Downloaded 101 times




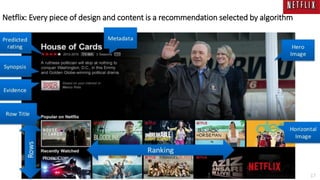

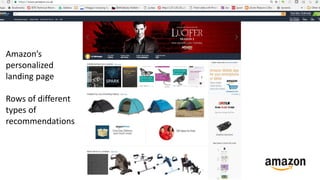
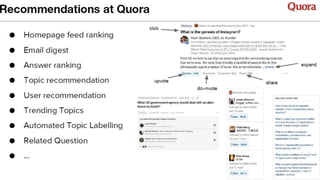
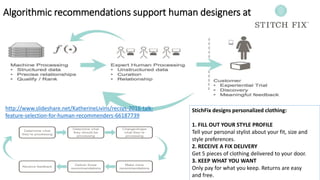












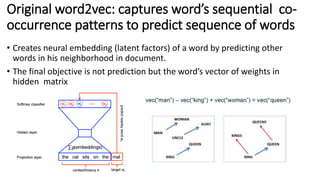




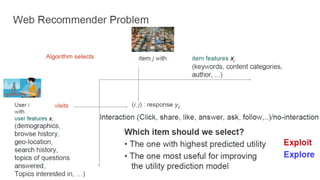





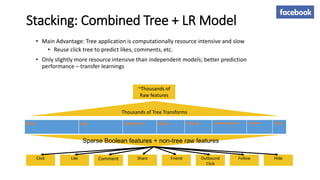
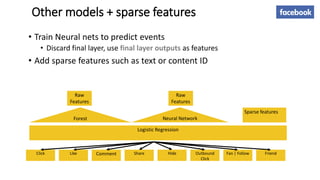
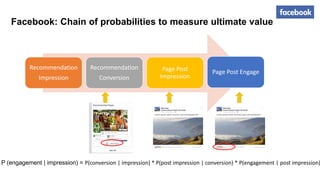










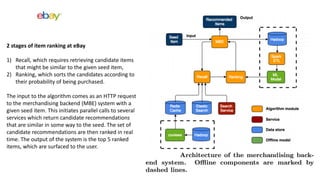


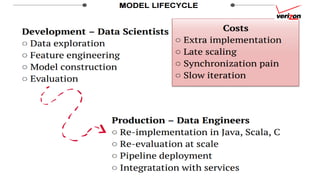
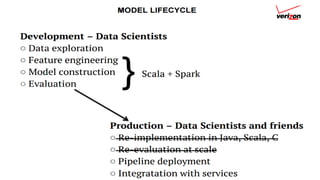



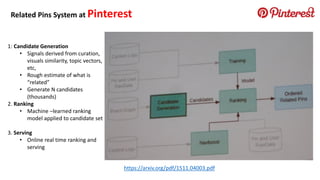



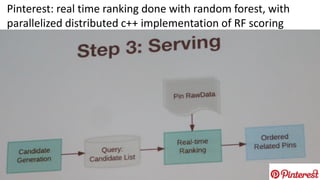





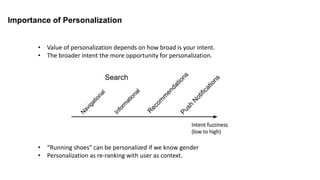


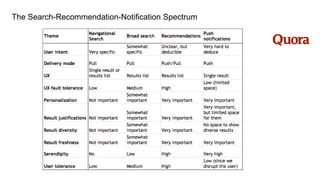











The document summarizes key topics from a recommender systems conference, including: 1. Many major companies like Netflix, Quora, and Amazon consider recommendations to be a core part of their user experience. 2. Adaptive and interactive recommendations were discussed, including how Netflix personalizes content rows based on a user's predicted mood. 3. Text modeling algorithms like word2vec were discussed for generating recommendations from content like tweets, search queries, or product descriptions.























































































