Download as PDF, PPTX




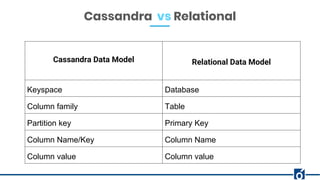
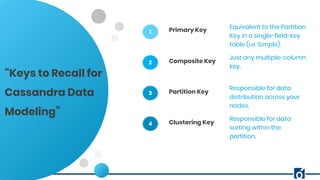



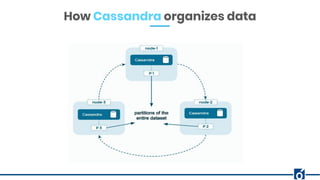
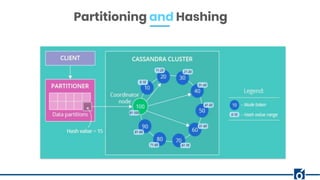





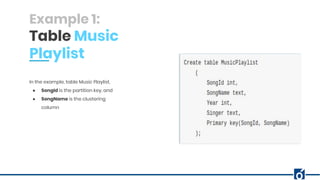








The document presents a detailed overview of data modeling in Apache Cassandra, highlighting the importance of keys such as primary and partition keys for data distribution and organization. It emphasizes the need to model data around query requirements instead of relationships, advocating for a single table per query pattern for optimization. Practical examples are provided, including schema designs for user posts and gym information, demonstrating effective data structuring for efficient retrieval.
































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)


