![Semantic Technology: the basics Jans Aasman, Ph.D. CEO Franz Inc [email_address]](https://image.slidesharecdn.com/2010-sem-meetup-the-basics-101014112906-phpapp01/75/Semantic-Technology-The-Basics-1-2048.jpg)





![ntriple format Resource or Blank Node Only Resource Resource Literal Blank Node (?:(?<=<)[^>]+(?=>))|(?:\"(?:(?:[^\"]|(?:\\\"))*)\"[^. ]*)|(?:_:[-_a-zA-Z0-9]+)](https://image.slidesharecdn.com/2010-sem-meetup-the-basics-101014112906-phpapp01/75/Semantic-Technology-The-Basics-8-2048.jpg)



















![How would you do this with your standard search engine? Give me a newspaper text with a republican and a democrat that serve on two subcommittees that have the same parent committee. Which [democrat|republican] is most vocal in the oil spill disaster Given this text, find all the other texts that have the same people and the same main topics but not democrats in the text. Which [democrate|republican|senator|representative] get most of the attention in the last week. Give me the distribution of the most important topics yesterday](https://image.slidesharecdn.com/2010-sem-meetup-the-basics-101014112906-phpapp01/75/Semantic-Technology-The-Basics-46-2048.jpg)






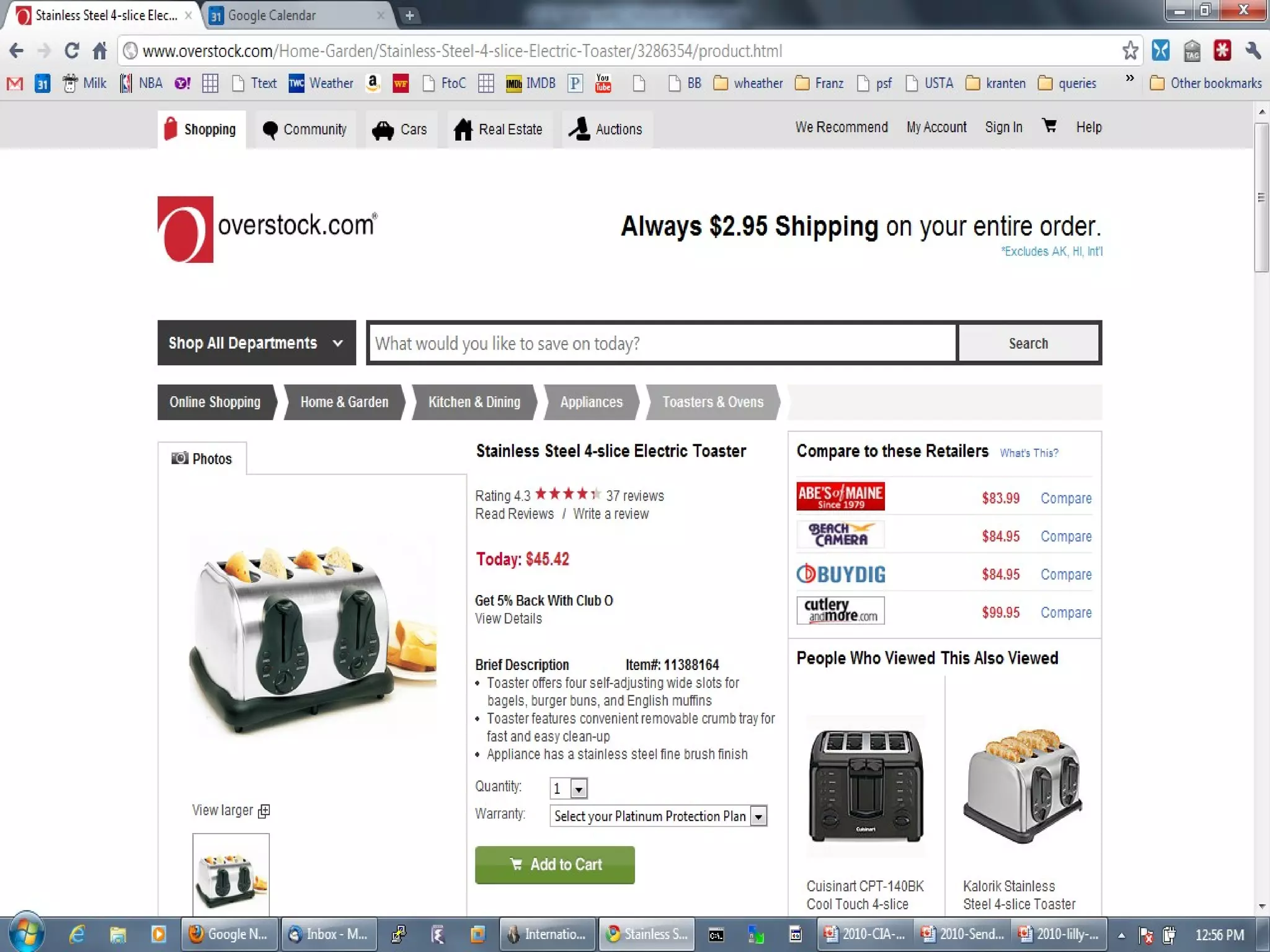
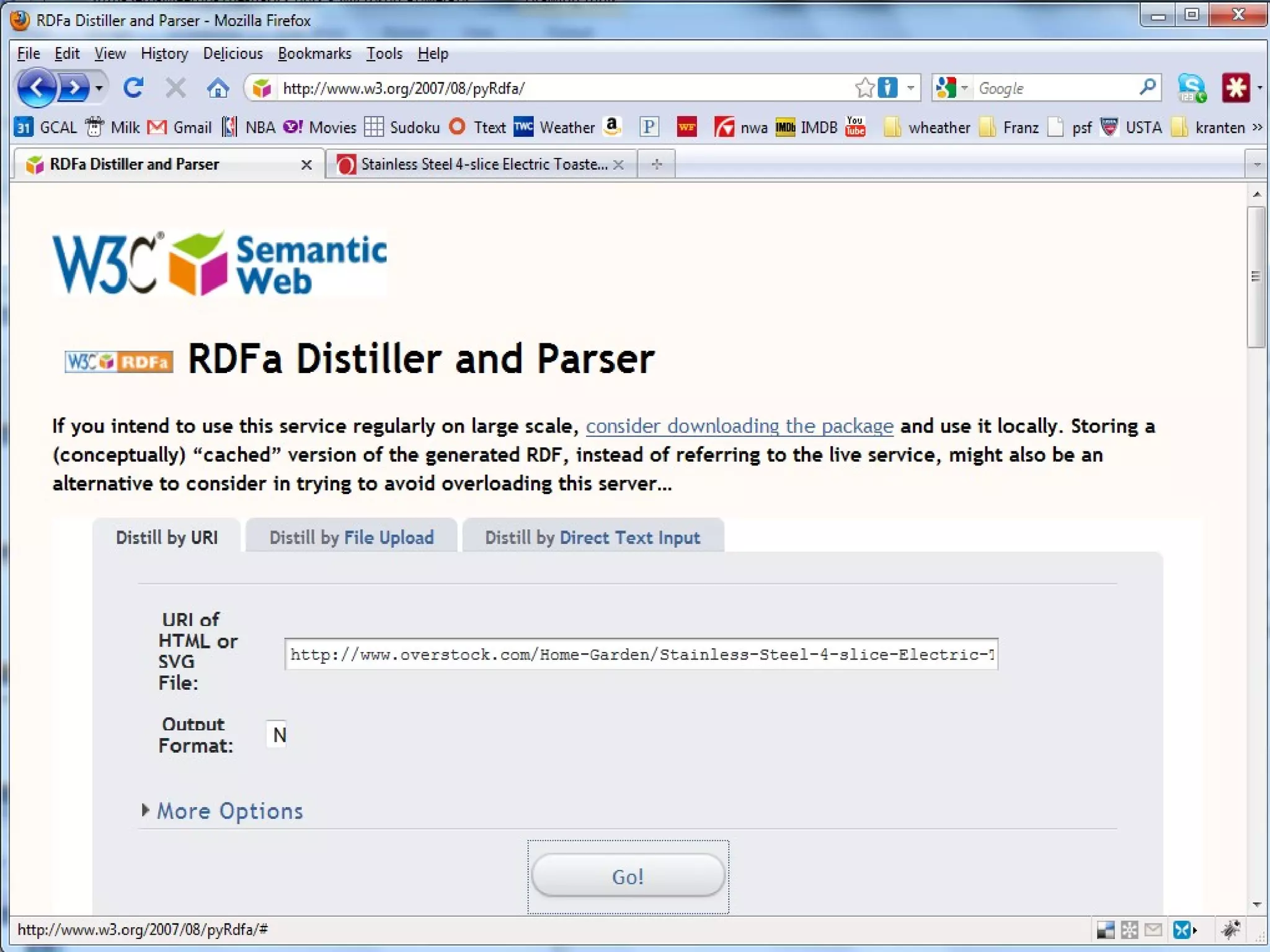


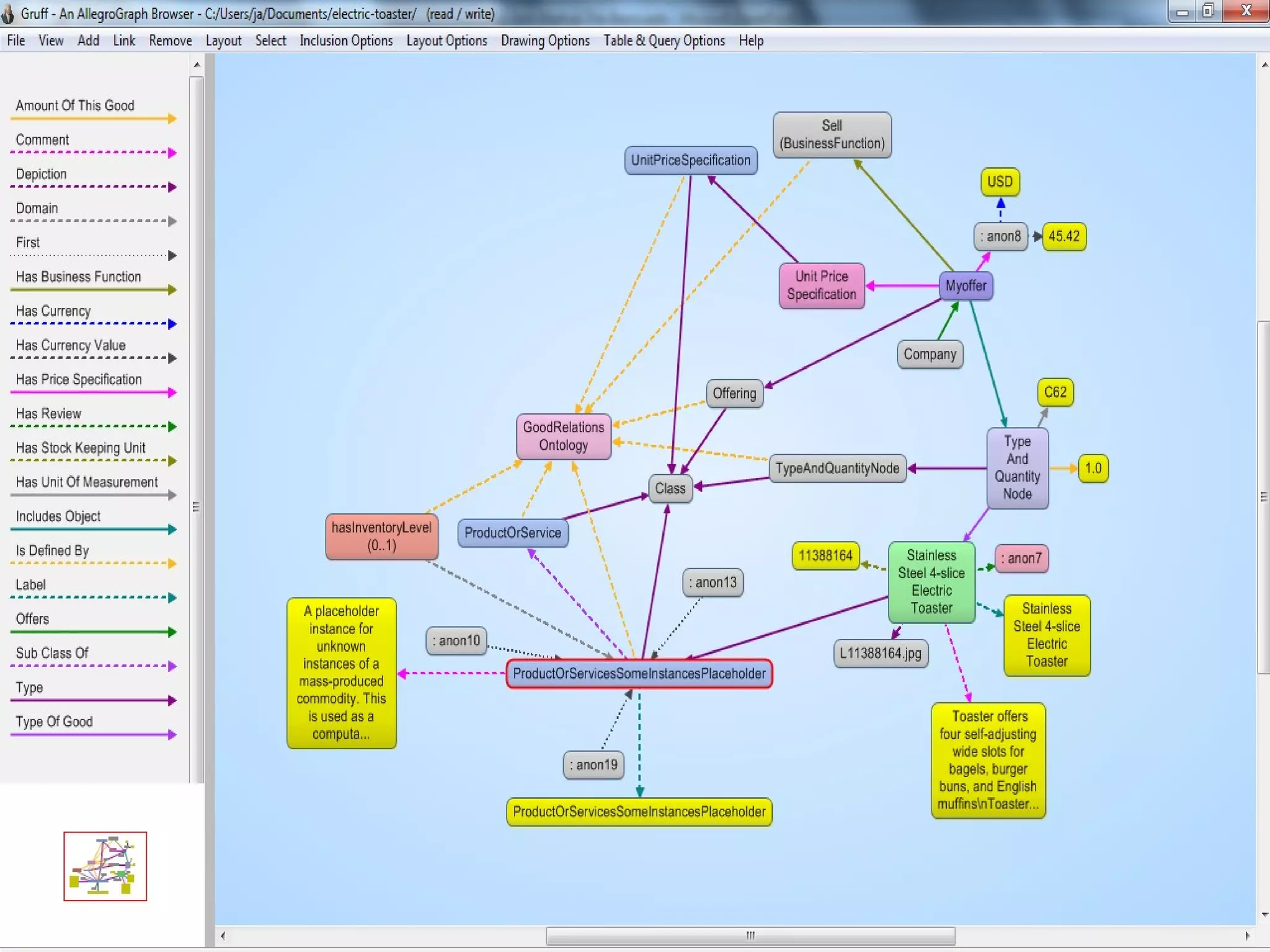





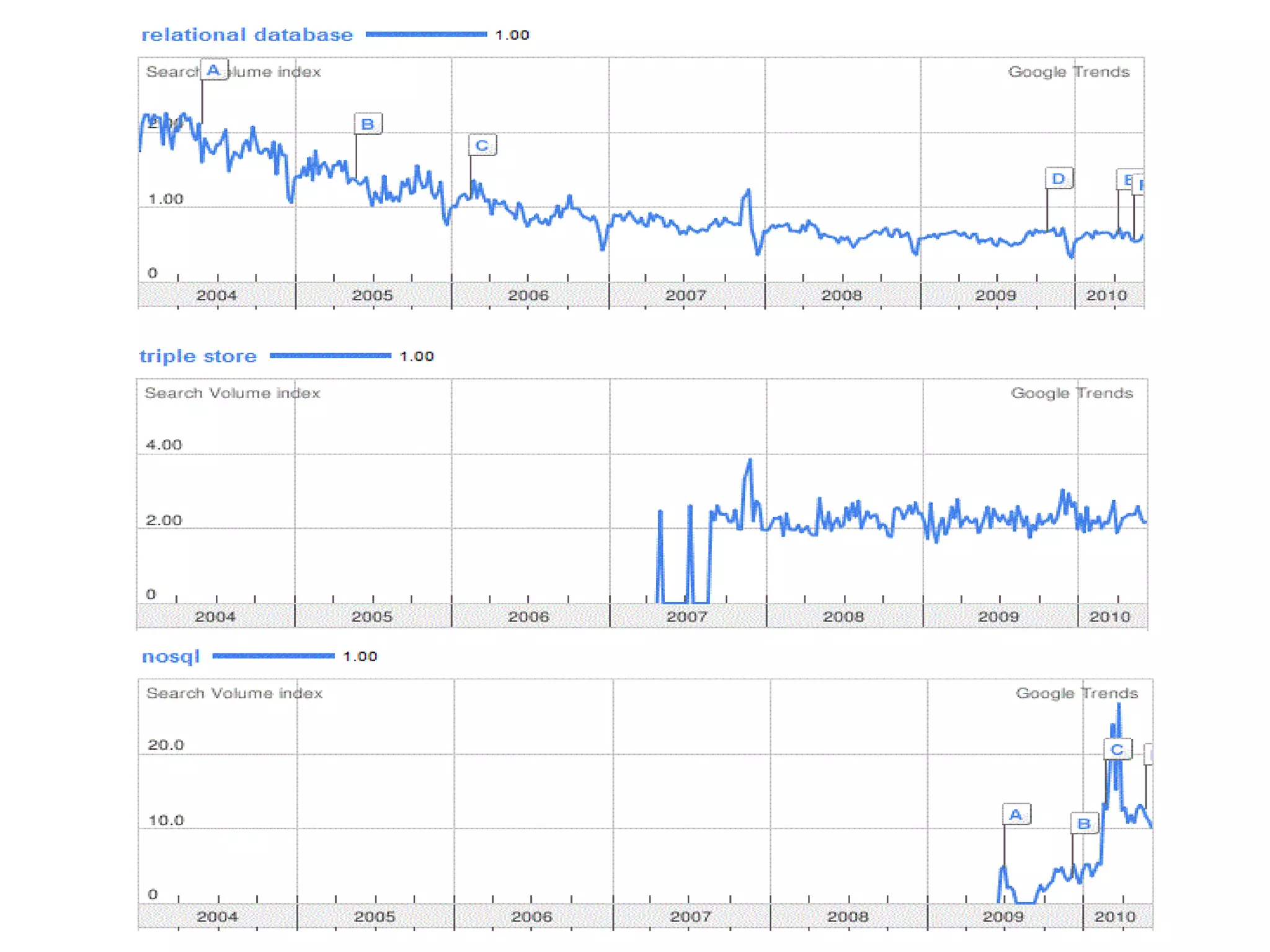
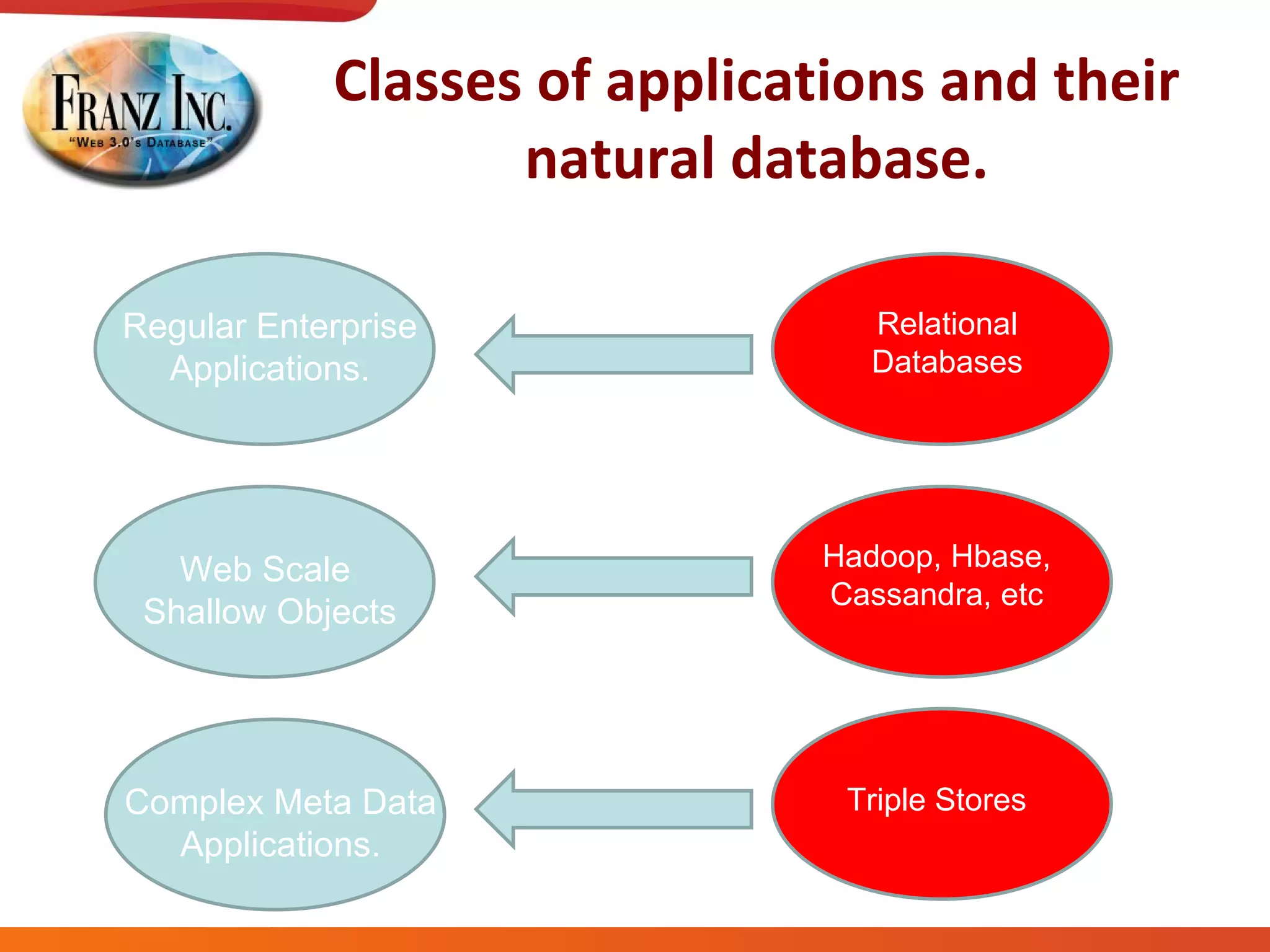






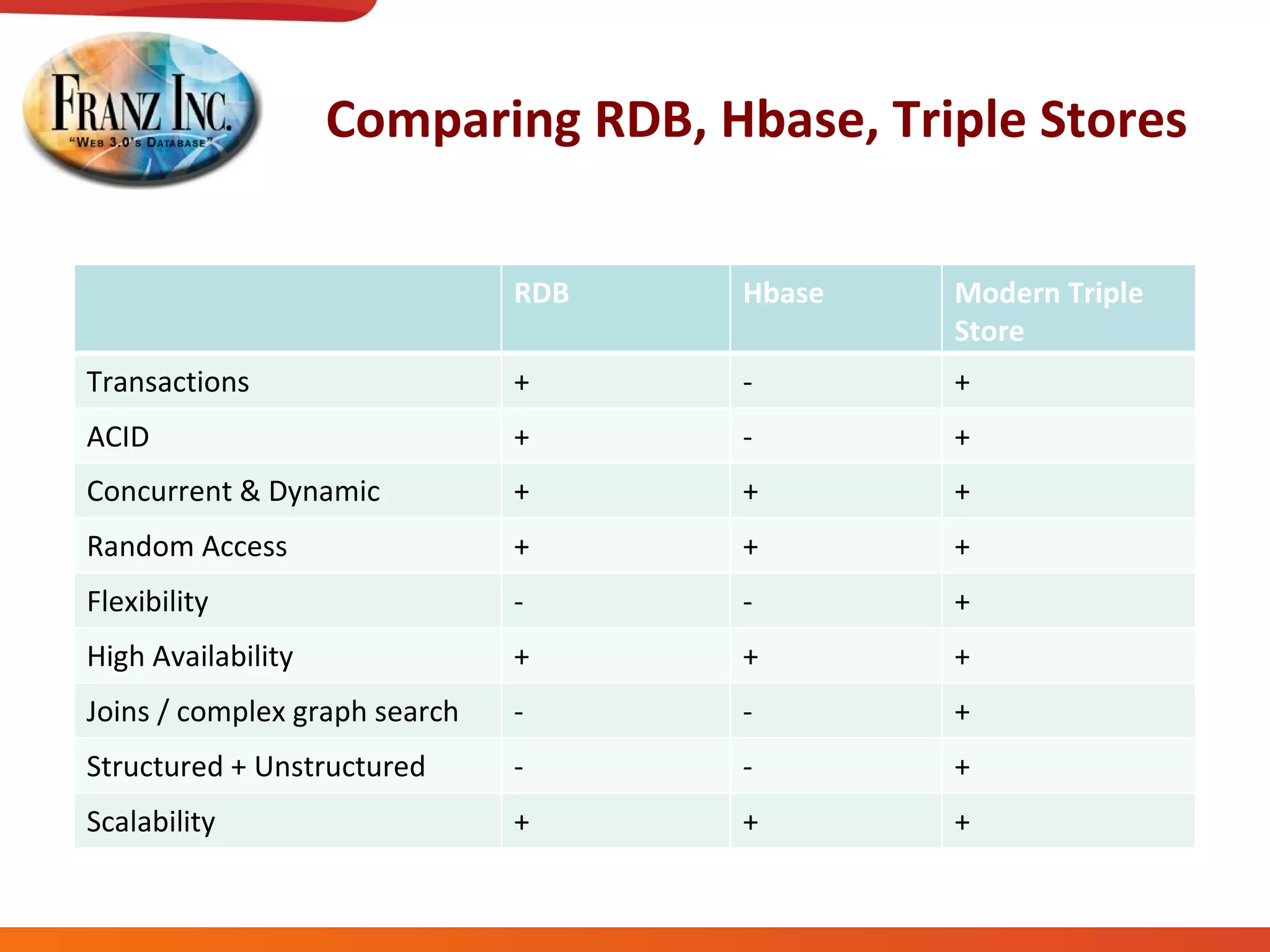



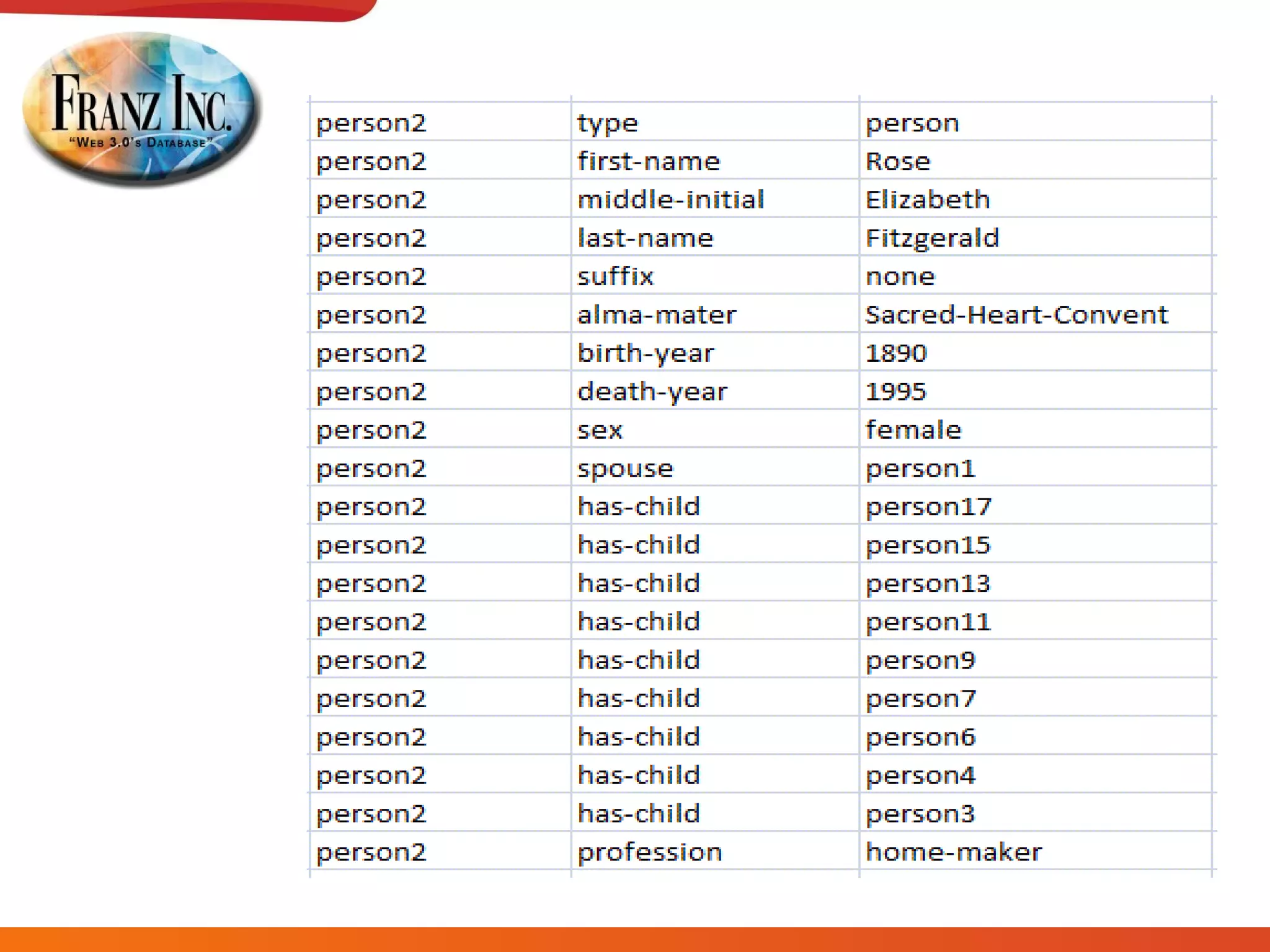
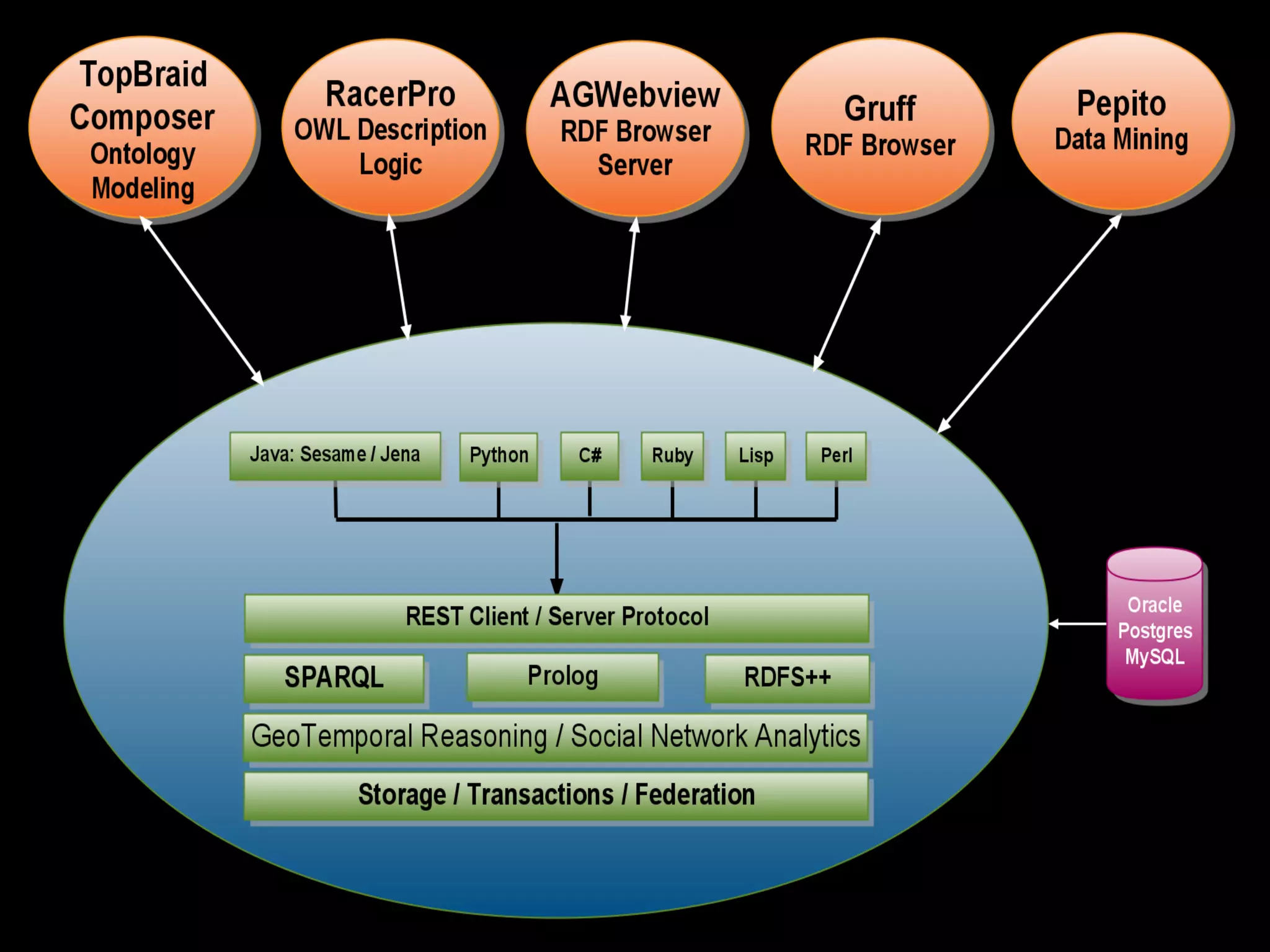
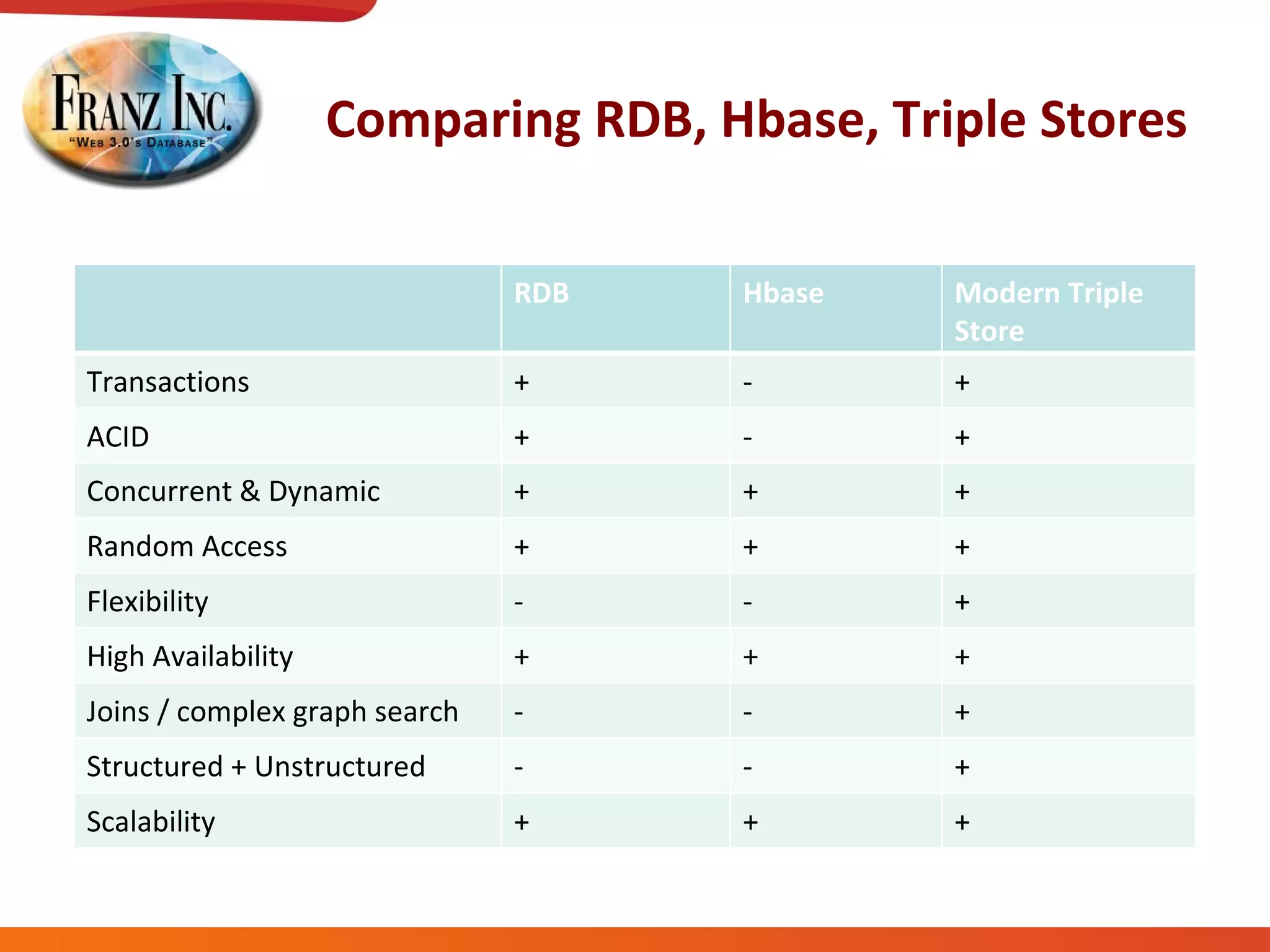
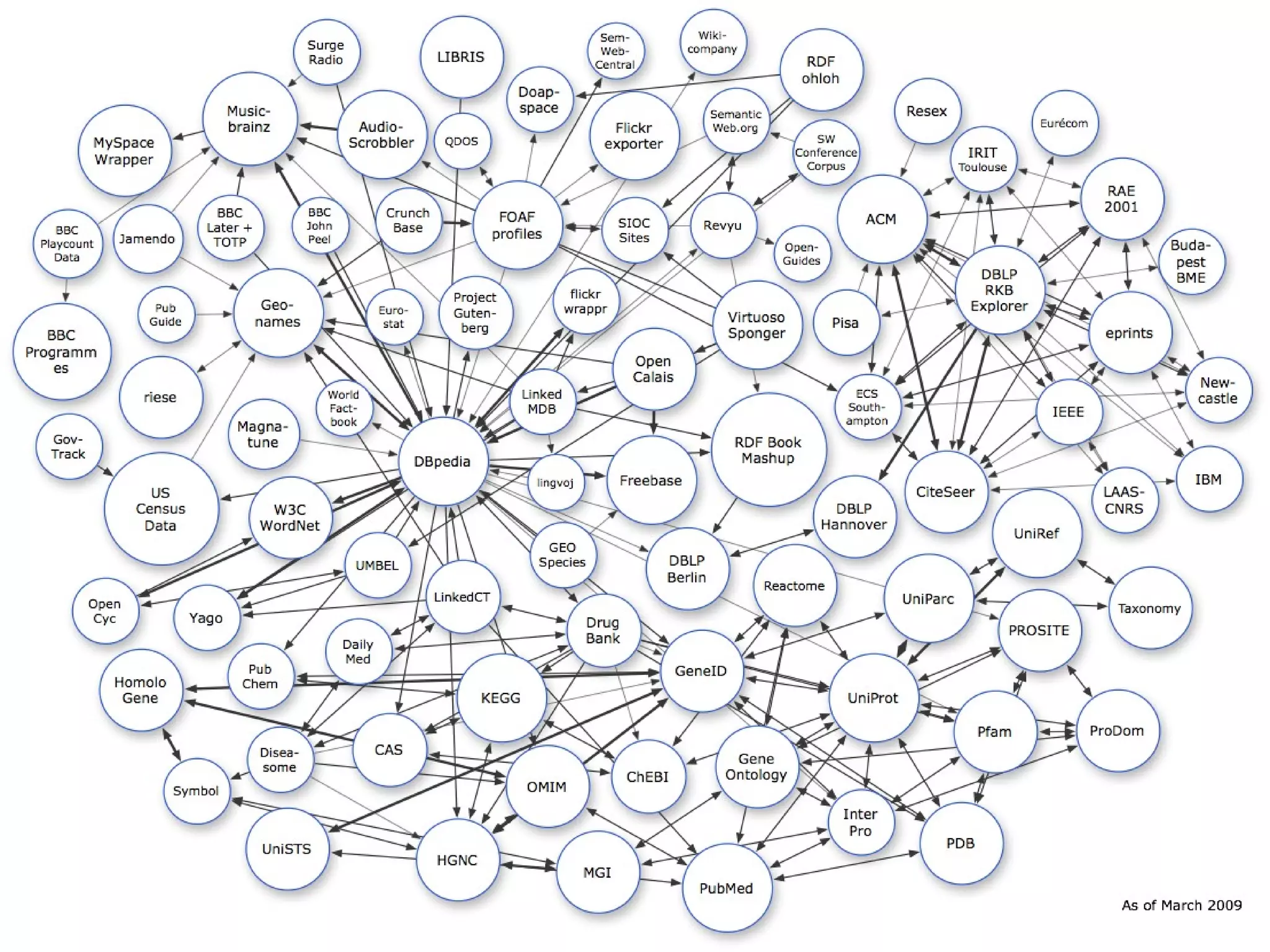
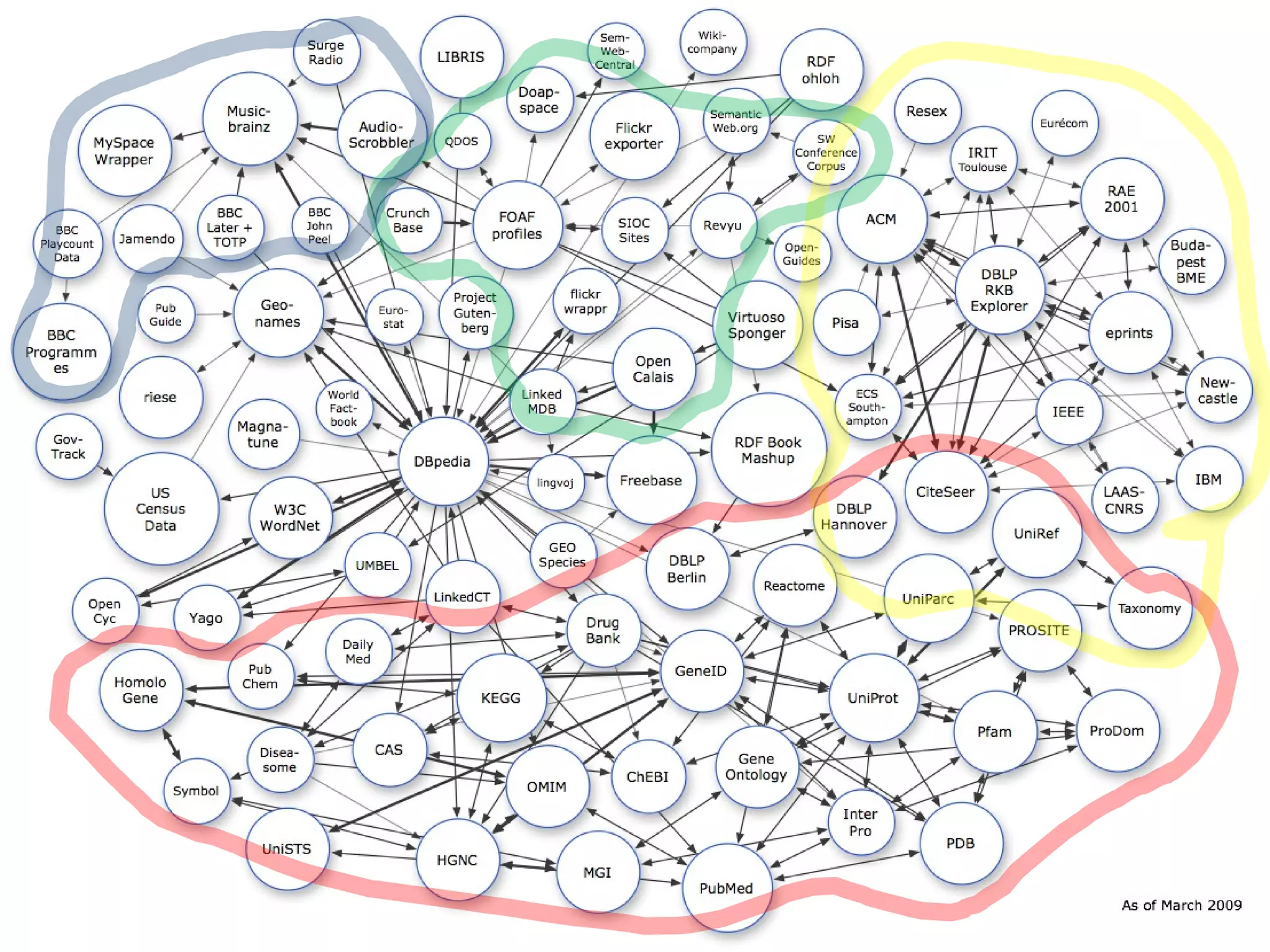
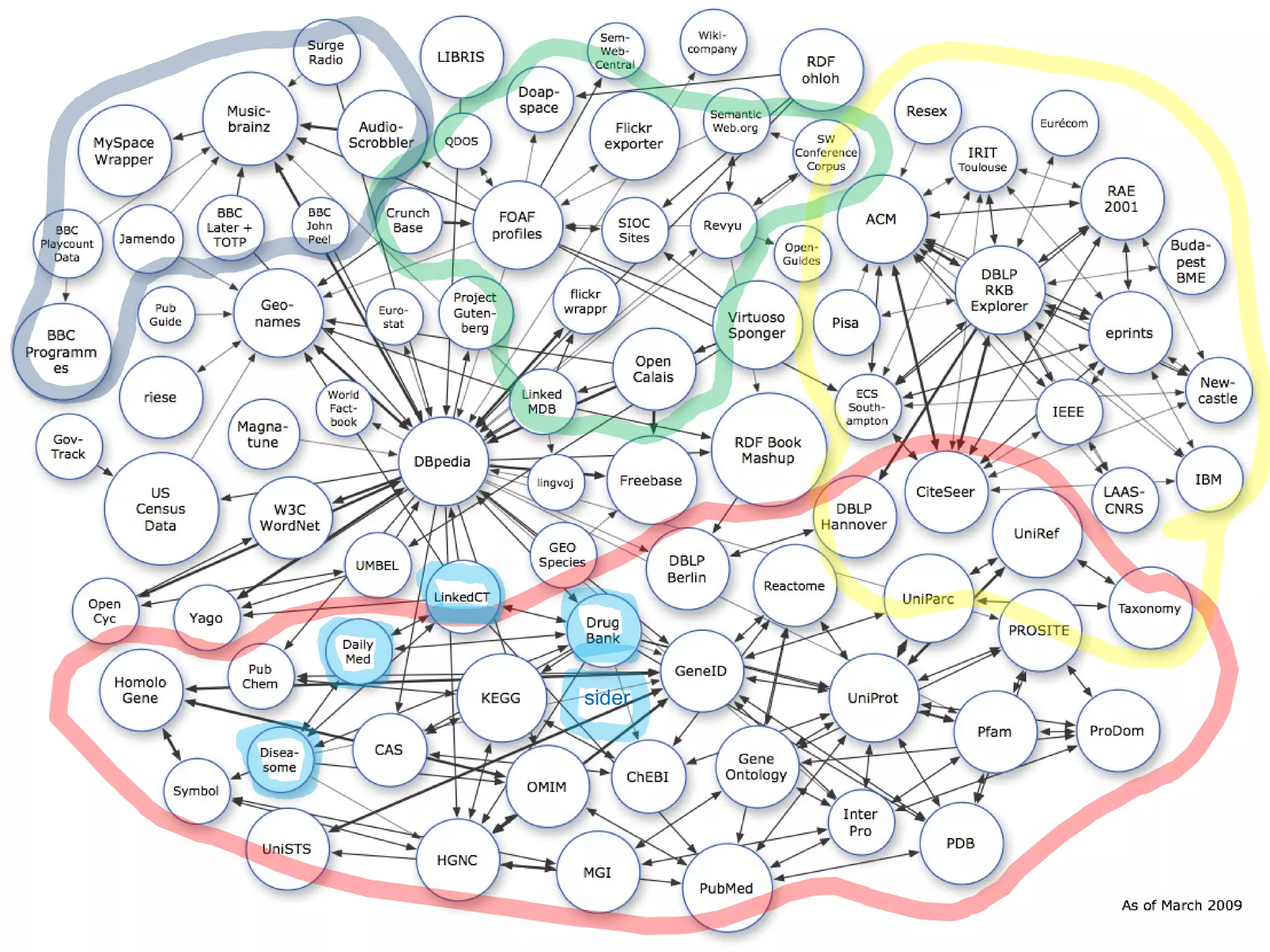
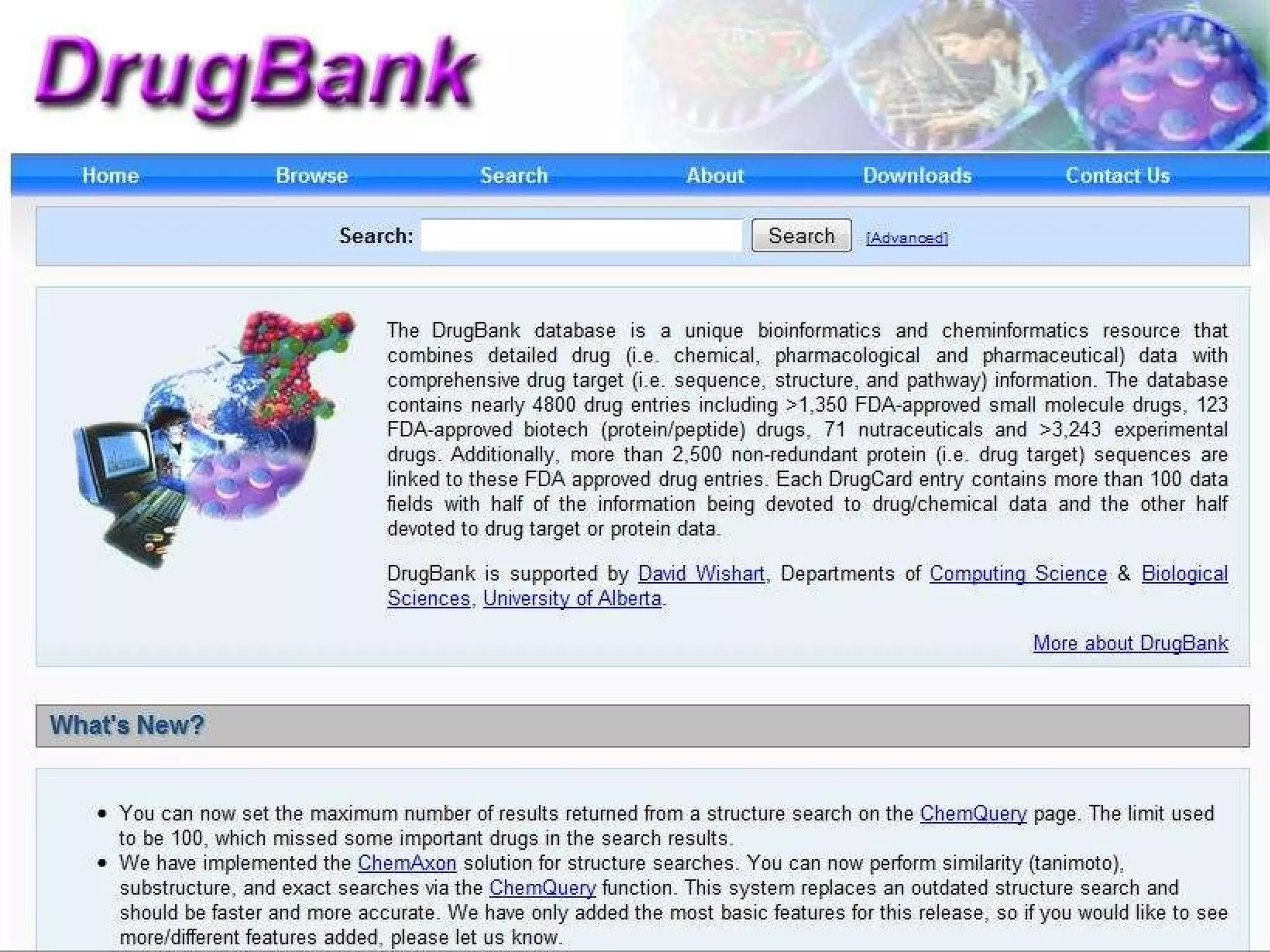
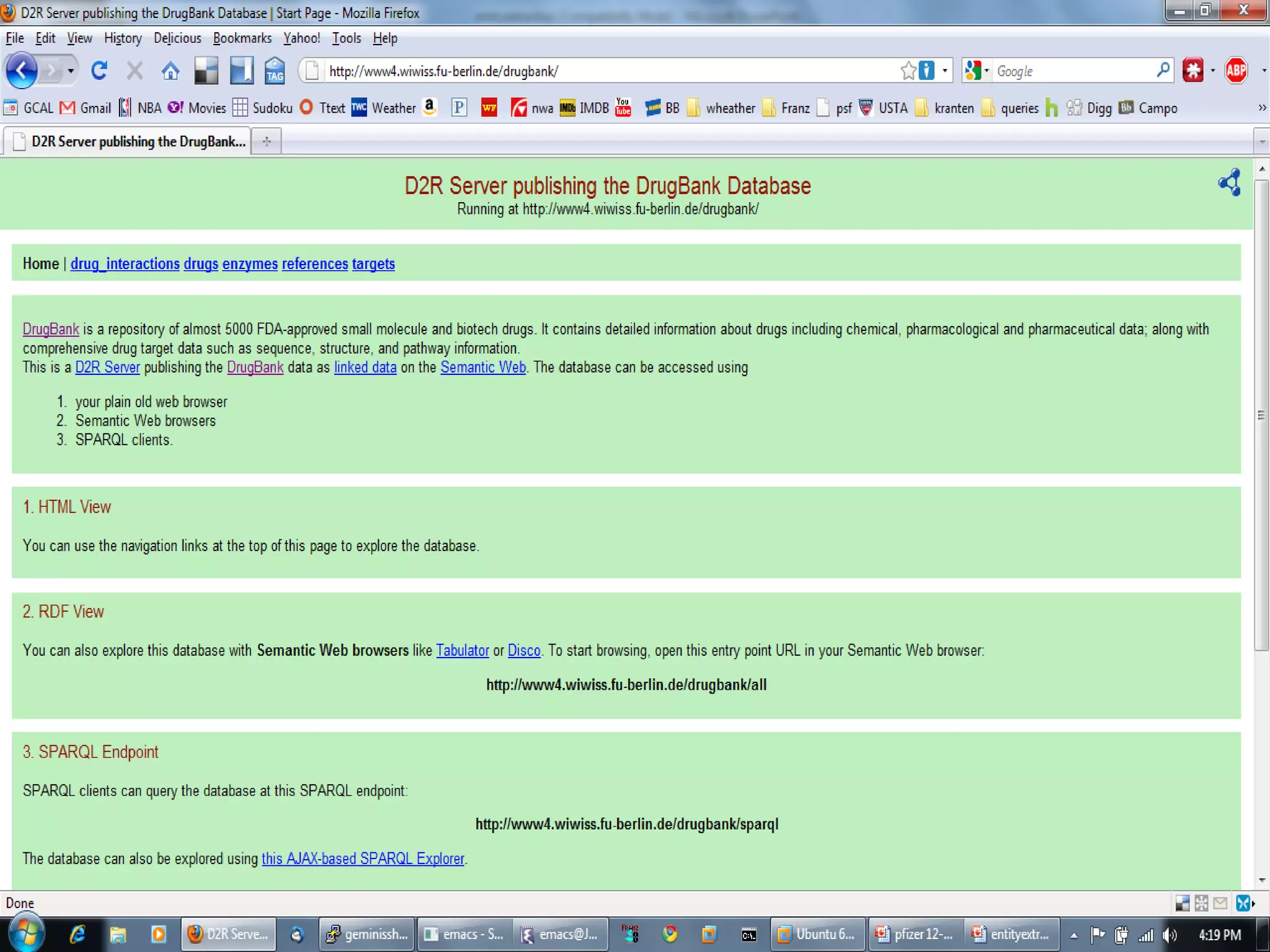
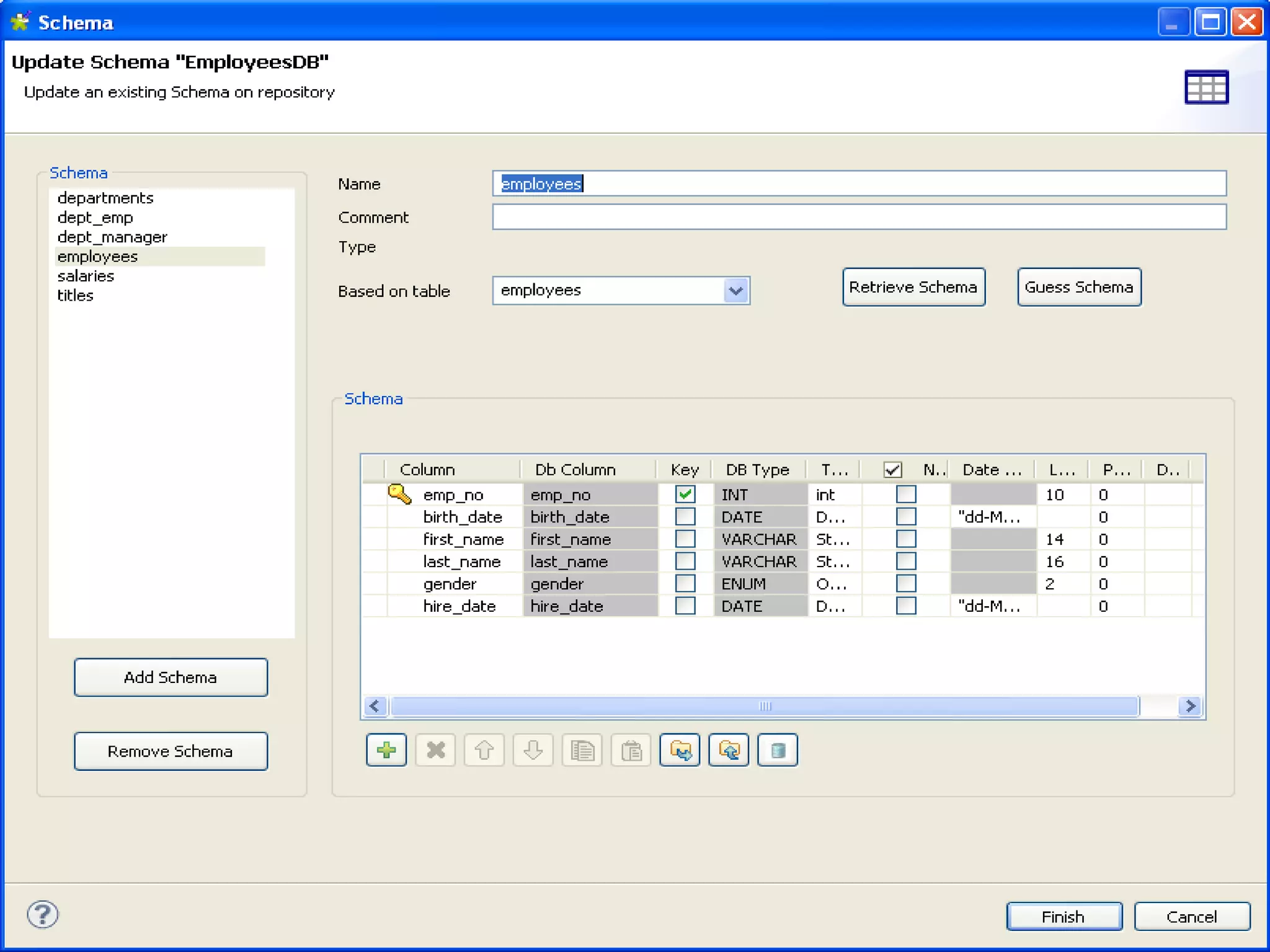
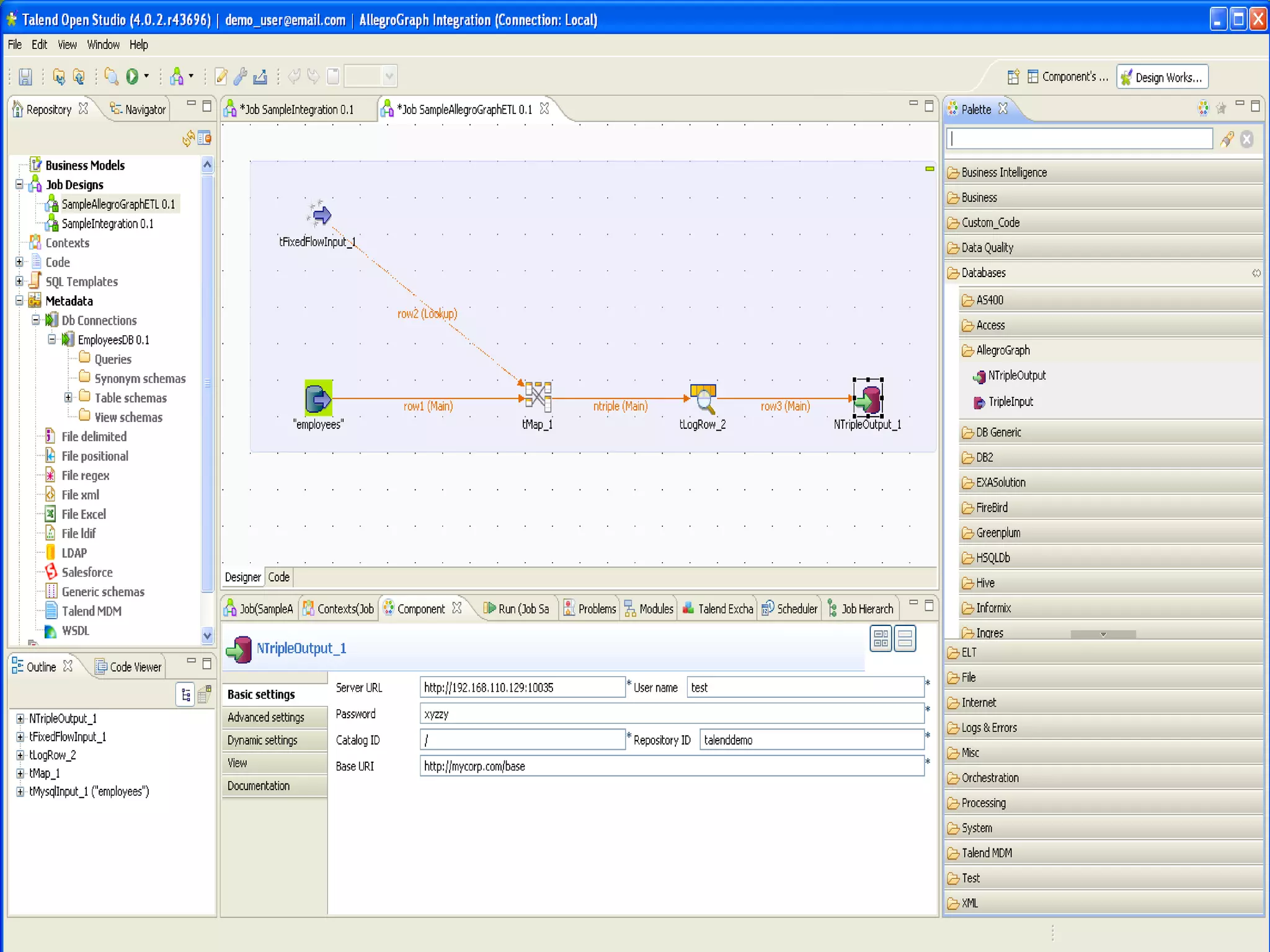
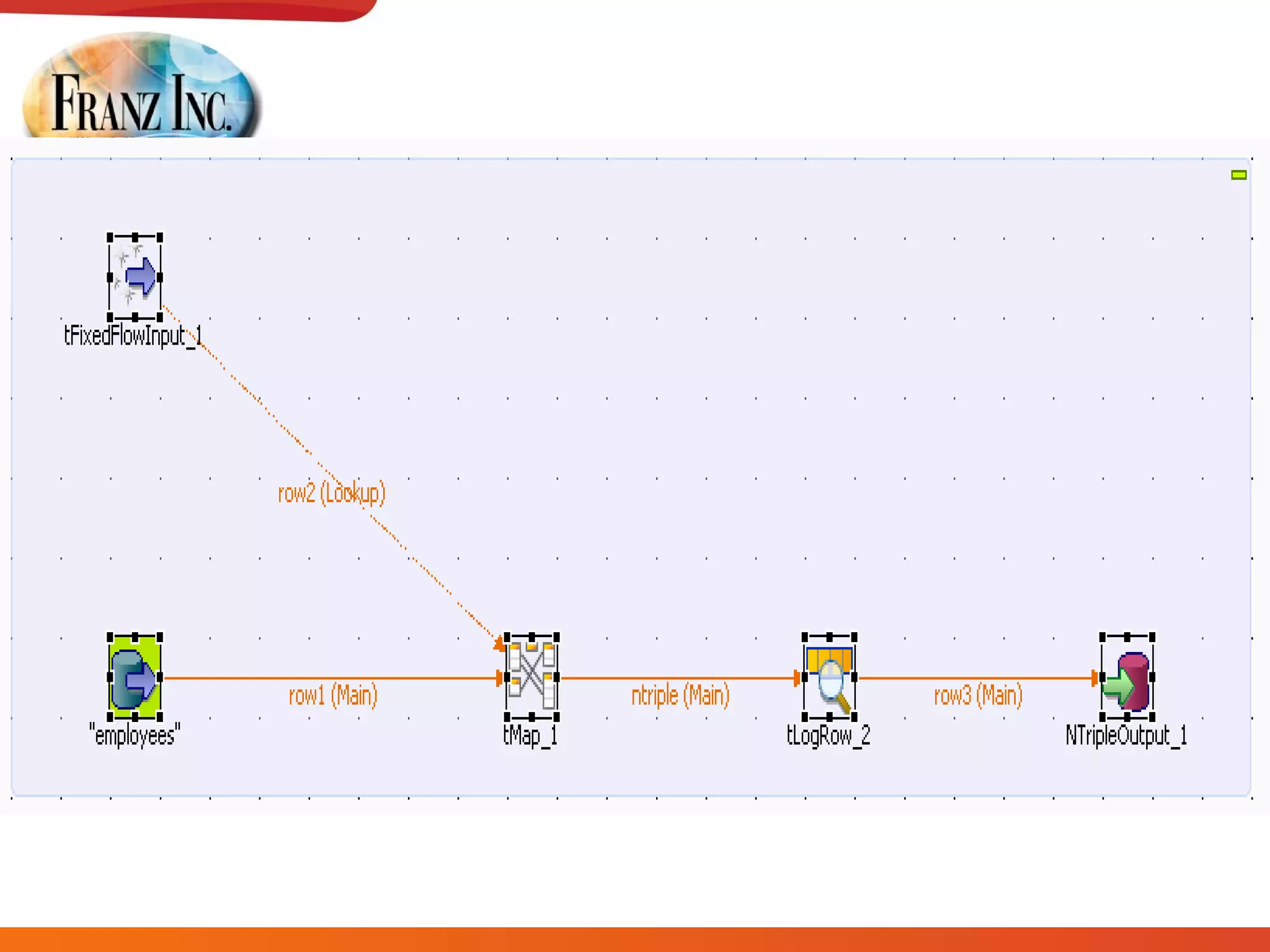
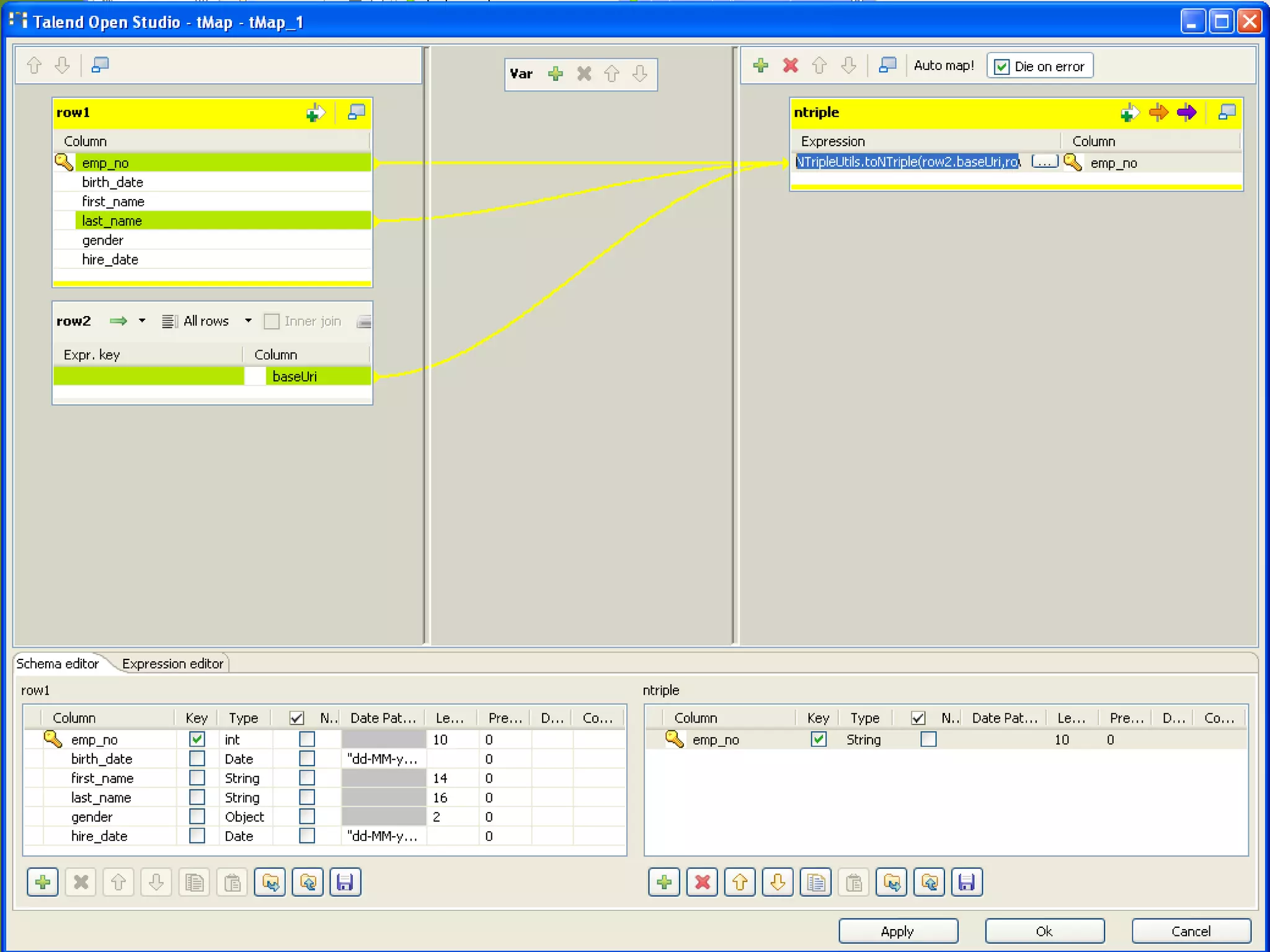
The document discusses semantic technology, focusing on triples and metadata, and how they differ from traditional relational databases (RDBs). It explores the uses of triple stores in various applications, including linked open data and entity extraction, while outlining the capabilities and advantages of specific tools such as AllegroGraph and the challenges associated with big data. Additionally, it touches on the role of semantic technologies in modern IT trends and the application of spatial, temporal, and social network analysis.

















































































