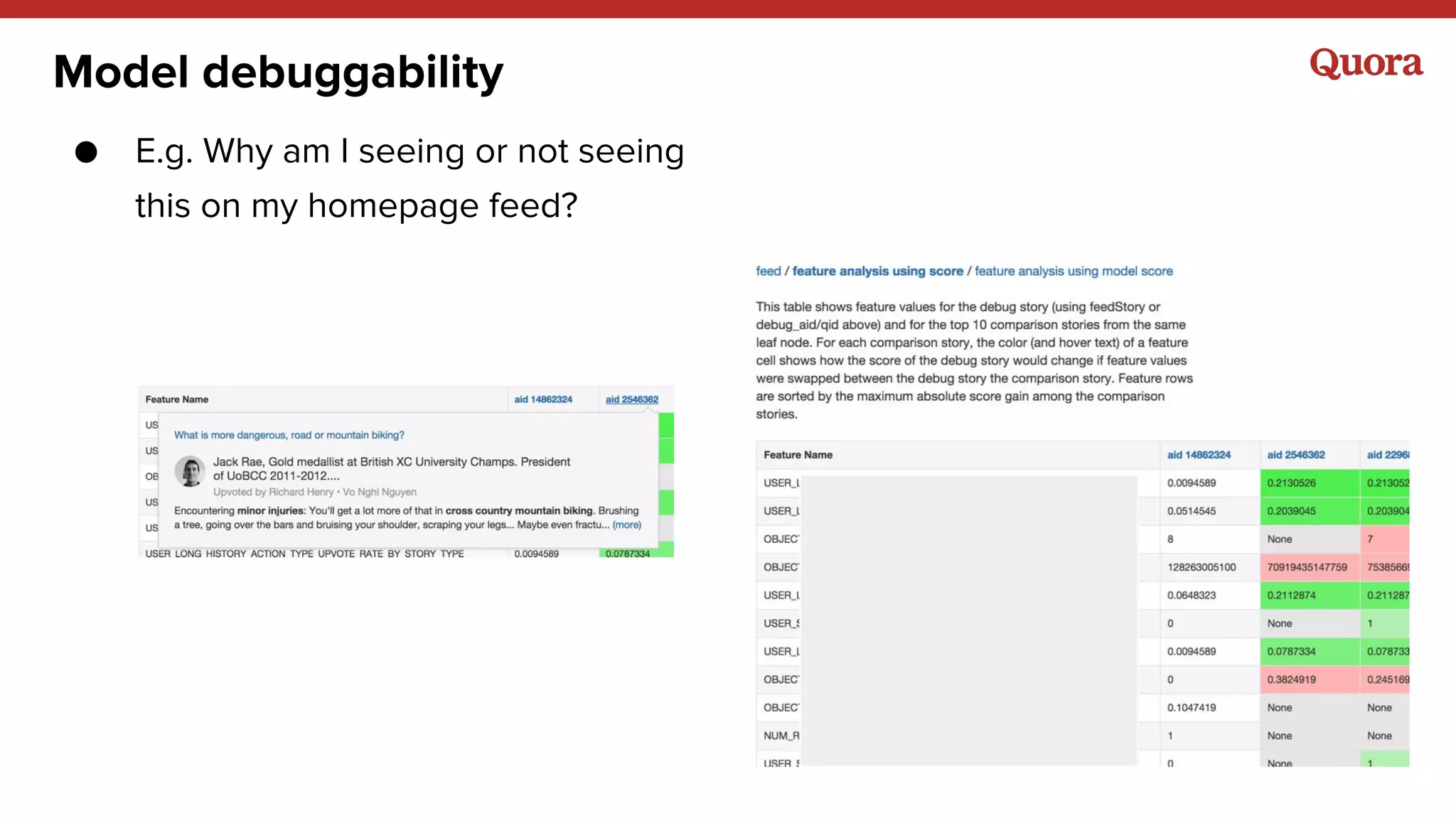


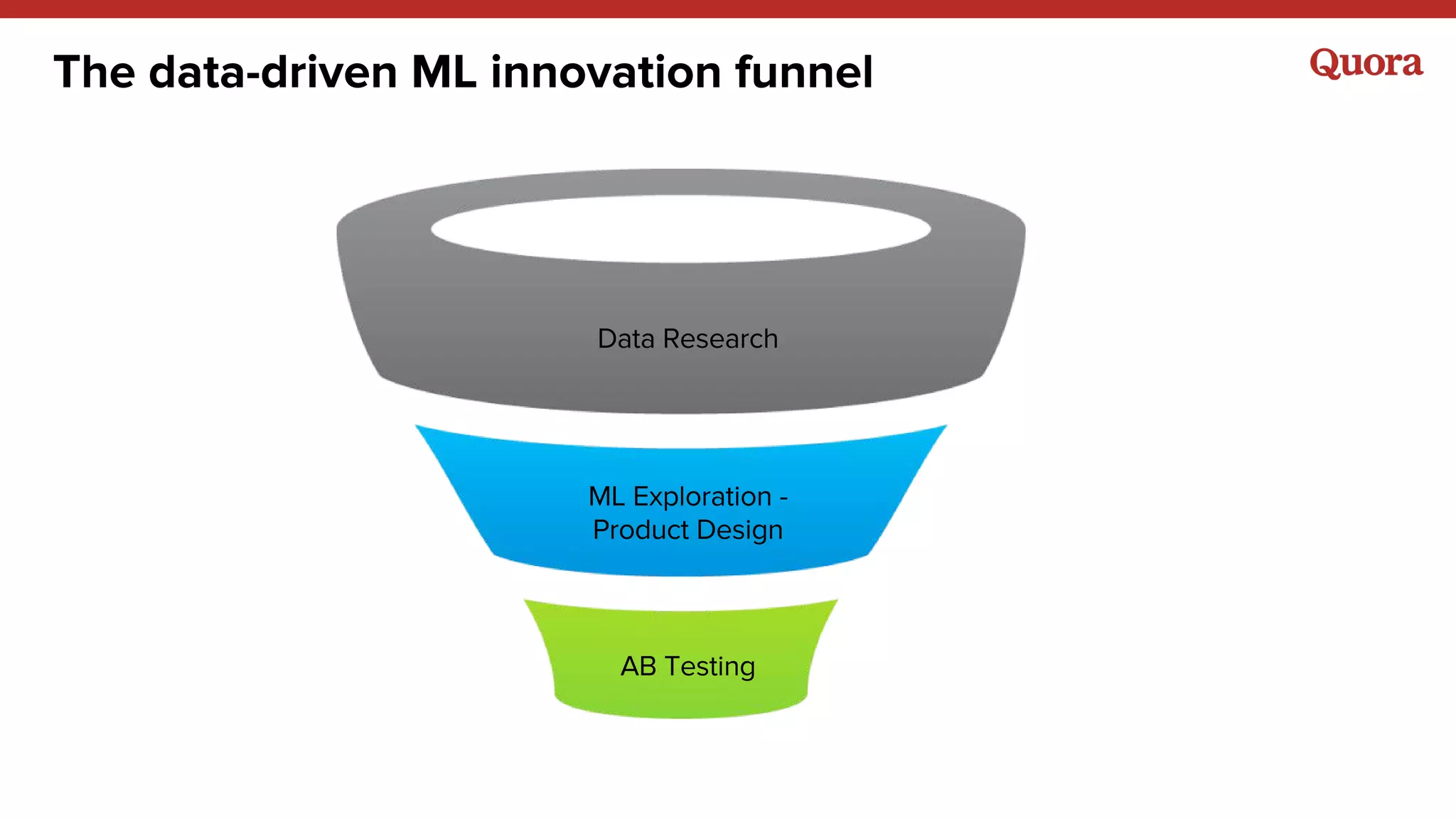




The document discusses several lessons learned about machine learning including: 1) Sometimes more data is not needed and better models can be achieved through feature engineering and appropriate hyperparameters. 2) Models will learn what they are taught through the training data, so training data needs to be thoughtful and free of biases. 3) A combination of supervised and unsupervised learning along with ensemble methods often provides the best results rather than relying on any single approach.



![Machine learning the high interest credit card of technical debt [PWL]](https://cdn.slidesharecdn.com/ss_thumbnails/machinelearning-thehighinterestcardoftechnicaldebtmeetup1-160911083514-thumbnail.jpg?width=640&height=640&fit=bounds)







































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)
















