Downloaded 35 times
















![This is where the Magic Happens
public class MaxTemperatureDriver extends Configured implements Tool {
@Override
Job job = new Job(getConf(), "Max temperature");
job.setJarByClass(getClass());
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setMapperClass(MaxTemperatureMapper.class);
job.setCombinerClass(MaxTemperatureReducer.class);
job.setReducerClass(MaxTemperatureReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new MaxTemperatureDriver(), args);
System.exit(exitCode);
}
}](https://image.slidesharecdn.com/runningmapreduceprogramsinclouds-150310185627-conversion-gate01/75/Optimal-Execution-Of-MapReduce-Jobs-In-Cloud-Voices-2015-24-2048.jpg)


















![References
[1] E. Bortnikov, A. Frank, E. Hillel, and S. Rao, “Predicting execution bottlenecks in map-
reduce clusters” In Proc. of the 4th USENIX conference on Hot Topics in Cloud computing,
2012.
[2] R. Buyya, S. K. Garg, and R. N. Calheiros, “SLA-Oriented Resource Provisioning for Cloud
Computing: Challenges, Architecture, and Solutions” In International Conference on Cloud and
Service Computing, 2011.
[3] S. Chaisiri, Bu-Sung Lee, and D. Niyato, “Optimization of Resource Provisioning Cost in
Cloud Computing” in Transactions On Service Computing, Vol. 5, No. 2, IEEE, April-June 2012
[4] L Cherkasova and R.H. Campbell, “Resource Provisioning Framework for MapReduce Jobs
with Performance Goals”, in Middleware 2011, LNCS 7049, pp. 165–186, 2011
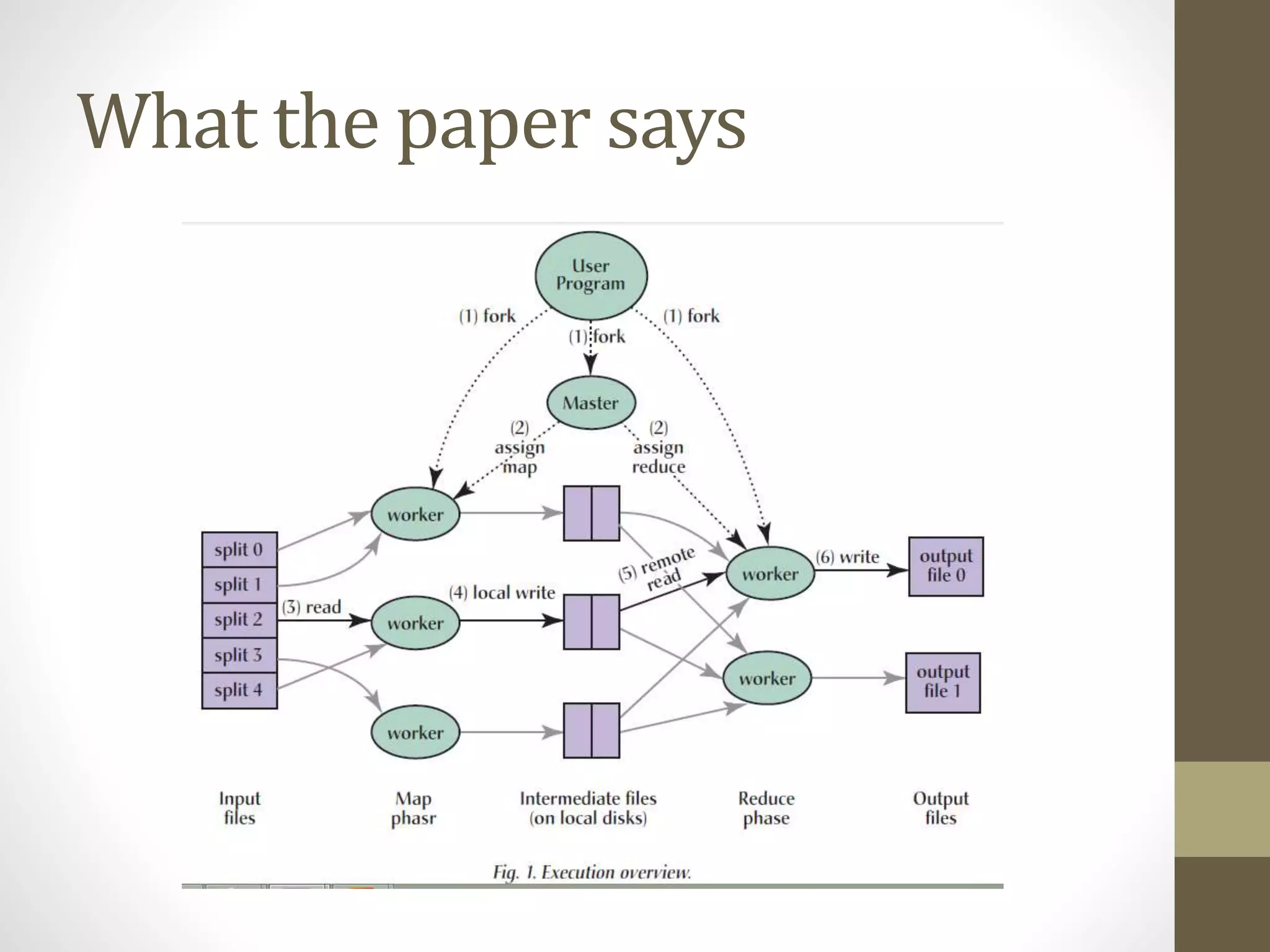
[5] J. Dean, and S. Ghemawat, “MapReduce: Simplified Data Processing on Large Clusters”,
Communications of the ACM, Jan 2008
[6] Y. Hu, J. Wong, G. Iszlai, and M. Litoiu, “Resource Provisioning for Cloud Computing” In
Proc. of the 2009 Conference of the Center for Advanced Studies on Collaborative Research,
2009.
[7] K. Kambatla, A. Pathak, and H. Pucha, “Towards optimizing hadoop provisioning in the
cloud in Proc. of the First Workshop on Hot Topics in Cloud Computing, 2009
[8] Kuyoro S. O., Ibikunle F. and Awodele O., “Cloud Computing Security Issues and
Challenges” in International Journal of Computer Networks (IJCN), Vol. 3, Issue 5, 2011](https://image.slidesharecdn.com/runningmapreduceprogramsinclouds-150310185627-conversion-gate01/75/Optimal-Execution-Of-MapReduce-Jobs-In-Cloud-Voices-2015-48-2048.jpg)


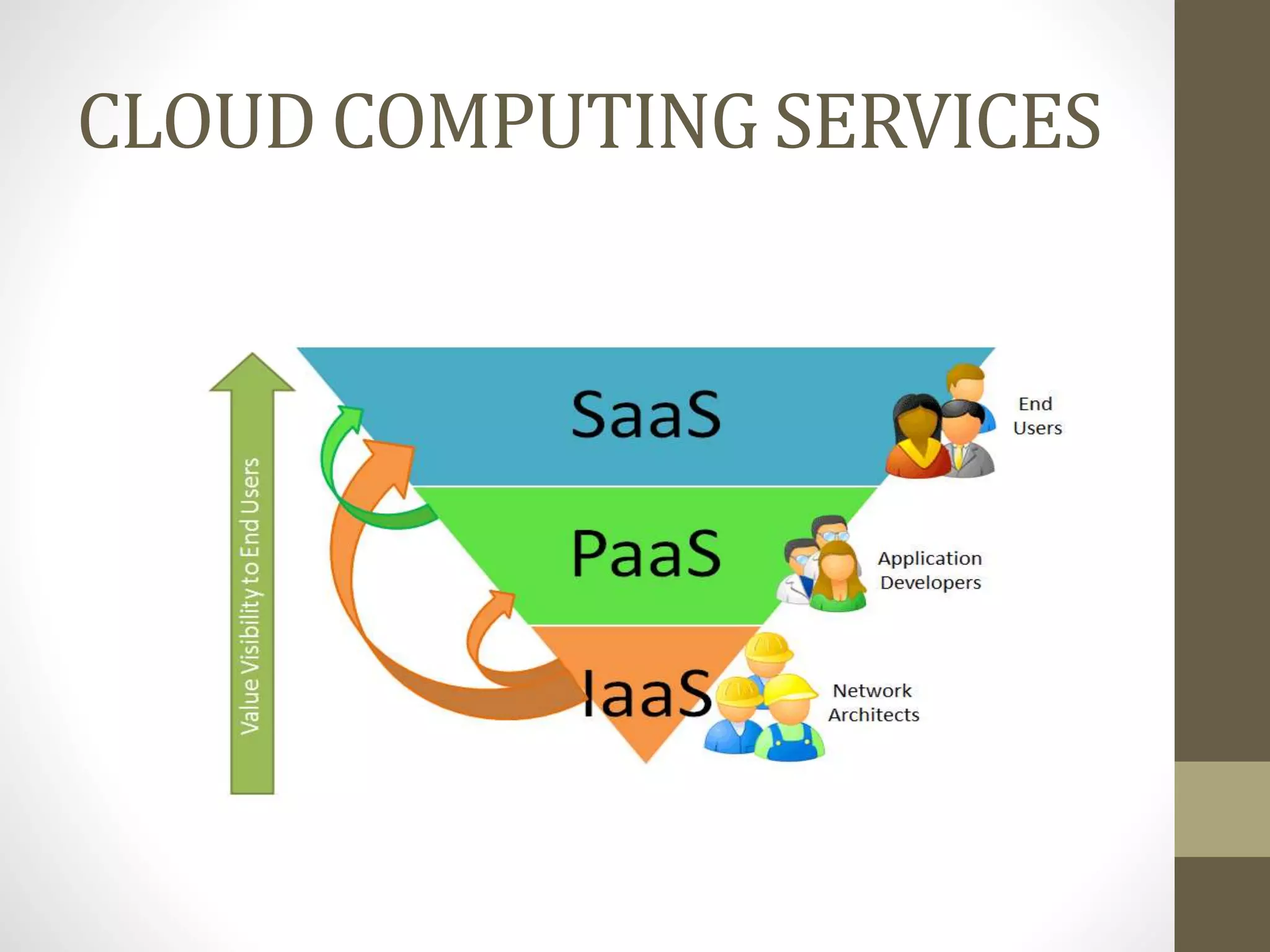
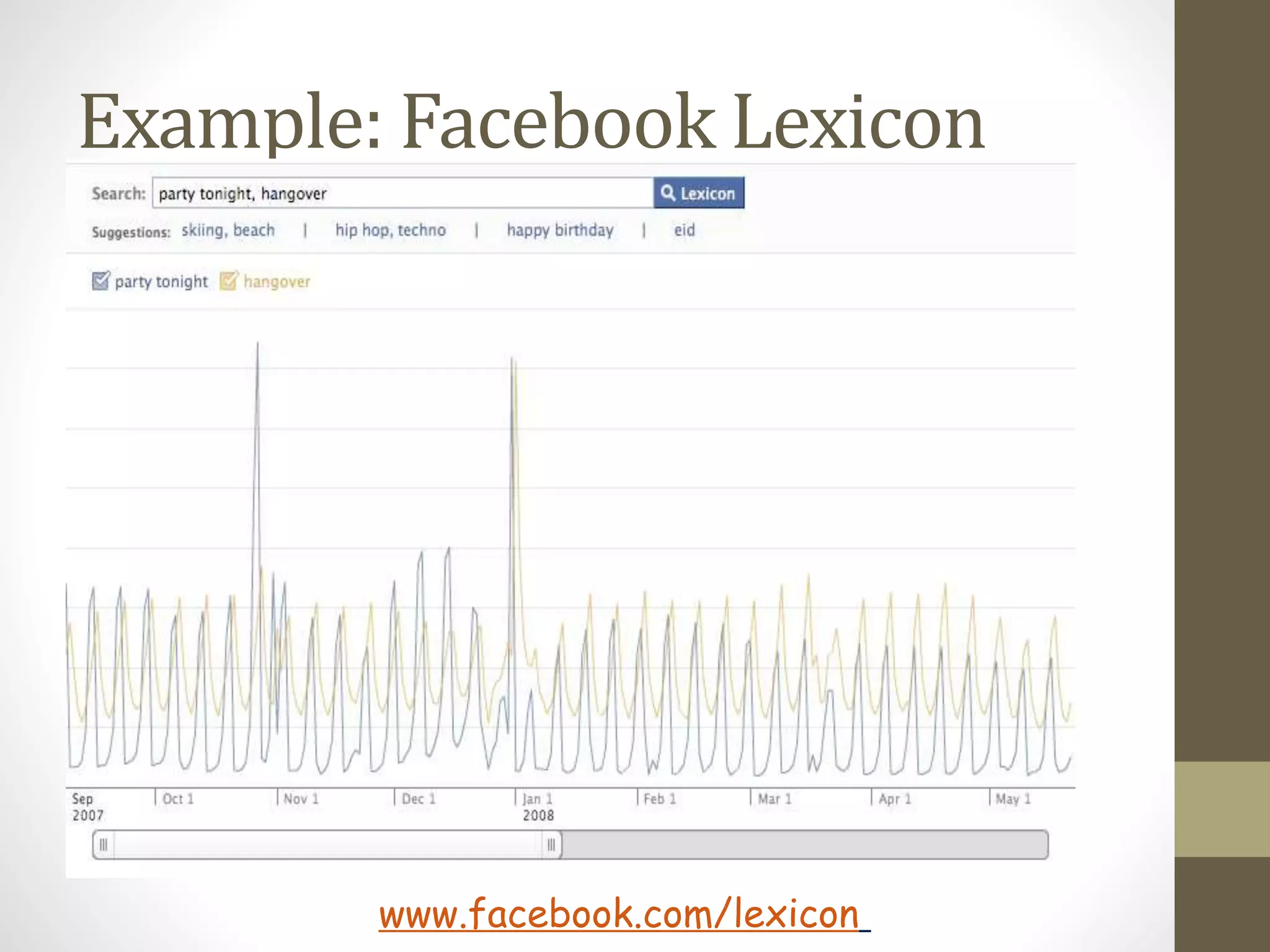
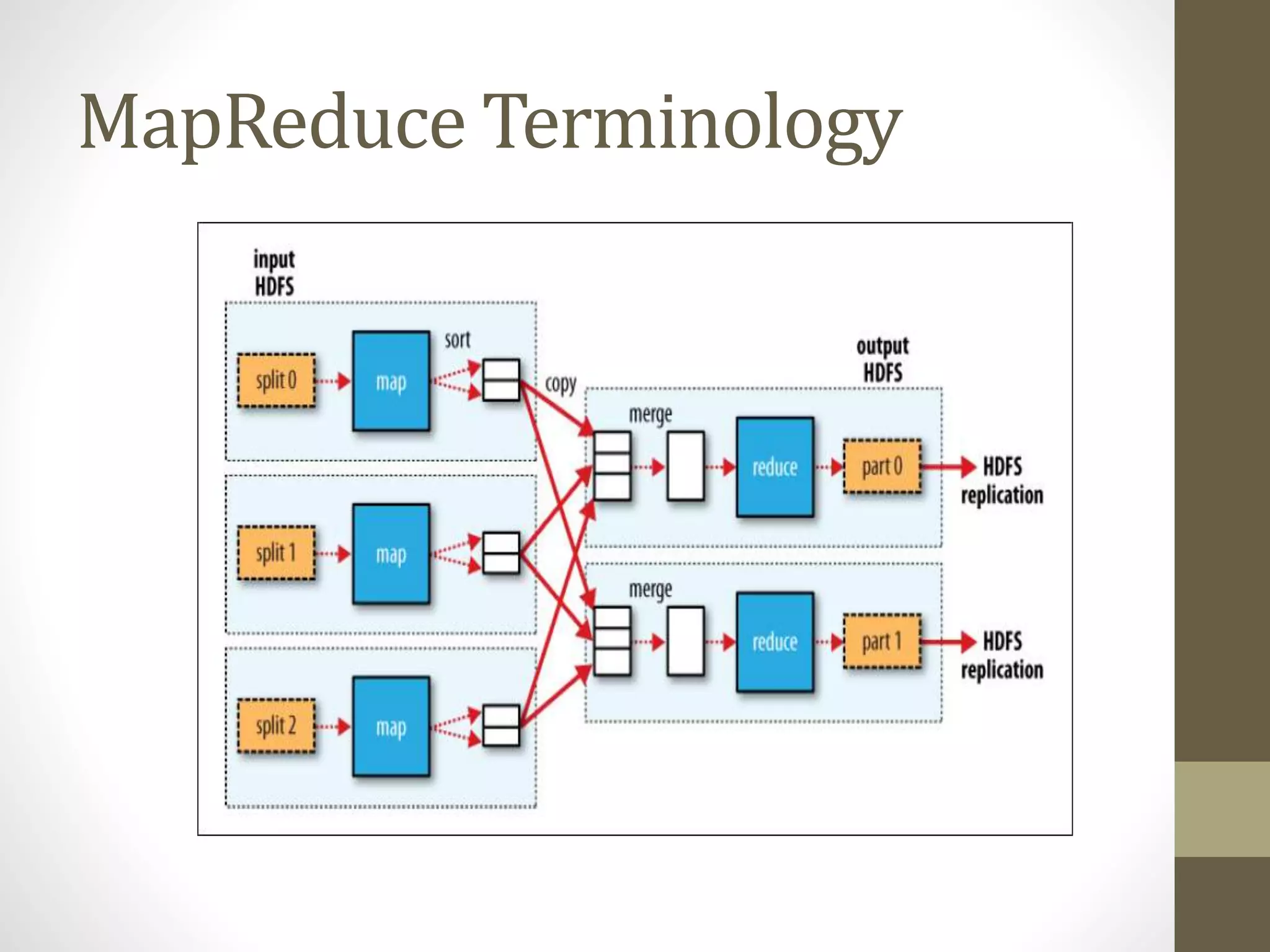
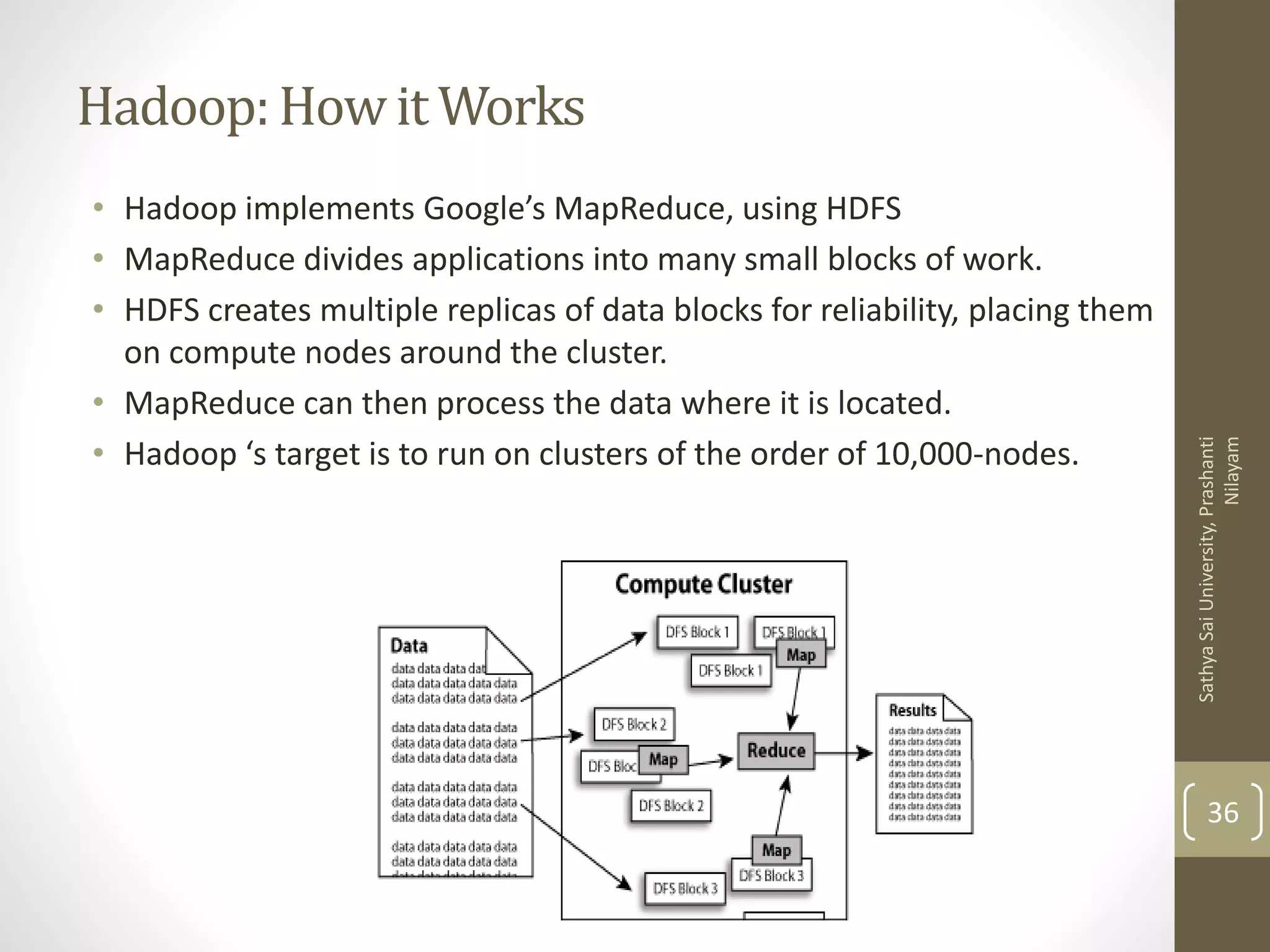
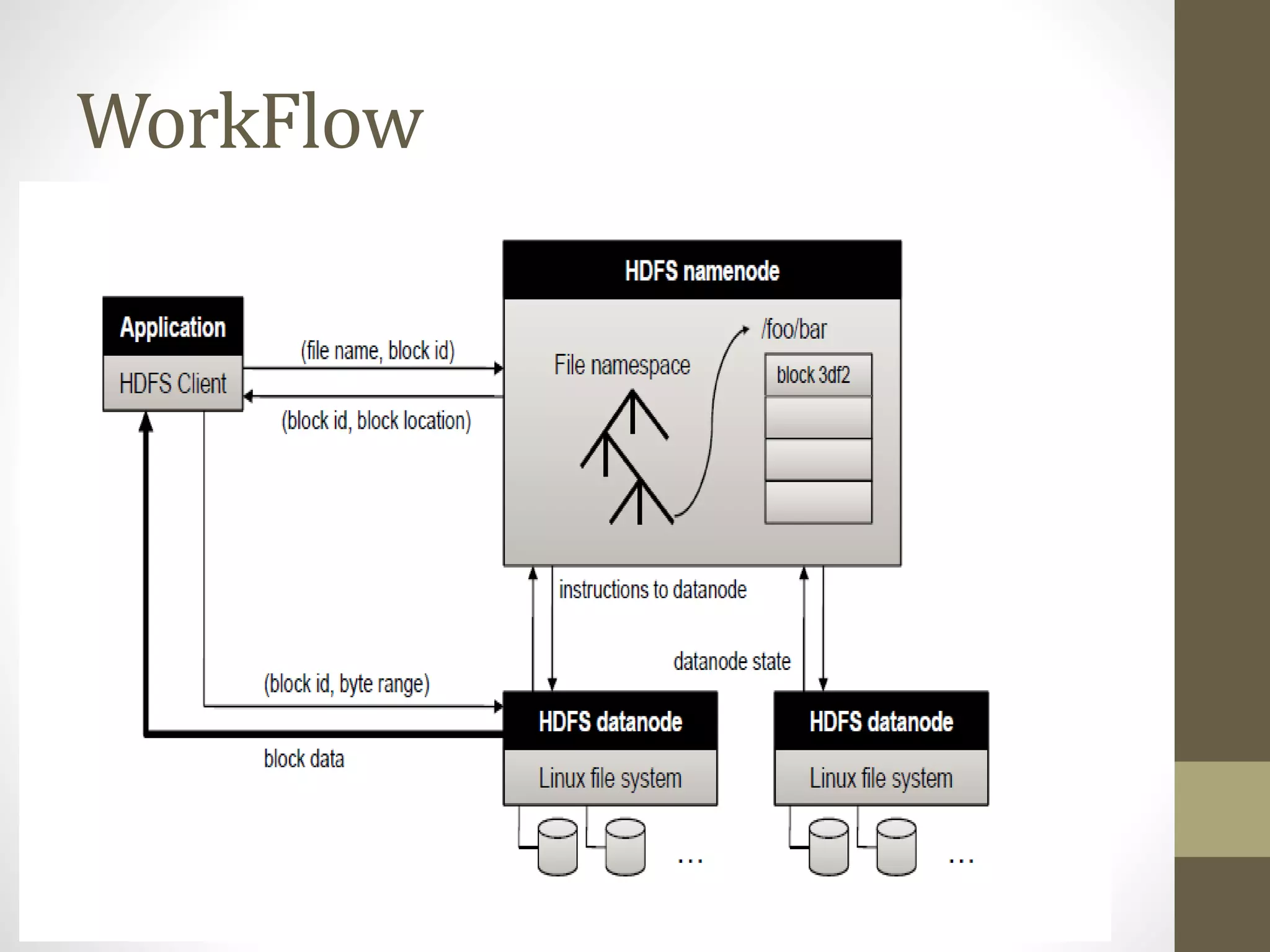
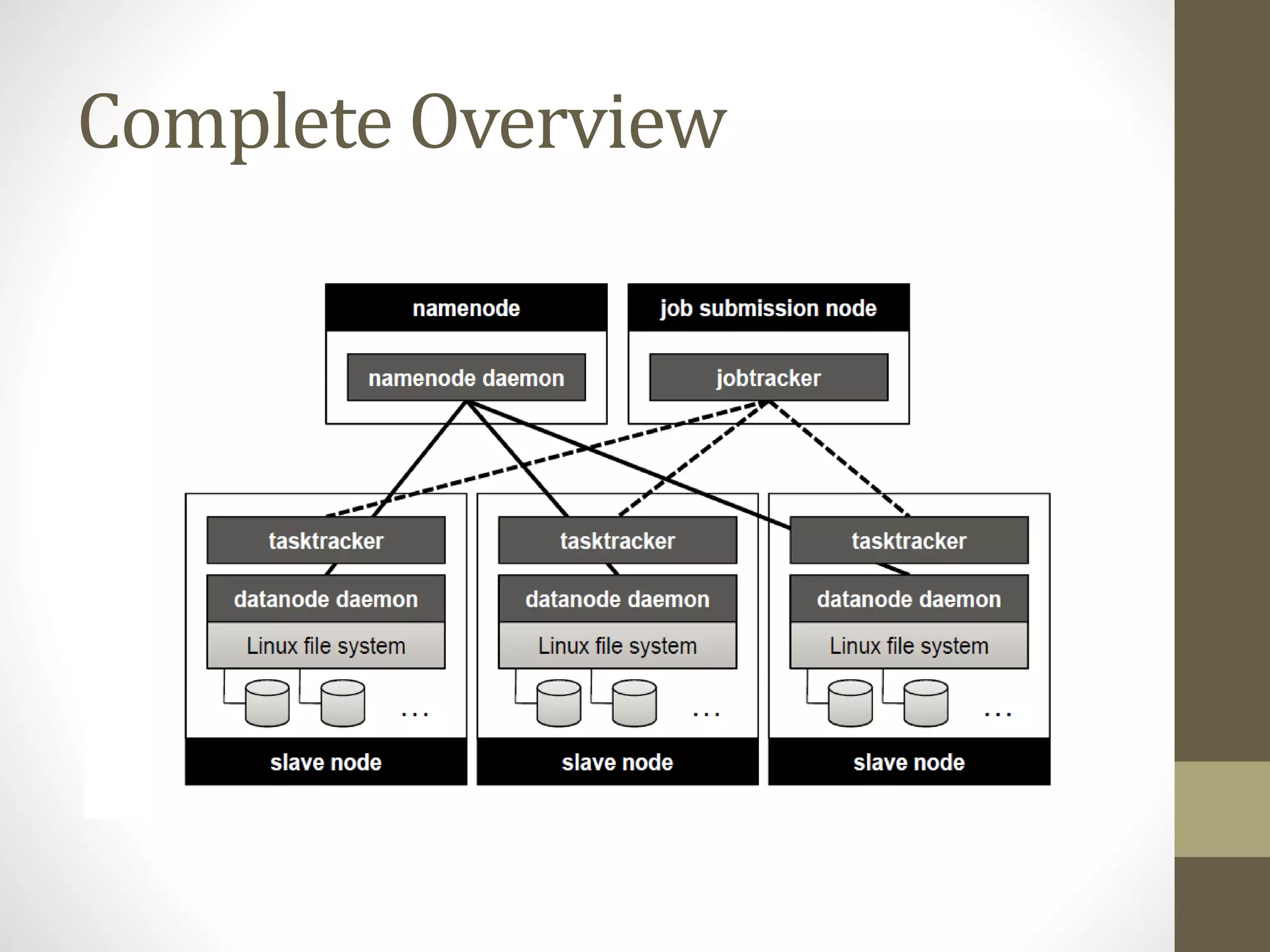
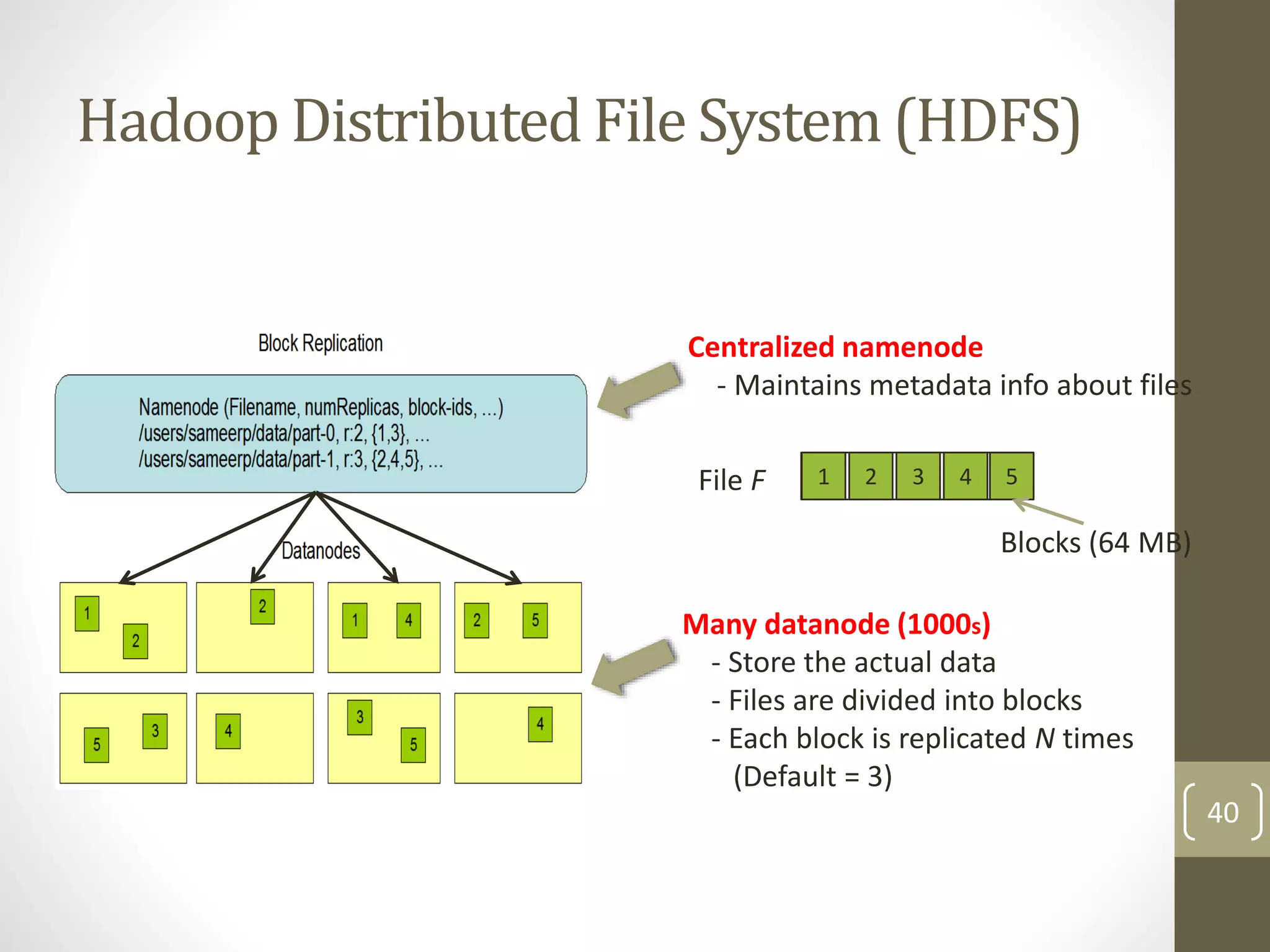
The document outlines the MapReduce programming model and its integration with cloud computing, highlighting its scalability and fault-tolerance features pioneered by Google and popularized through the Hadoop project. It details how MapReduce processes large datasets across distributed systems, including examples of its applications at major companies like Google, Yahoo, and Facebook. Additionally, it discusses the architecture of Hadoop, its components, and the significance of resource provisioning for optimizing MapReduce jobs in a cloud environment.



























![Resource Aware Scheduling for Hadoop [Final Presentation]](https://cdn.slidesharecdn.com/ss_thumbnails/fyppresentationfinal-120226092754-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)






























































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)















