Downloaded 205 times















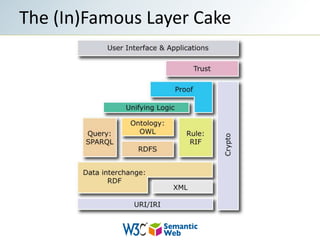











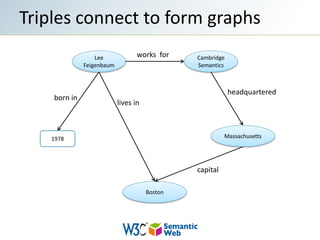































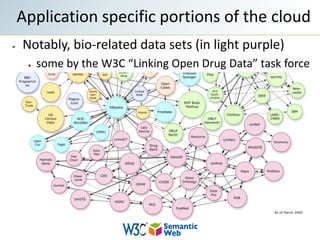































The document provides an overview of semantic web technologies and their application in fields like drug discovery and life sciences. It discusses the integration of disparate data sources through standards like RDF and SPARQL to enable effective data querying and interoperability. Additionally, it highlights the challenges in implementing these technologies, including a shortage of skilled professionals and the need for clear messaging.























![[Conference] Cognitive Graph Analytics on Company Data and News](https://cdn.slidesharecdn.com/ss_thumbnails/texas-data-day18-kiryakov-180131105058-thumbnail.jpg?width=640&height=640&fit=bounds)
















































