Downloaded 95 times










![DF from RDD
• 先轉成RDD
scala> val data = sc.textFile("hdfs://localhost:54310/user/hadoop/ml-
100k/u.data")
• 建立case class
case class Rattings(userId: Int, itemID: Int, rating: Int, timestmap:String)
• 轉成Data Frame
scala> val ratting = data.map(_.split("t")).map(p => Rattings(p(0).trim.toInt,
p(1).trim.toInt, p(2).trim.toInt, p(3))).toDF()
ratting: org.apache.spark.sql.DataFrame = [userId: int, itemID: int, rating: int,
timestmap: string]](https://image.slidesharecdn.com/sparksql-151205142934-lva1-app6892/85/Spark-Sql-for-Training-14-320.jpg)

![Dataframe Operations
• Show()
userId itemID rating timestmap
196 242 3 881250949
186 302 3 891717742
22 377 1 878887116
244 51 2 880606923
253 465 5 891628467
• head(5)
res11: Array[org.apache.spark.sql.Row] =
Array([196,242,3,881250949], [186,302,3,891717742],
[22,377,1,878887116], [244,51,2,880606923],
[166,346,1,886397596])](https://image.slidesharecdn.com/sparksql-151205142934-lva1-app6892/85/Spark-Sql-for-Training-16-320.jpg)









![DF支援RDD操作
• MAP
scala> result.map(t => "user:" + t(0)).collect().foreach(println)
• 取出來的物件型態是Any
scala> ratting.map(t => t(2)).take(5)
• 先轉string再轉int
scala> ratting.map(t => Array(t(0),t(2).toString.toInt *
10)).take(5)
res130: Array[Array[Any]] = Array(Array(196, 30), Array(186,
30), Array(22, 10), Array(244, 20), Array(166, 10))](https://image.slidesharecdn.com/sparksql-151205142934-lva1-app6892/85/Spark-Sql-for-Training-26-320.jpg)








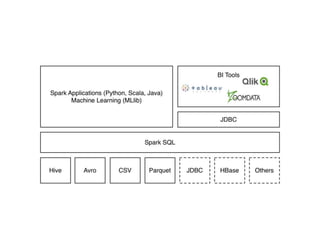


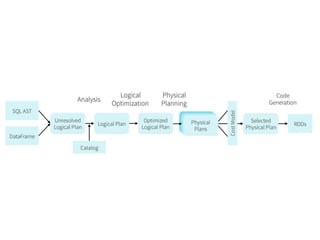
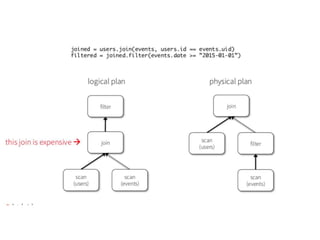
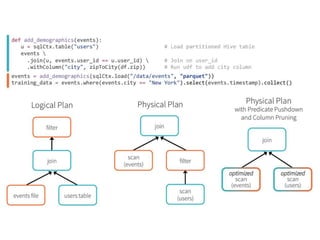
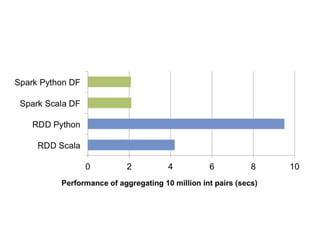
The document covers an introduction to Spark SQL, including the use of SQLContext and HiveContext for data analysis. It provides details on creating DataFrames from RDDs and JSON, various DataFrame operations like select, filter, and group by, as well as saving data. Additionally, it discusses user-defined functions and data types supported in Spark SQL.















































































