Download as PDF, PPTX
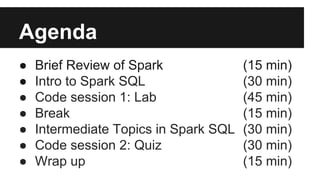
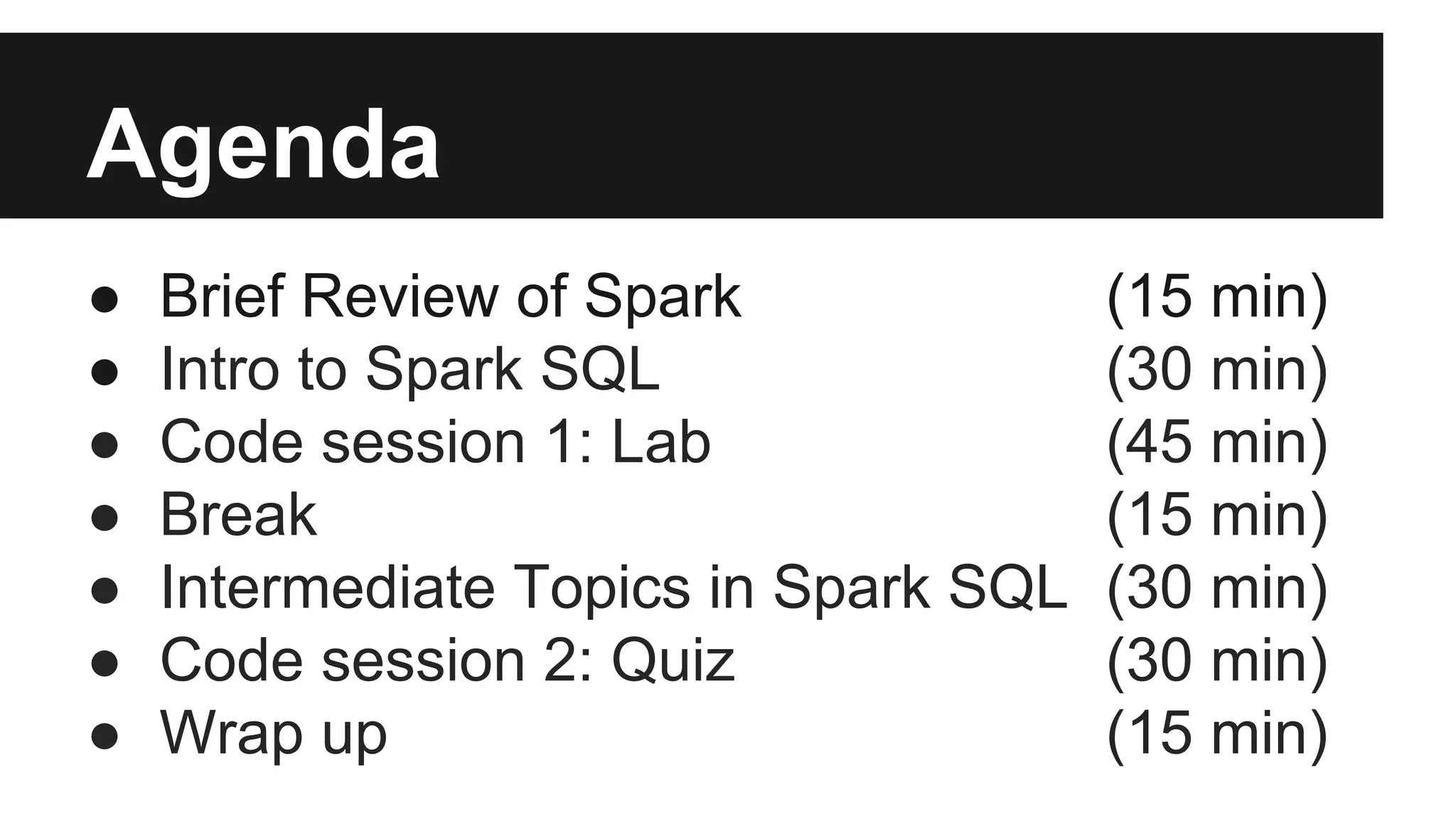

























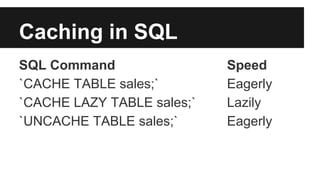












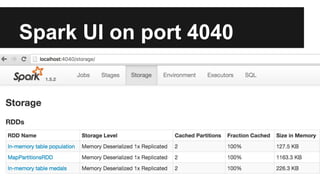

The document outlines an agenda for an Apache Spark workshop, including topics such as Spark SQL, RDD operations, and user-defined functions (UDFs). It discusses the framework's features, advantages of using schemas in Spark SQL, and practical coding sessions. Additionally, the document addresses caching data and different data formats for reading and writing within Spark, emphasizing efficiency and productivity for developers and data scientists.












































![Fun[ctional] spark with scala](https://cdn.slidesharecdn.com/ss_thumbnails/functionalsparkwithscala-160614075814-thumbnail.jpg?width=640&height=640&fit=bounds)































![DataEngConf SF16 - BYOMQ: Why We [re]Built IronMQ](https://cdn.slidesharecdn.com/ss_thumbnails/byomq-160414230807-thumbnail.jpg?width=640&height=640&fit=bounds)






























