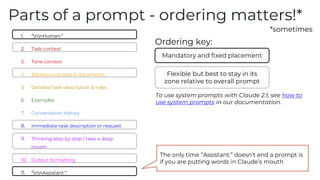
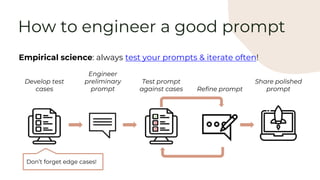
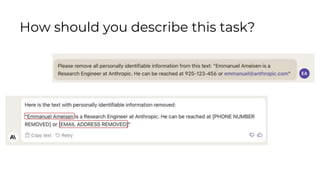
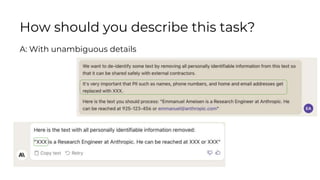
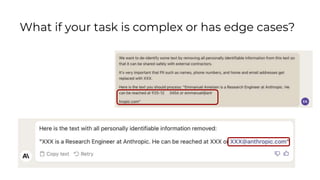
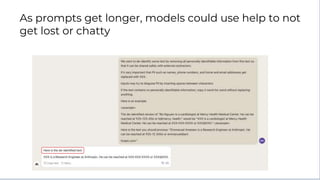
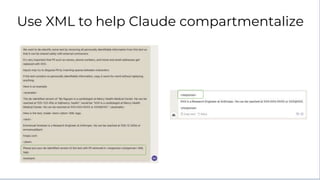
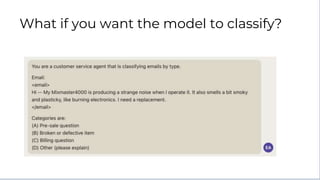
Here is some text with PII:
"Emmanuel Ameisen is a Research Engineer at Anthropic. He can be reached at 925-123-456 or emmanuel@anthropic.com"
Please remove all personally identifiable information (PII) from the text. PII includes things like names, email addresses, phone numbers, etc.
How would you rewrite the text with all PII removed?

![“Human:” / “Assistant:” formatting
● Claude is trained on
alternating “Human:” /
“Assistant:” dialogue:
○ Human: [Instructions]
○ Assistant: [Claude’s
response]
● For any API prompt, you must
start with “nnHuman:” and
end with “nnAssistant:”
¶
¶
Human: Why is the sky blue? ¶
¶
Assistant:
Python
prompt = “nnHuman: Why are sunsets
orange?nnAssistant:”
* ¶ symbols above shown for illustration
Examples:
To use system prompts with Claude 2.1, see how to use system
prompts in our documentation.](https://image.slidesharecdn.com/bedrockclaudepromptengineeringtechniques-231213183236-1d873607/85/BEDROCK-Claude-Prompt-Engineering-Techniques-pptx-2-320.jpg)

![● Claude sometimes needs
context about what role it
should inhabit
● Assigning roles changes
Claude’s response in two ways:
○ Improved accuracy in
certain situations (such as
mathematics)
○ Changed tone and
demeanor to match the
specified role
Human: Solve this logic puzzle. {{Puzzle}}
Assistant: [Gives incorrect response]
Example:
Human: You are a master logic bot designed to
answer complex logic problems. Solve this logic
puzzle. {{Puzzle}}
Assistant: [Gives correct response]
Assign roles (aka role prompting)](https://image.slidesharecdn.com/bedrockclaudepromptengineeringtechniques-231213183236-1d873607/85/BEDROCK-Claude-Prompt-Engineering-Techniques-pptx-4-320.jpg)

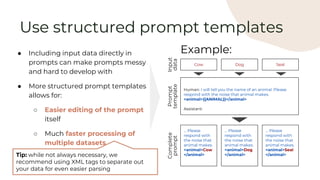


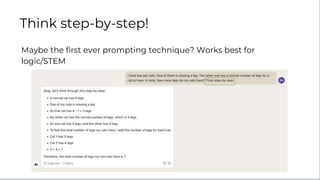
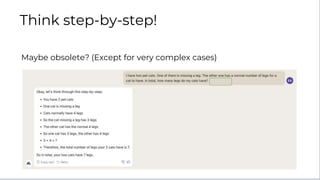
![● Claude benefits from having
time to think through tasks
before executing
● Especially if a task is
particularly complex, tell
Claude to think step by step
before it answers
Human: Here is a complex LSAT multiple-choice logic
puzzle. What is the correct answer?
Assistant: [Gives incorrect response]
Example:
Increases intelligence of responses
but also increases latency by
adding to the length of the output.
Think step by step
Human: Here is a complex LSAT multiple-choice logic
puzzle. What is the correct answer? Think step by step.
Assistant: [Gives correct response]](https://image.slidesharecdn.com/bedrockclaudepromptengineeringtechniques-231213183236-1d873607/85/BEDROCK-Claude-Prompt-Engineering-Techniques-pptx-9-320.jpg)
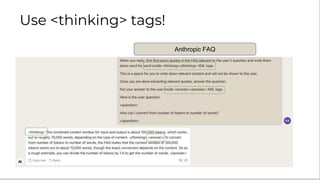
![Human: [rest of prompt] Before answering,
please think about the question within
<thinking></thinking> XML tags. Then,
answer the question within
<answer></answer> XML tags.
Assistant: <thinking>
Thinking out loud:
Think step by step
Human: [rest of prompt] Before answering,
please think about the question within
<thinking></thinking> XML tags. Then,
answer the question within
<answer></answer> XML tags.
Assistant: <thinking>[...some
thoughts]</thinking>
<answer>[some answer]</answer>
Helps with troubleshooting
Claude’s logic & where prompt
instructions may be unclear](https://image.slidesharecdn.com/bedrockclaudepromptengineeringtechniques-231213183236-1d873607/85/BEDROCK-Claude-Prompt-Engineering-Techniques-pptx-10-320.jpg)




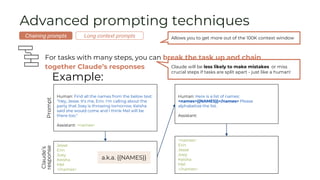

![Advanced prompting techniques
Example long context prompt:
Human: I'm going to give you a document. Read the document carefully, because I'm going to ask you a question about it. Here is
the document: <document>{{TEXT}}</document>
First, find the quotes from the document that are most relevant to answering the question, and then print them in numbered order.
Quotes should be relatively short. If there are no relevant quotes, write "No relevant quotes" instead.
Then, answer the question, starting with "Answer:". Do not include or reference quoted content verbatim in the answer. Don't say
"According to Quote [1]" when answering. Instead make references to quotes relevant to each section of the answer solely by adding
their bracketed numbers at the end of relevant sentences.
Thus, the format of your overall response should look like what's shown between the <examples></examples> tags. Make sure to
follow the formatting and spacing exactly.
<examples>
[Examples of question + answer pairs using parts of the given document, with answers written exactly like how Claude’s output
should be structured]
</examples>
Here is the first question: {{QUESTION}}
If the question cannot be answered by the document, say so.
Assistant:
Long context prompts
Chaining prompts
To implement this via system prompt with Claude 2.1,
see how to use system prompts in our documentation.](https://image.slidesharecdn.com/bedrockclaudepromptengineeringtechniques-231213183236-1d873607/85/BEDROCK-Claude-Prompt-Engineering-Techniques-pptx-17-320.jpg)





































































![Module_3_dbc[1]about ai and eveything and all.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/module3dbc1-260114065315-b2ab6fcd-thumbnail.jpg?width=640&height=640&fit=bounds)















![[Tool] chatscript 사용법](https://cdn.slidesharecdn.com/ss_thumbnails/180604chatscript-190321060146-thumbnail.jpg?width=640&height=640&fit=bounds)
















![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)


