Download as PDF, PPTX
![[course site]
Xavier Giro-i-Nieto
xavier.giro@upc.edu
Associate Professor
Universitat Politecnica de Catalunya
Technical University of Catalonia
Image Classification
on ImageNet
#DLUPC](https://image.slidesharecdn.com/dlcv2017d1l4imageclassificationonimagenet-170621134738/85/Image-classification-on-Imagenet-D1L4-2017-UPC-Deep-Learning-for-Computer-Vision-1-320.jpg)
![[course site]
Xavier Giro-i-Nieto
xavier.giro@upc.edu
Associate Professor
Universitat Politecnica de Catalunya
Technical University of Catalonia
Image Classification
on ImageNet
#DLUPC](https://image.slidesharecdn.com/dlcv2017d1l4imageclassificationonimagenet-170621134738/75/Image-classification-on-Imagenet-D1L4-2017-UPC-Deep-Learning-for-Computer-Vision-1-2048.jpg)

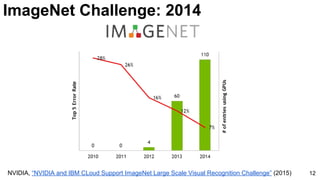
![3
Russakovsky, Olga, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang et al. "Imagenet
large scale visual recognition challenge." International Journal of Computer Vision 115, no. 3 (2015): 211-252. [web]
ImageNet Dataset](https://image.slidesharecdn.com/dlcv2017d1l4imageclassificationonimagenet-170621134738/85/Image-classification-on-Imagenet-D1L4-2017-UPC-Deep-Learning-for-Computer-Vision-3-320.jpg)
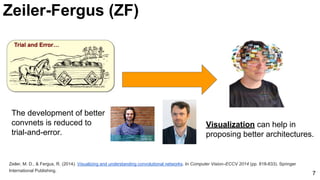
![Slide credit:
Rob Fergus (NYU)
-9.8%
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., ... & Fei-Fei, L. (2014). Imagenet large scale visual recognition challenge. arXiv
preprint arXiv:1409.0575. [web] 4
Based on SIFT + Fisher Vectors
ImageNet Challenge: 2012](https://image.slidesharecdn.com/dlcv2017d1l4imageclassificationonimagenet-170621134738/85/Image-classification-on-Imagenet-D1L4-2017-UPC-Deep-Learning-for-Computer-Vision-4-320.jpg)
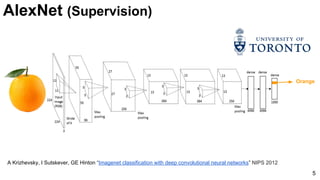
![ImageNet Classification 2013
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., ... & Fei-Fei, L. (2015). Imagenet large scale visual recognition challenge. arXiv
preprint arXiv:1409.0575. [web]
Slide credit:
Rob Fergus (NYU)
6
ImageNet Challenge: 2013](https://image.slidesharecdn.com/dlcv2017d1l4imageclassificationonimagenet-170621134738/85/Image-classification-on-Imagenet-D1L4-2017-UPC-Deep-Learning-for-Computer-Vision-6-320.jpg)

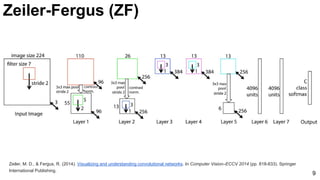
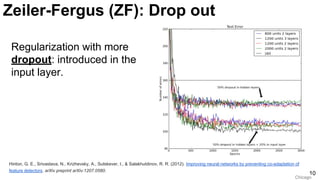
![ImageNet Classification 2013
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., ... & Fei-Fei, L. (2015). Imagenet large scale visual recognition challenge. arXiv
preprint arXiv:1409.0575. [web]
-5%
11
ImageNet Challenge: 2013](https://image.slidesharecdn.com/dlcv2017d1l4imageclassificationonimagenet-170621134738/85/Image-classification-on-Imagenet-D1L4-2017-UPC-Deep-Learning-for-Computer-Vision-11-320.jpg)


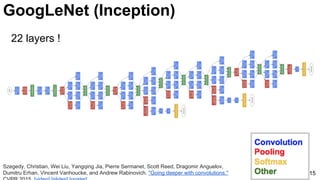
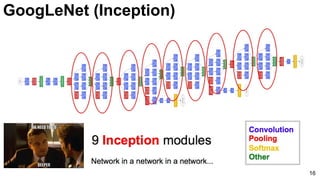
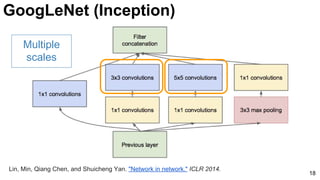
![GoogLeNet (NiN)
19
3x3 and 5x5 convolutions deal
with different scales.
Lin, Min, Qiang Chen, and Shuicheng Yan. "Network in network." ICLR 2014. [Slides]](https://image.slidesharecdn.com/dlcv2017d1l4imageclassificationonimagenet-170621134738/85/Image-classification-on-Imagenet-D1L4-2017-UPC-Deep-Learning-for-Computer-Vision-19-320.jpg)
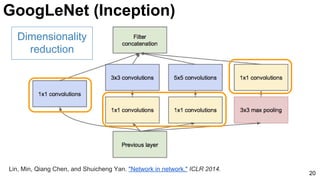
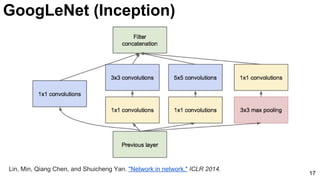
![21
1x1 convolutions does dimensionality
reduction (c3<c2) and accounts for rectified
linear units (ReLU).
Lin, Min, Qiang Chen, and Shuicheng Yan. "Network in network." ICLR 2014. [Slides]
GoogLeNet (Inception)](https://image.slidesharecdn.com/dlcv2017d1l4imageclassificationonimagenet-170621134738/85/Image-classification-on-Imagenet-D1L4-2017-UPC-Deep-Learning-for-Computer-Vision-21-320.jpg)
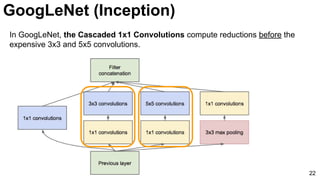
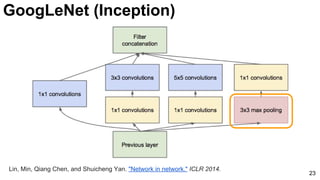
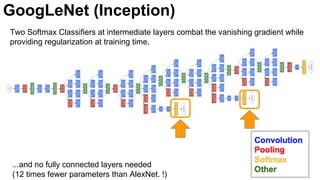
![25
Szegedy, Christian, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent
Vanhoucke, and Andrew Rabinovich. "Going deeper with convolutions." CVPR 2015. [video] [slides] [poster]
GoogLeNet (Inception)](https://image.slidesharecdn.com/dlcv2017d1l4imageclassificationonimagenet-170621134738/85/Image-classification-on-Imagenet-D1L4-2017-UPC-Deep-Learning-for-Computer-Vision-25-320.jpg)
![E2E: Classification: VGG
26
Simonyan, Karen, and Andrew Zisserman. "Very deep convolutional networks for large-scale image recognition." ICLR 2015.
[video] [slides] [project]](https://image.slidesharecdn.com/dlcv2017d1l4imageclassificationonimagenet-170621134738/85/Image-classification-on-Imagenet-D1L4-2017-UPC-Deep-Learning-for-Computer-Vision-26-320.jpg)
![E2E: Classification: VGG
27
Simonyan, Karen, and Andrew Zisserman. "Very deep convolutional networks for large-scale image recognition."
International Conference on Learning Representations (2015). [video] [slides] [project]](https://image.slidesharecdn.com/dlcv2017d1l4imageclassificationonimagenet-170621134738/85/Image-classification-on-Imagenet-D1L4-2017-UPC-Deep-Learning-for-Computer-Vision-27-320.jpg)
![E2E: Classification: VGG: 3x3 Stacks
28
Simonyan, Karen, and Andrew Zisserman. "Very deep convolutional networks for large-scale image
recognition." International Conference on Learning Representations (2015). [video] [slides] [project]](https://image.slidesharecdn.com/dlcv2017d1l4imageclassificationonimagenet-170621134738/85/Image-classification-on-Imagenet-D1L4-2017-UPC-Deep-Learning-for-Computer-Vision-28-320.jpg)
![E2E: Classification: VGG
29
Simonyan, Karen, and Andrew Zisserman. "Very deep convolutional networks for large-scale image
recognition." International Conference on Learning Representations (2015). [video] [slides] [project]
● No poolings between some convolutional layers.
● Convolution strides of 1 (no skipping).](https://image.slidesharecdn.com/dlcv2017d1l4imageclassificationonimagenet-170621134738/85/Image-classification-on-Imagenet-D1L4-2017-UPC-Deep-Learning-for-Computer-Vision-29-320.jpg)

![E2E: Classification: ResNet
31
He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. "Deep residual learning for image recognition."
CVPR 2016. [slides]](https://image.slidesharecdn.com/dlcv2017d1l4imageclassificationonimagenet-170621134738/85/Image-classification-on-Imagenet-D1L4-2017-UPC-Deep-Learning-for-Computer-Vision-31-320.jpg)
![E2E: Classification: ResNet
32
● Deeper networks (34 is deeper than 18) are more difficult to train.
Thin curves: training error
Bold curves: validation error
He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. "Deep residual learning for image recognition."
CVPR 2016. [slides]](https://image.slidesharecdn.com/dlcv2017d1l4imageclassificationonimagenet-170621134738/85/Image-classification-on-Imagenet-D1L4-2017-UPC-Deep-Learning-for-Computer-Vision-32-320.jpg)
![ResNet
33
● Residual learning: reformulate the layers as learning residual functions with
reference to the layer inputs, instead of learning unreferenced functions
He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. "Deep residual learning for image recognition."
CVPR 2016. [slides]](https://image.slidesharecdn.com/dlcv2017d1l4imageclassificationonimagenet-170621134738/85/Image-classification-on-Imagenet-D1L4-2017-UPC-Deep-Learning-for-Computer-Vision-33-320.jpg)
![E2E: Classification: ResNet
34
He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. "Deep residual learning for image recognition."
CVPR 2016. [slides]](https://image.slidesharecdn.com/dlcv2017d1l4imageclassificationonimagenet-170621134738/85/Image-classification-on-Imagenet-D1L4-2017-UPC-Deep-Learning-for-Computer-Vision-34-320.jpg)
![35
Learn more
Li Fei-Fei, “How we’re teaching computers to understand
pictures” TEDTalks 2014.
Russakovsky, Olga, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang et al. "Imagenet
large scale visual recognition challenge." International Journal of Computer Vision 115, no. 3 (2015): 211-252. [web]](https://image.slidesharecdn.com/dlcv2017d1l4imageclassificationonimagenet-170621134738/85/Image-classification-on-Imagenet-D1L4-2017-UPC-Deep-Learning-for-Computer-Vision-35-320.jpg)



The document presents an overview of the ImageNet Challenge, which involves classifying images across 1,000 object categories using a large dataset with 1.2 million training images and 100,000 test images. It discusses advancements in convolutional neural networks (CNNs) such as AlexNet, GoogLeNet, and ResNet, highlighting their architectures and innovations that improved image classification performance. Additionally, it references key research papers and methodologies that contributed to these developments in deep learning for visual recognition.




![ViT (Vision Transformer) Review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/vitreviewcdm-201012184226-thumbnail.jpg?width=640&height=640&fit=bounds)































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)

















