Downloaded 13 times





























![DO IT YOURSELF
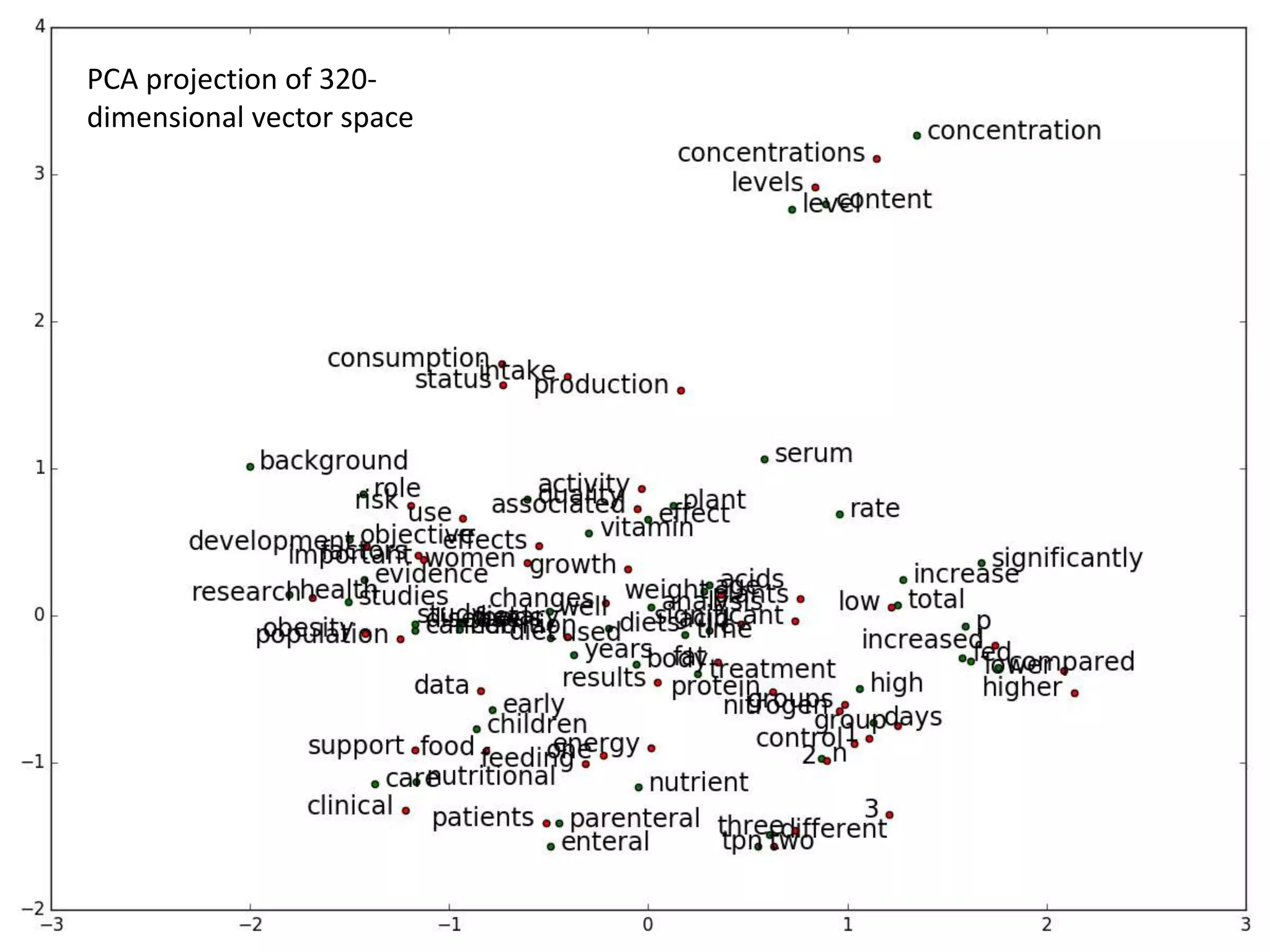
model.most_similar(‘apple’)
[(’banana’, 0.8571481704711914), ...]
model.doesnt_match("breakfast cereal dinner lunch".split())
‘cereal’
model.similarity(‘woman’, ‘man’)
0.73723527
Suzan Verberne 2019
Cosine similarity](https://image.slidesharecdn.com/2019-11-05lexicographylorentz-191105122323/75/Text-Mining-for-Lexicography-37-2048.jpg)


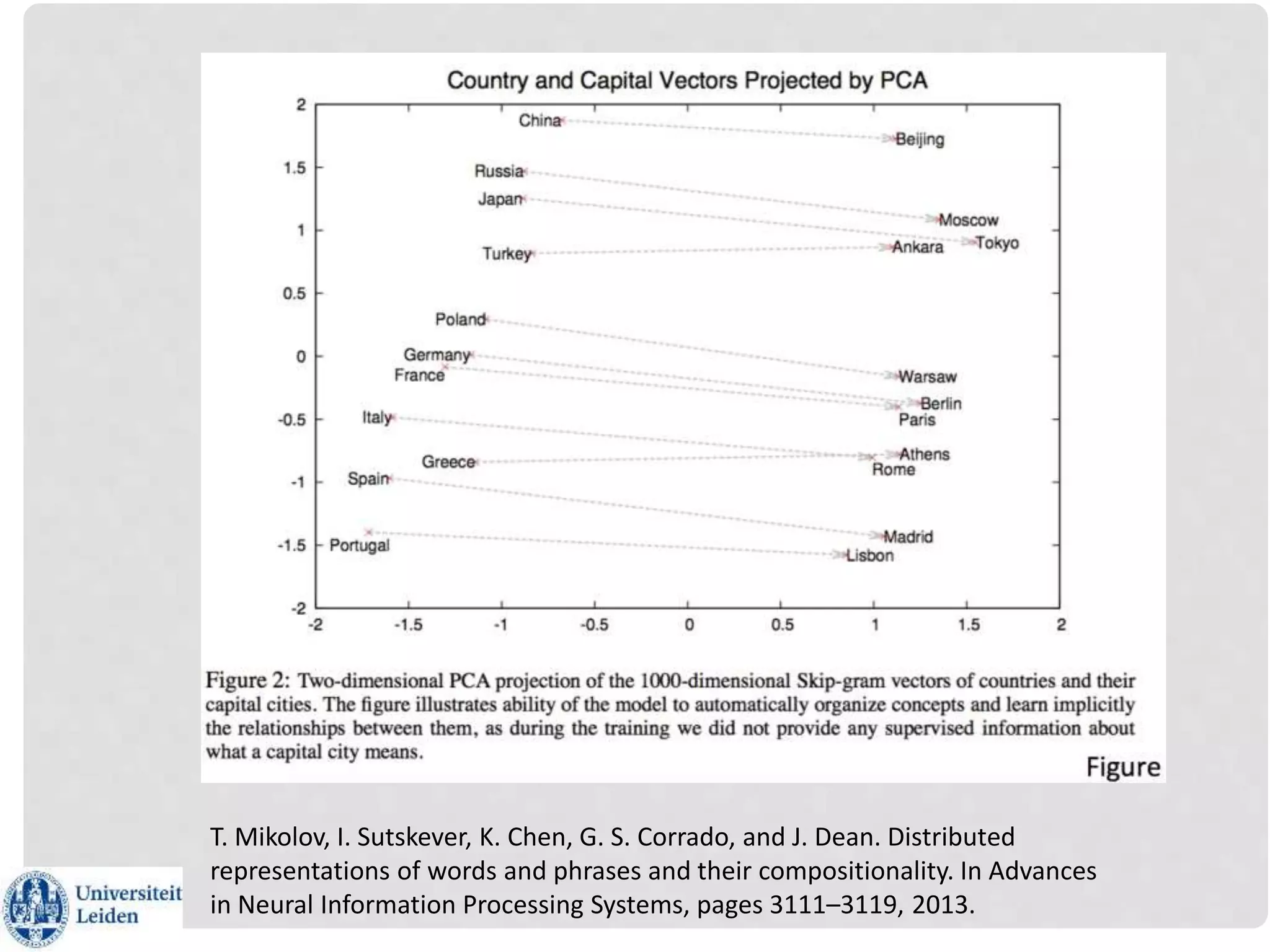

![WHAT CAN YOU DO WITH IT?
Mining knowledge about natural language
Learning semantic and semantic relations
Selecting out-of-the-list words
Example: which word does not belong in [monkey, lion, dog, truck]
Selectional preferences
Example: predict typical verb-noun pairs: people as subject of eating is more
likely than people as object of eating
Discover new words
Suzan Verberne 2019](https://image.slidesharecdn.com/2019-11-05lexicographylorentz-191105122323/75/Text-Mining-for-Lexicography-43-2048.jpg)






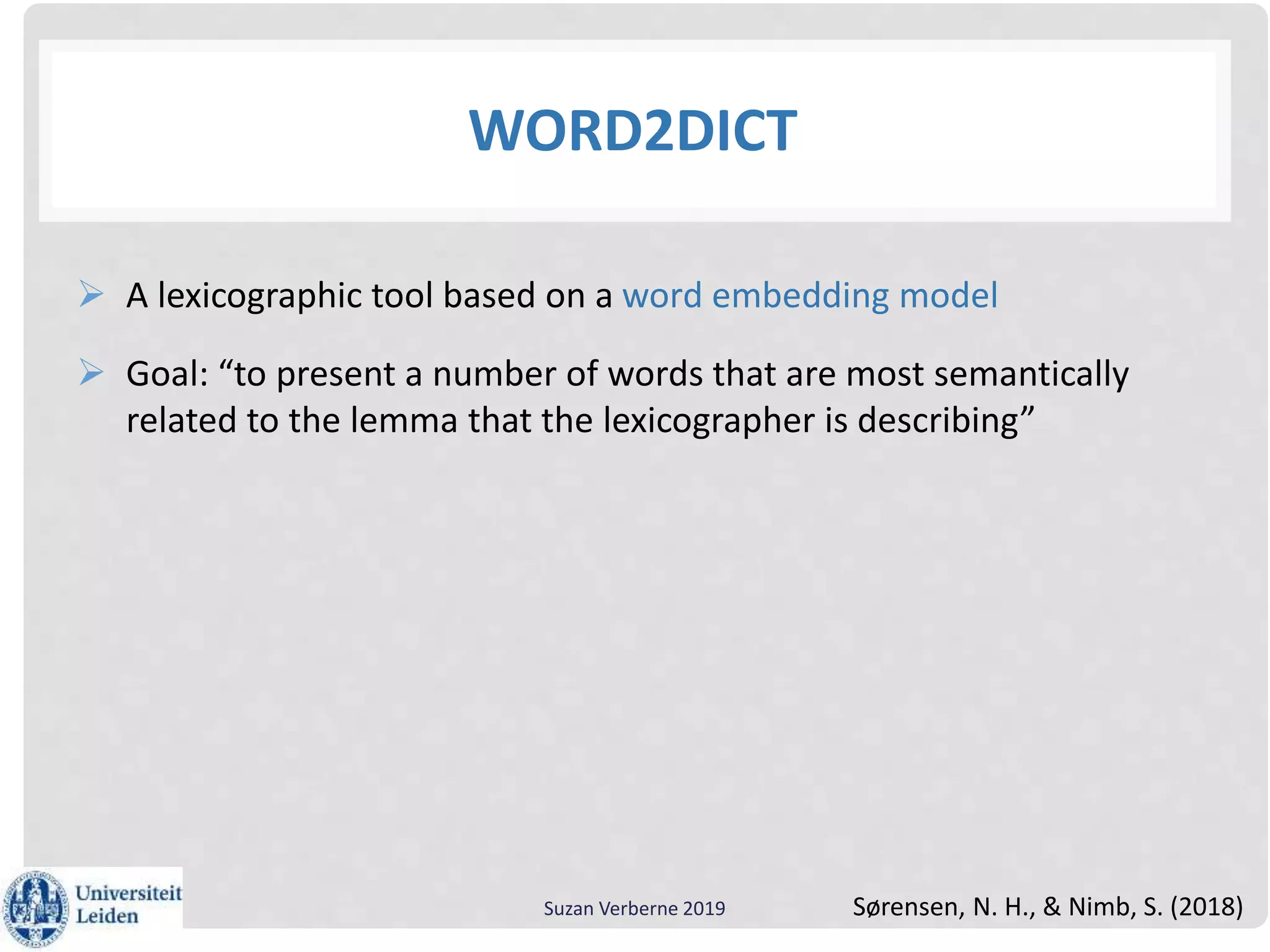
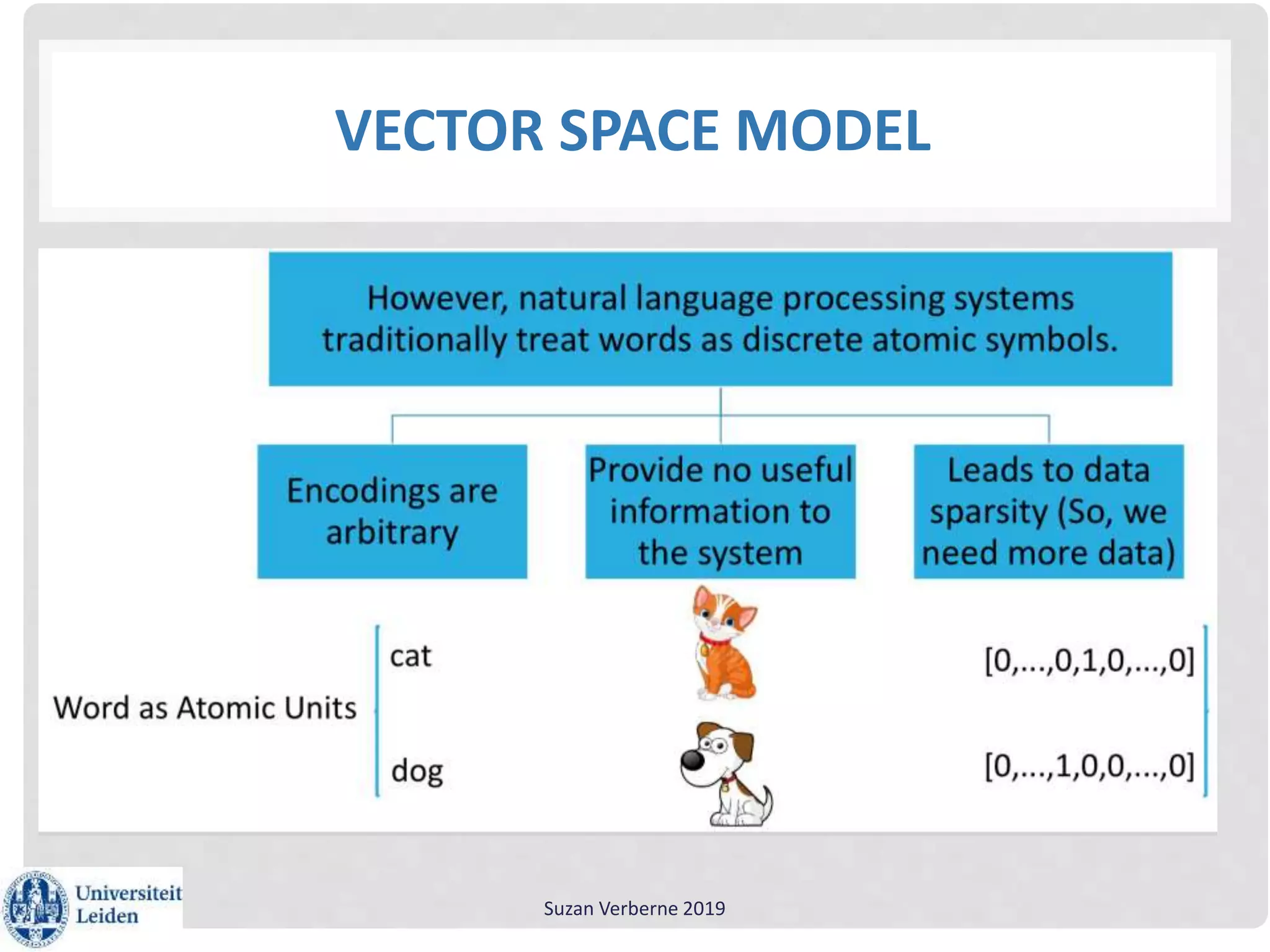
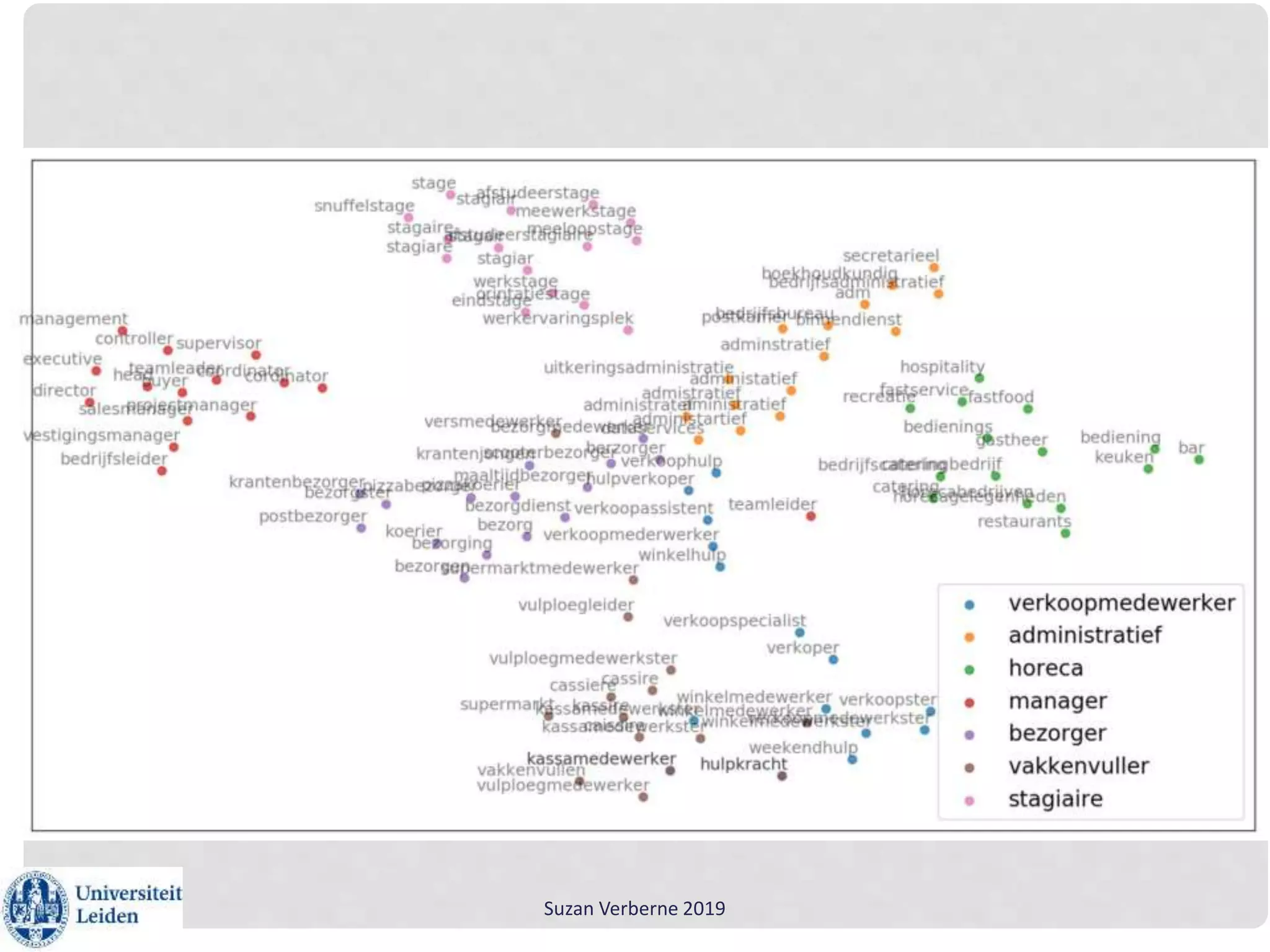
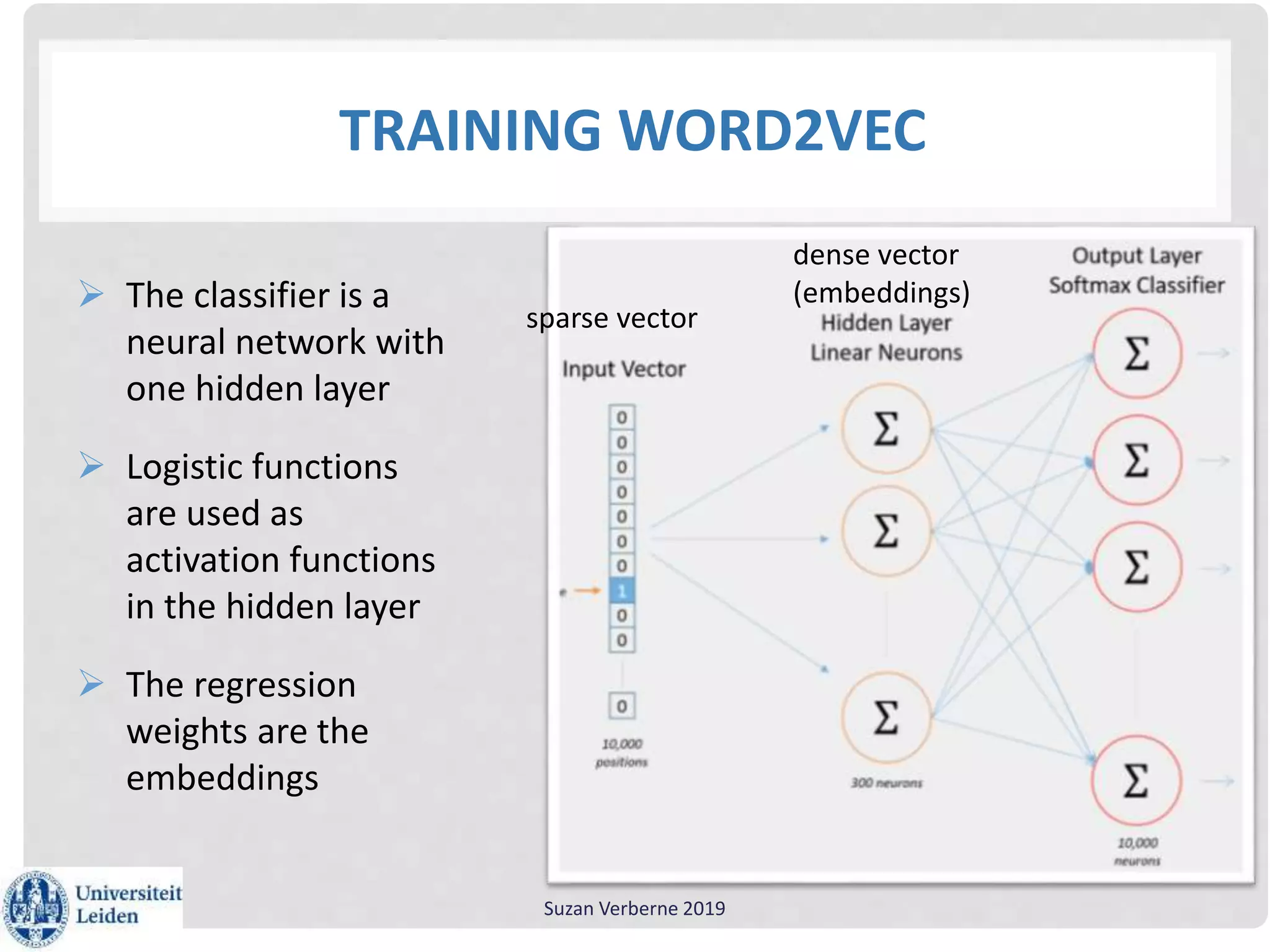
Suzan Verberne gave a workshop on using text mining for lexicography. She discussed using word embeddings to help discover and select new lemmas for dictionaries. Word2Dict is a lexicographic tool that uses word embeddings to present words semantically related to the lemma being described. Word embeddings learn dense vector representations of words by predicting words in context using neural networks, improving on the traditional sparse vector space model. Word embeddings can be trained using the Word2Vec algorithm and analyzed using the Gensim Python package to gain linguistic insights and improve natural language processing applications.
















































































