This document discusses vector space word representations, which map words to dense numerical vectors based on their contexts. Words that appear in similar contexts are mapped to vectors with small angles between them. Historical methods included hard and soft clustering, while modern techniques use neural networks like Word2Vec. These representations allow words with similar meanings to have similar vectors, and can be used to solve word analogy problems by performing vector arithmetic. While not perfect, vector representations have improved many NLP tasks such as named entity recognition and sentiment analysis.














![“Magical” property
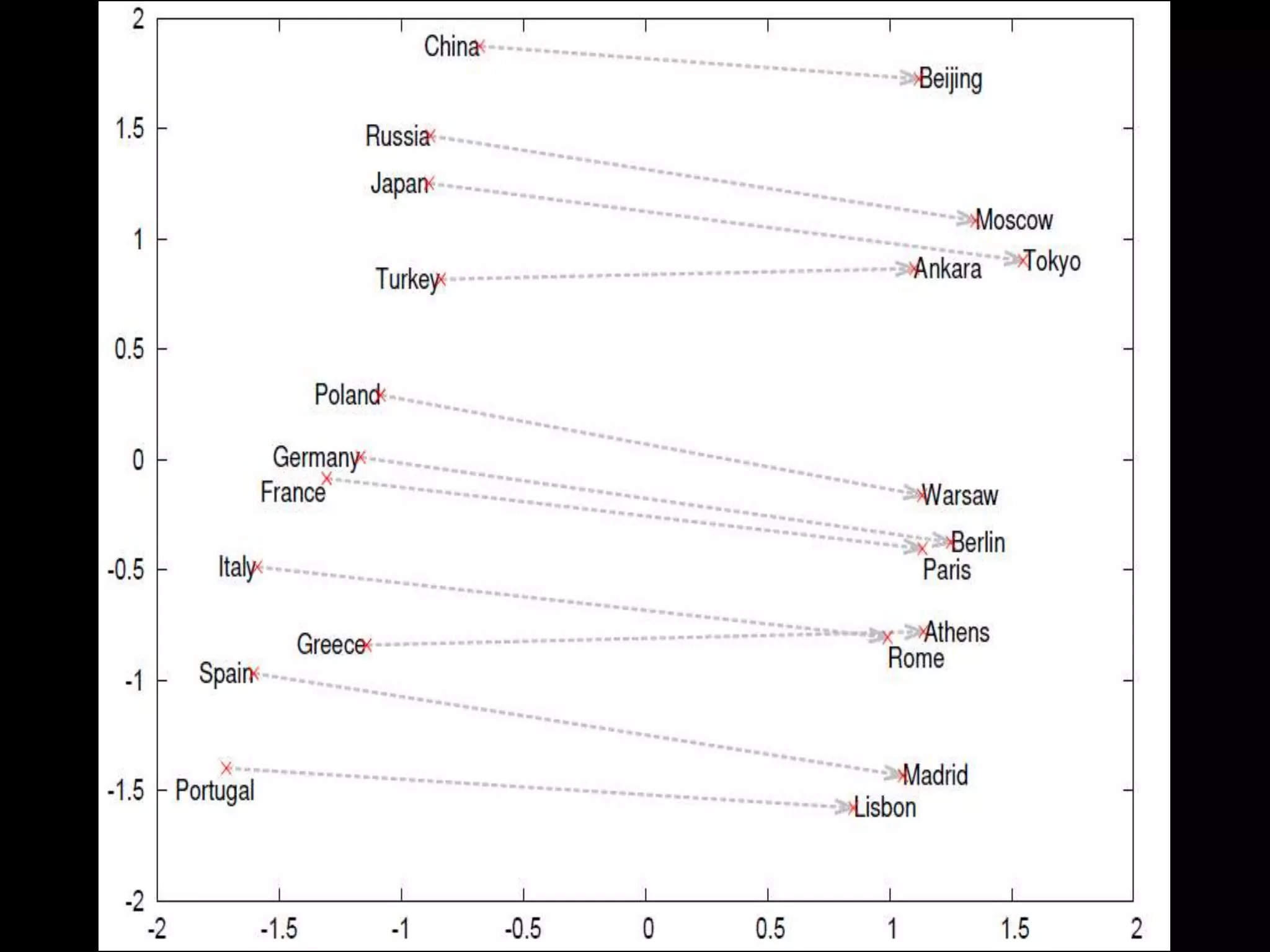
• [Paris] - [France] + [Italy] ≈ [Rome]
• [king] - [man] + [woman] ≈ [queen]
• We can use it to solve word analogy problems
Boston: Red_Sox= New_York: ?
Demo](https://image.slidesharecdn.com/ranidatafest-141214050412-conversion-gate01/75/Vector-Space-Word-Representations-Rani-Nelken-PhD-16-2048.jpg)
![Why does it work?
[king] - [man] + [woman] ≈ [queen]
cos (x, ([king] – [man] + [woman])) =
cos (x, [king]) – cos(x, [man]) + cos(x, [woman])
[queen] is a good candidate](https://image.slidesharecdn.com/ranidatafest-141214050412-conversion-gate01/75/Vector-Space-Word-Representations-Rani-Nelken-PhD-18-2048.jpg)












![[Question Paper] Modern Operating System (Revised Course) [June / 2016]](https://cdn.slidesharecdn.com/ss_thumbnails/mos-qprevisedcoursejun-2016-170717110149-thumbnail.jpg?width=640&height=640&fit=bounds)

















































