Downloaded 513 times
















![example
• A speech waveform S has the values
s0,s1,s2,s3,s4,s5,s6,s7,s8= [1,3,2,1,4,1,2,4,3]. The frame
size is 4.
• Find auto-correlation parameter r0, r1, r2 for the first frame.
• If we use LPC order 2 for our feature extraction system, find
LPC coefficients a1, a2.](https://image.slidesharecdn.com/seminaradspspeechsignalprocessingmurtadha-150504150353-conversion-gate02/75/Speech-Signal-Processing-23-2048.jpg)
![Answer:
• Frame size=4, first frame is [1,3,2,1]
• r0=1x1+ 3x3 +2x2 +1x1=15
• r1= 3x1 +2x3 +1x2=11
• r2= 2x1 +1x3=5
•
0.4423-
1.0577
2
1
5
11
1511
1115
2
1
5
11
2
1
1511
1115
2
1
2
1
01
10
a
a
inv
a
a
a
a
r
r
a
a
rr
rr](https://image.slidesharecdn.com/seminaradspspeechsignalprocessingmurtadha-150504150353-conversion-gate02/75/Speech-Signal-Processing-24-2048.jpg)

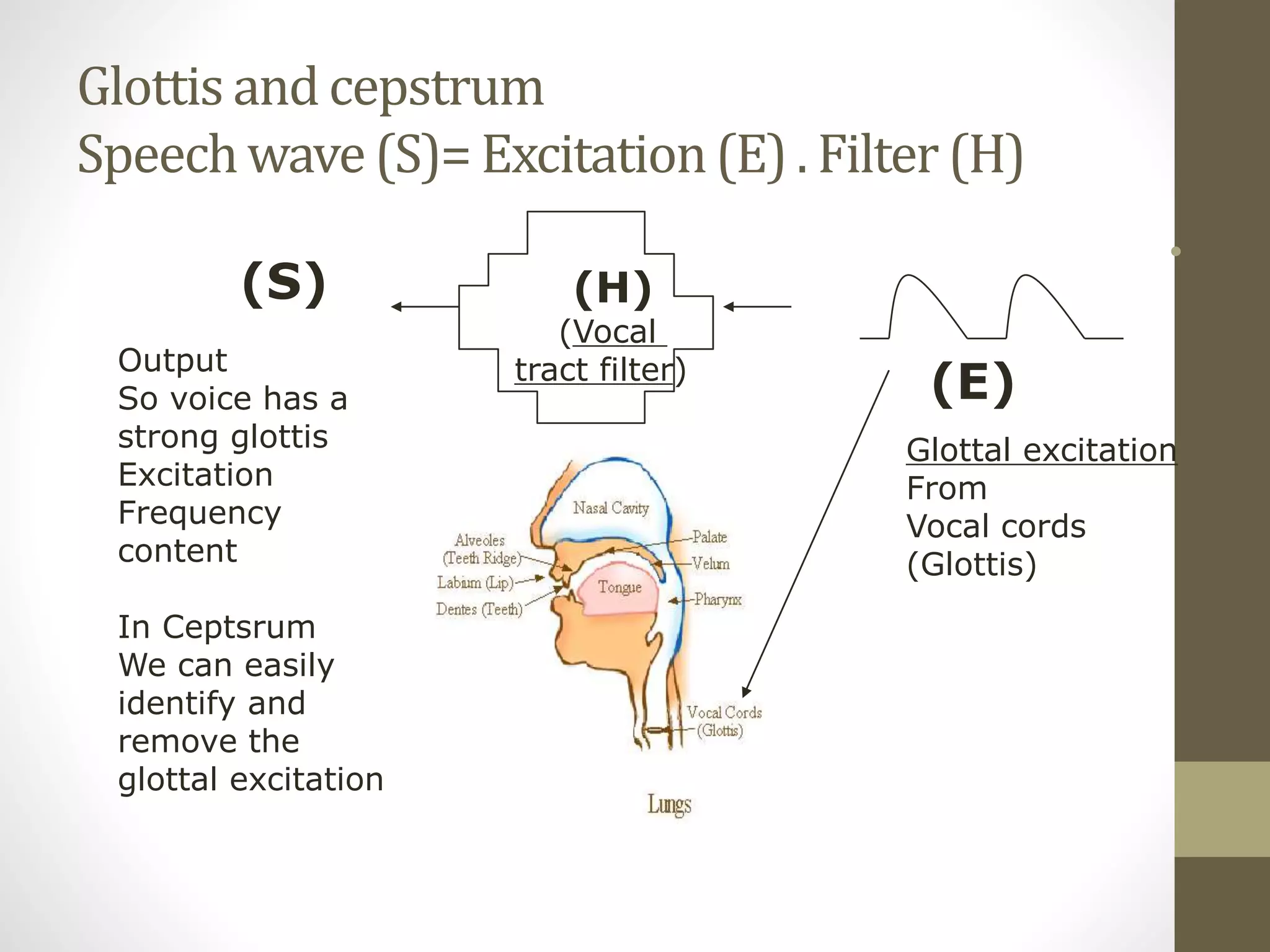

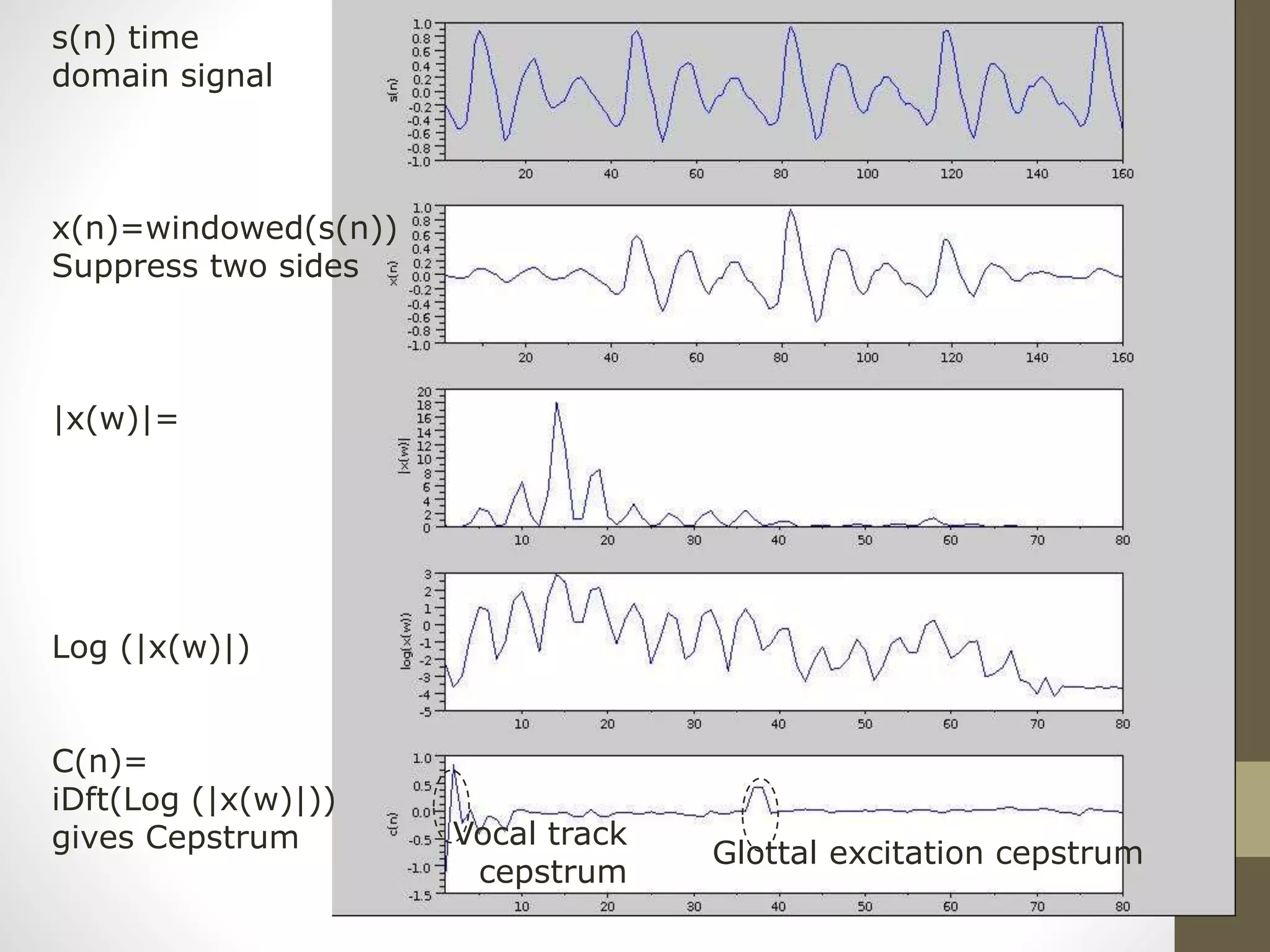
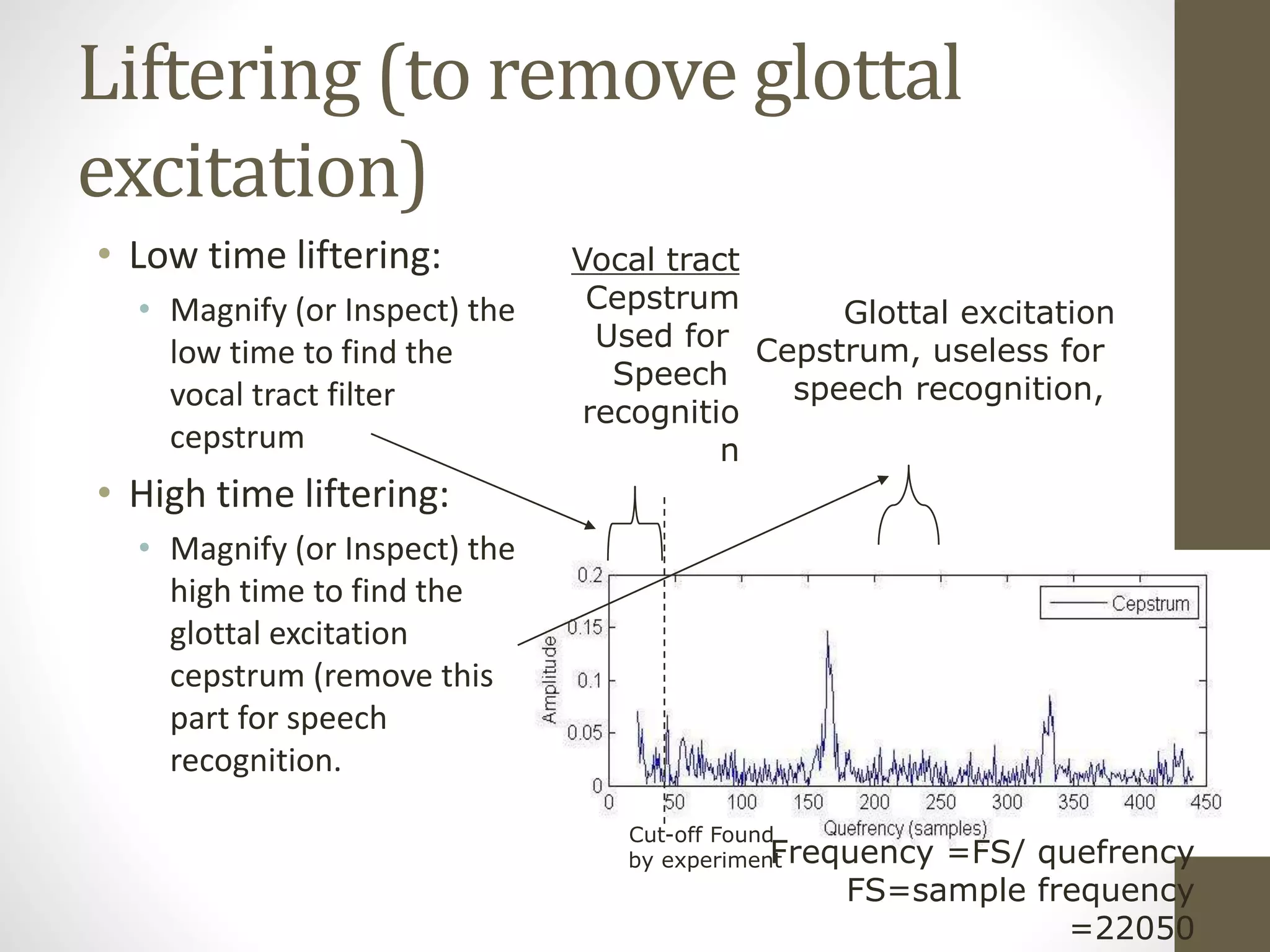
![Cepstrum
• C(n)=IDFT[log10 |S(w)|]=
• IDFT[ log10{|E(w)|} + log10{|H(w)|} ]
• In c(n), you can see E(n) and H(n) at two different positions
• Application: useful for (i) glottal excitation (ii) vocal tract filter
analysis
windowing DFT Log|x(w)| IDFT
X(n) X(w) Log|x(w)|
N=time index
w=frequency
I-DFT=Inverse-discrete Fourier transform
S(n) C(n)](https://image.slidesharecdn.com/seminaradspspeechsignalprocessingmurtadha-150504150353-conversion-gate02/75/Speech-Signal-Processing-28-2048.jpg)





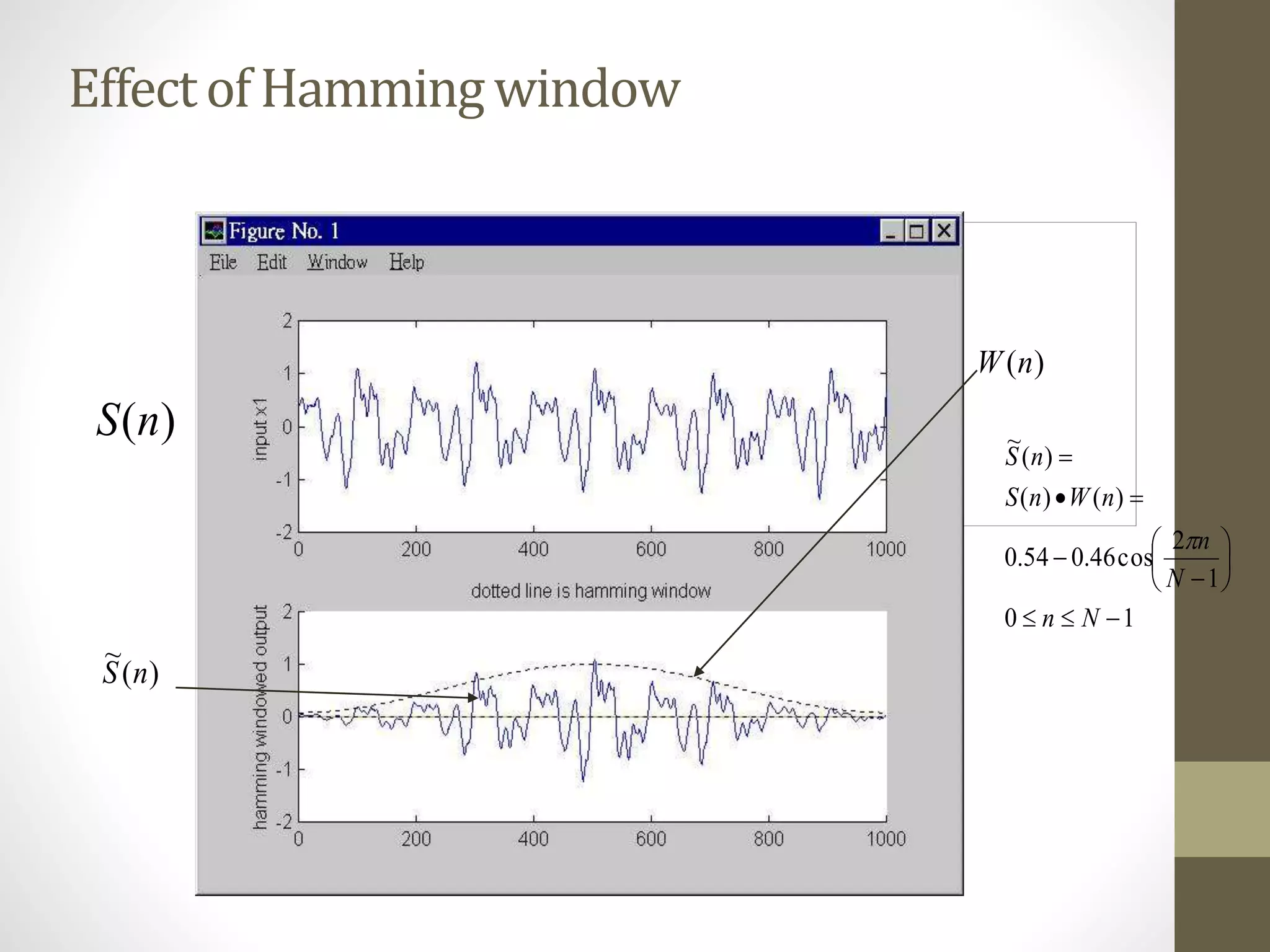
![Step2(b): Windowing
•To smooth out the discontinuities at the beginning and end.
•Hamming or Hanning windows can be used.
•Hamming window
•Tutorial: write a program segment to find the result of passing
a speech frame, stored in an array int s[1000], into the
Hamming window.
10
1
2
cos46.054.0)()()(
~
Nn
N
n
nWnSnS
](https://image.slidesharecdn.com/seminaradspspeechsignalprocessingmurtadha-150504150353-conversion-gate02/75/Speech-Signal-Processing-37-2048.jpg)







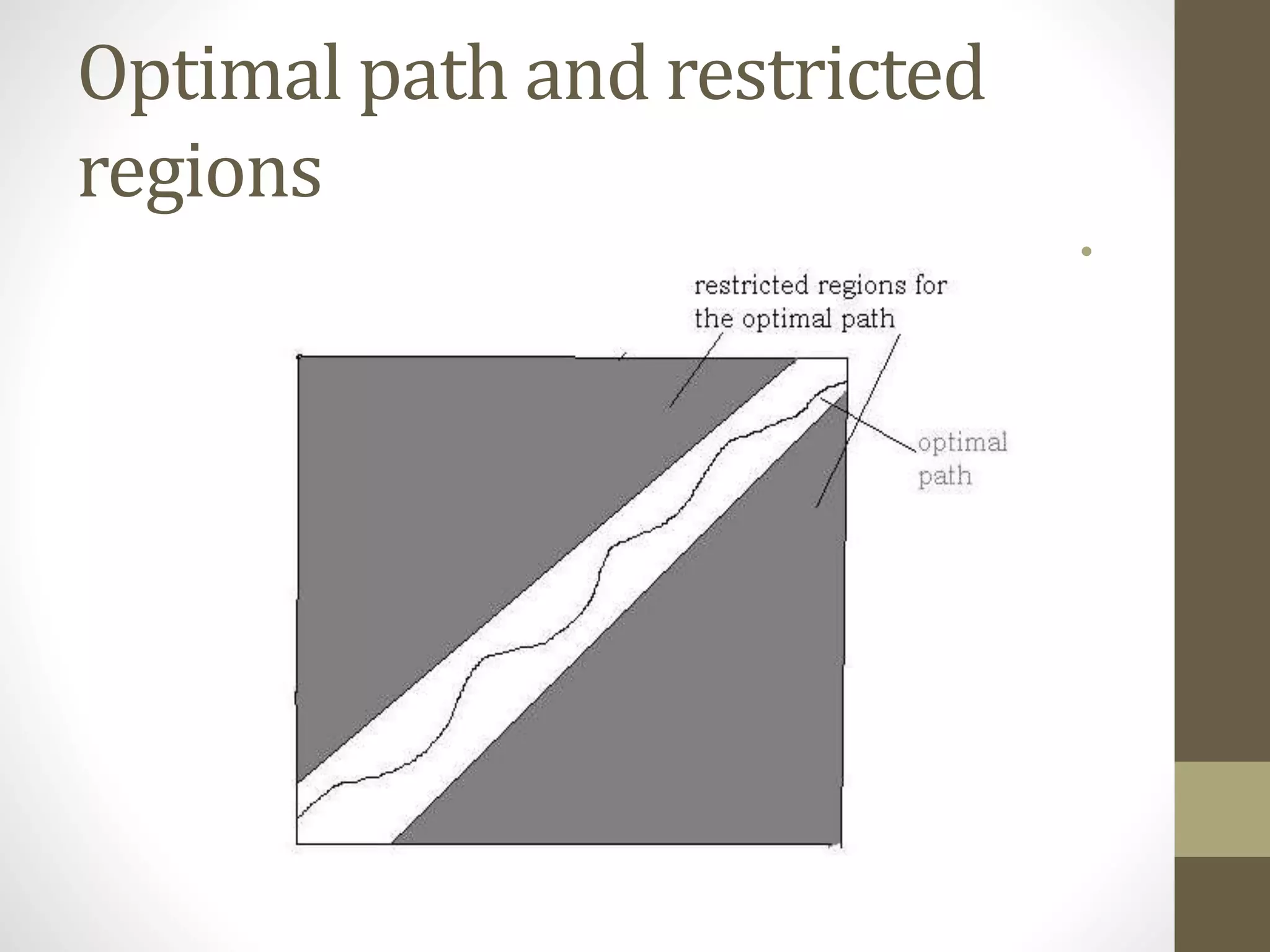

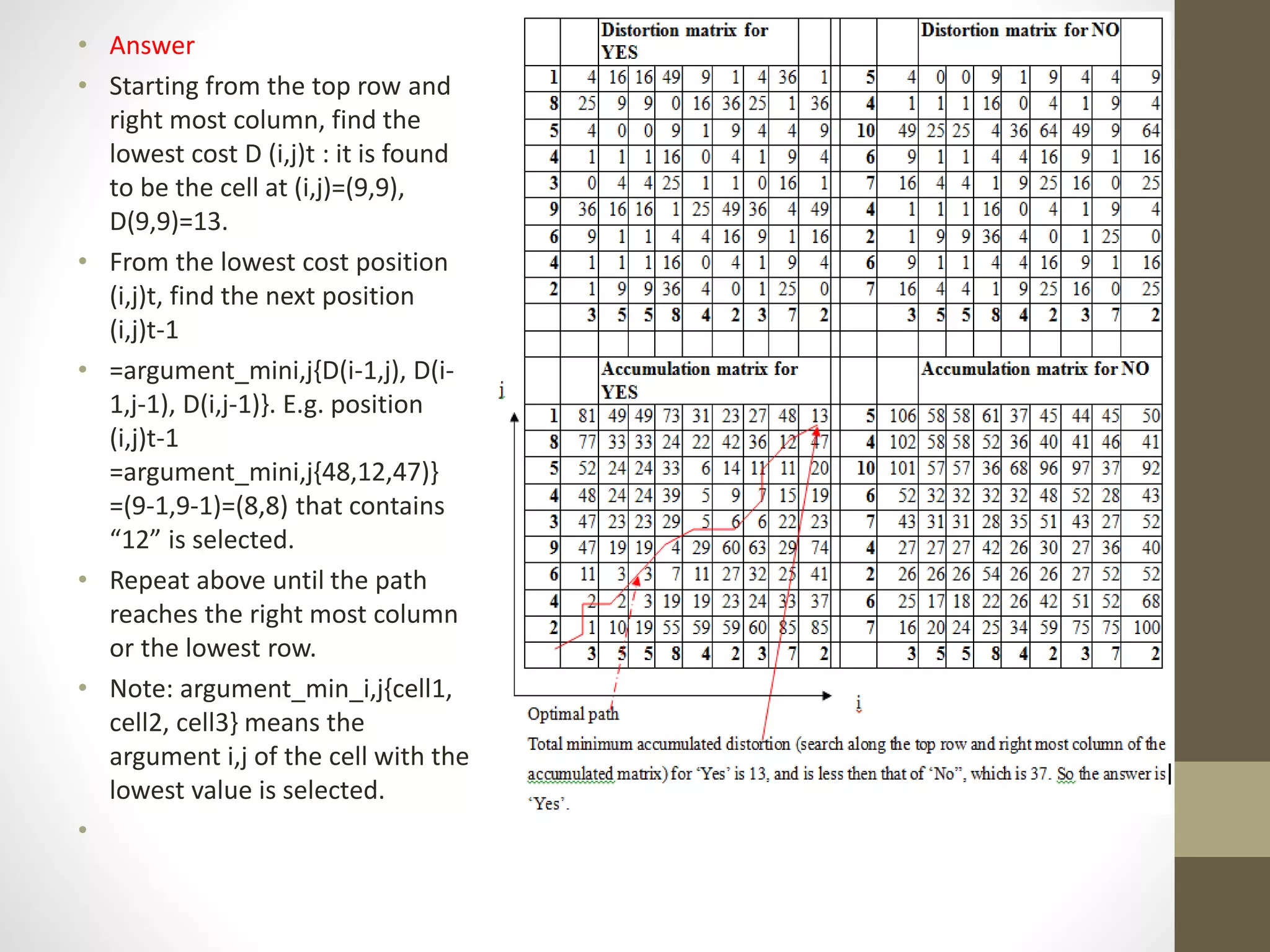


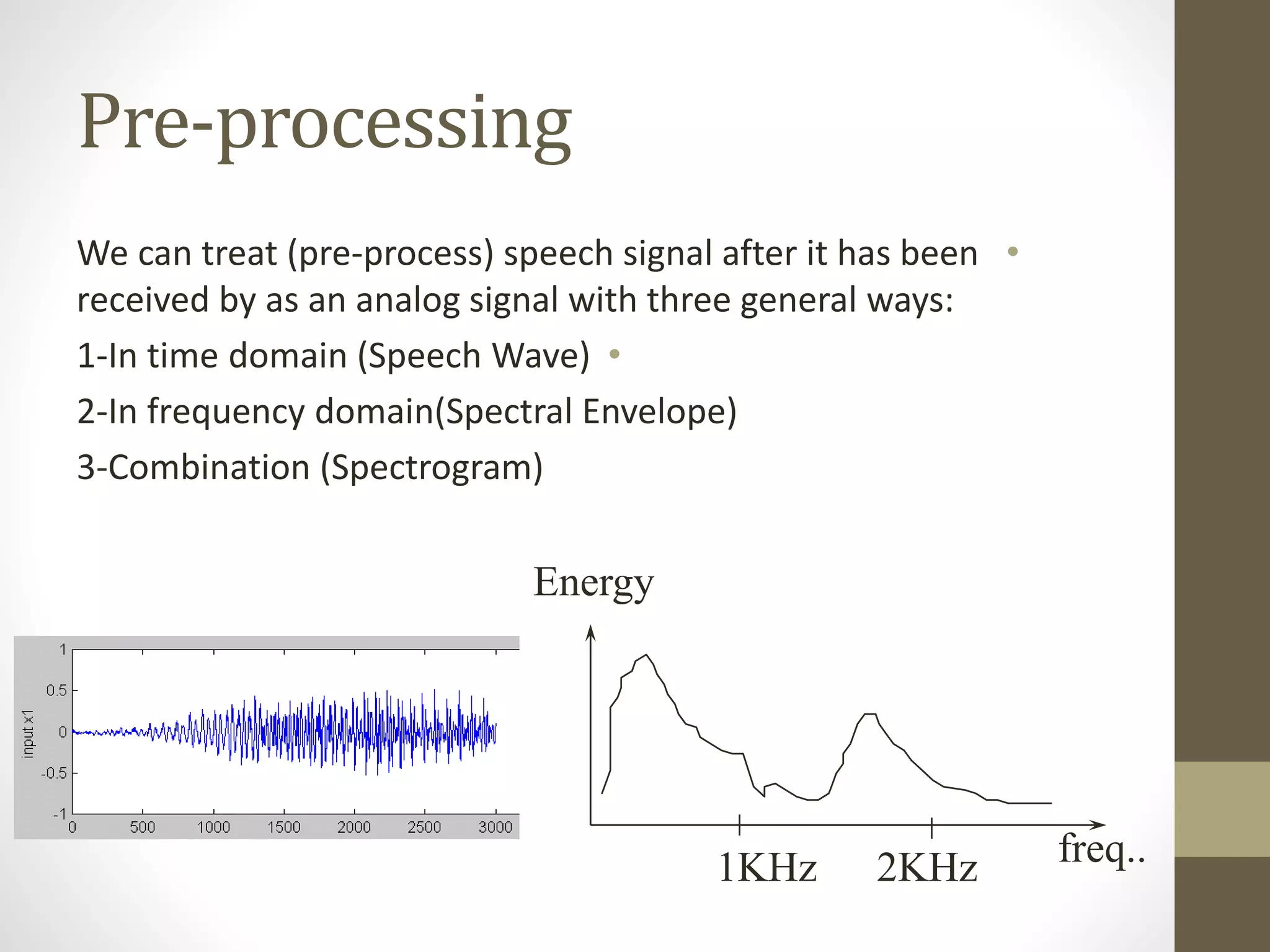
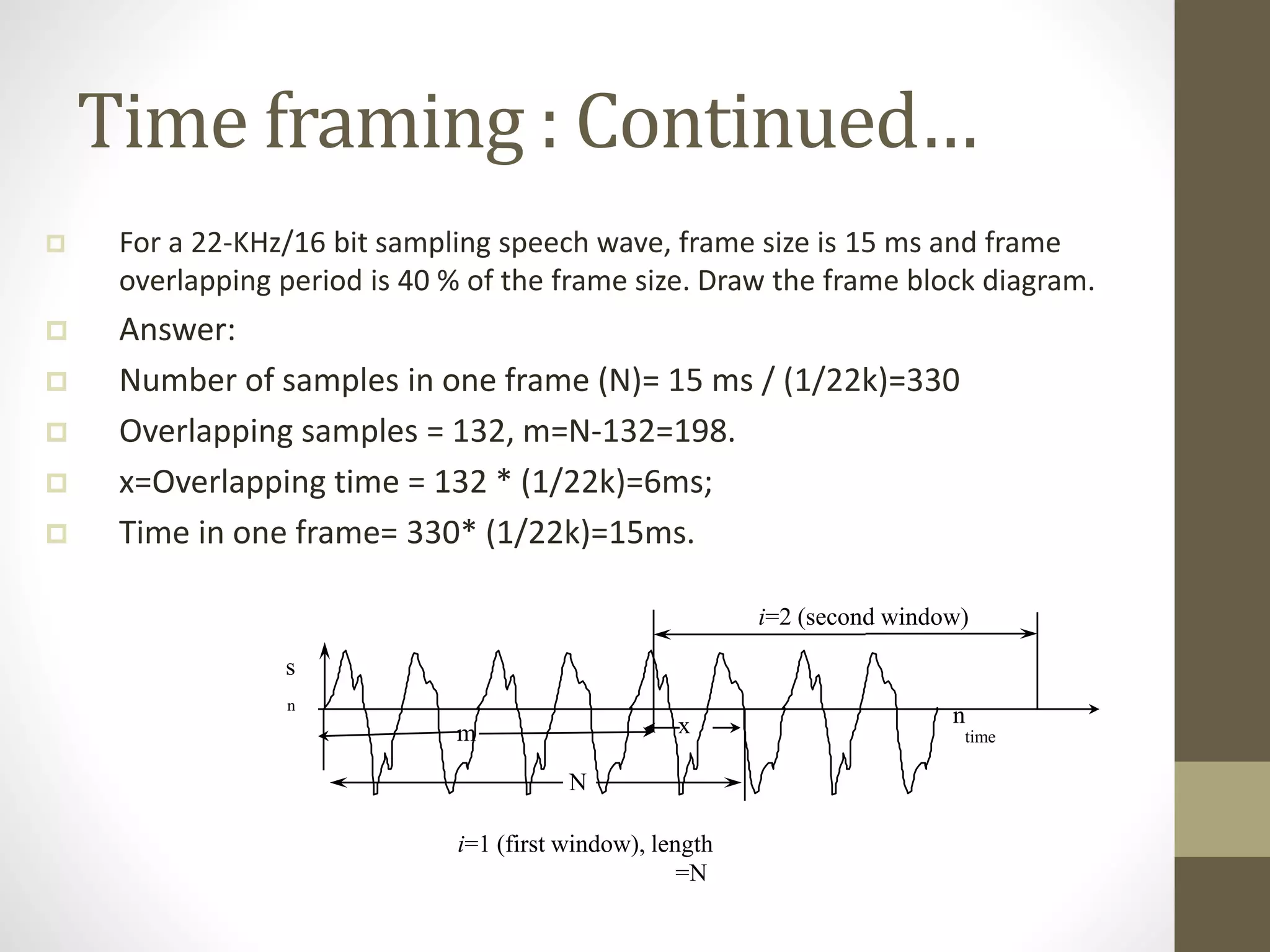
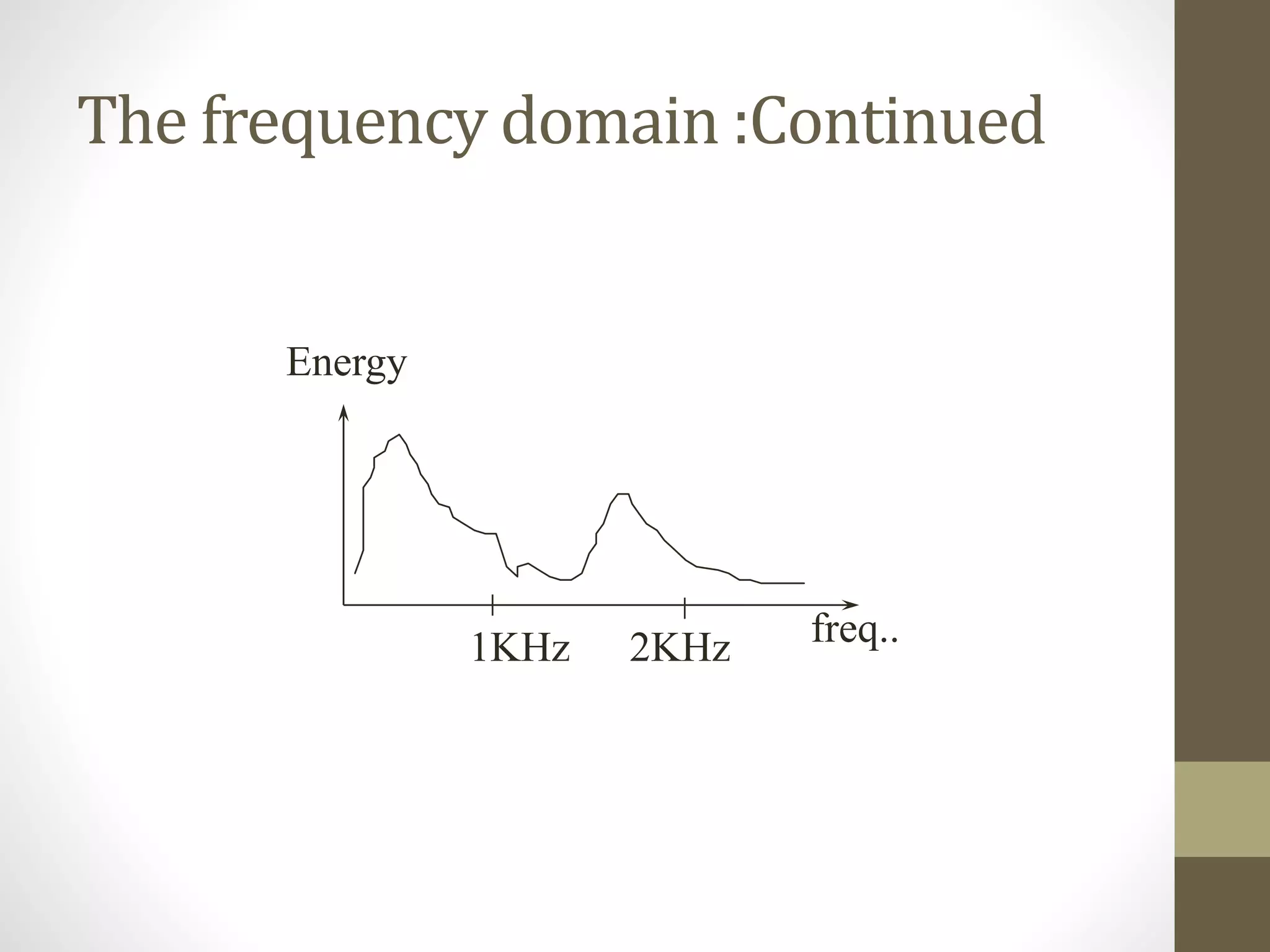
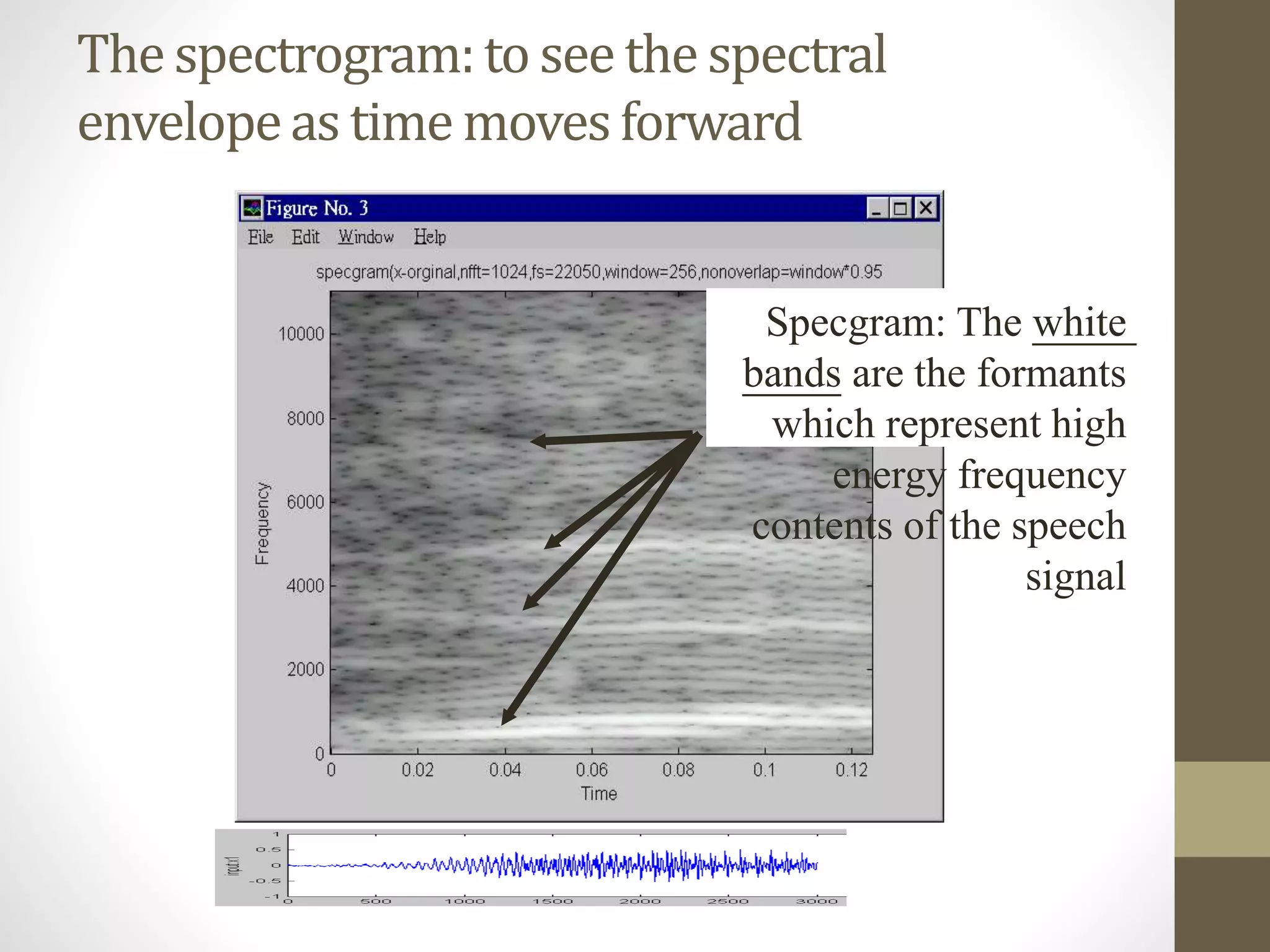
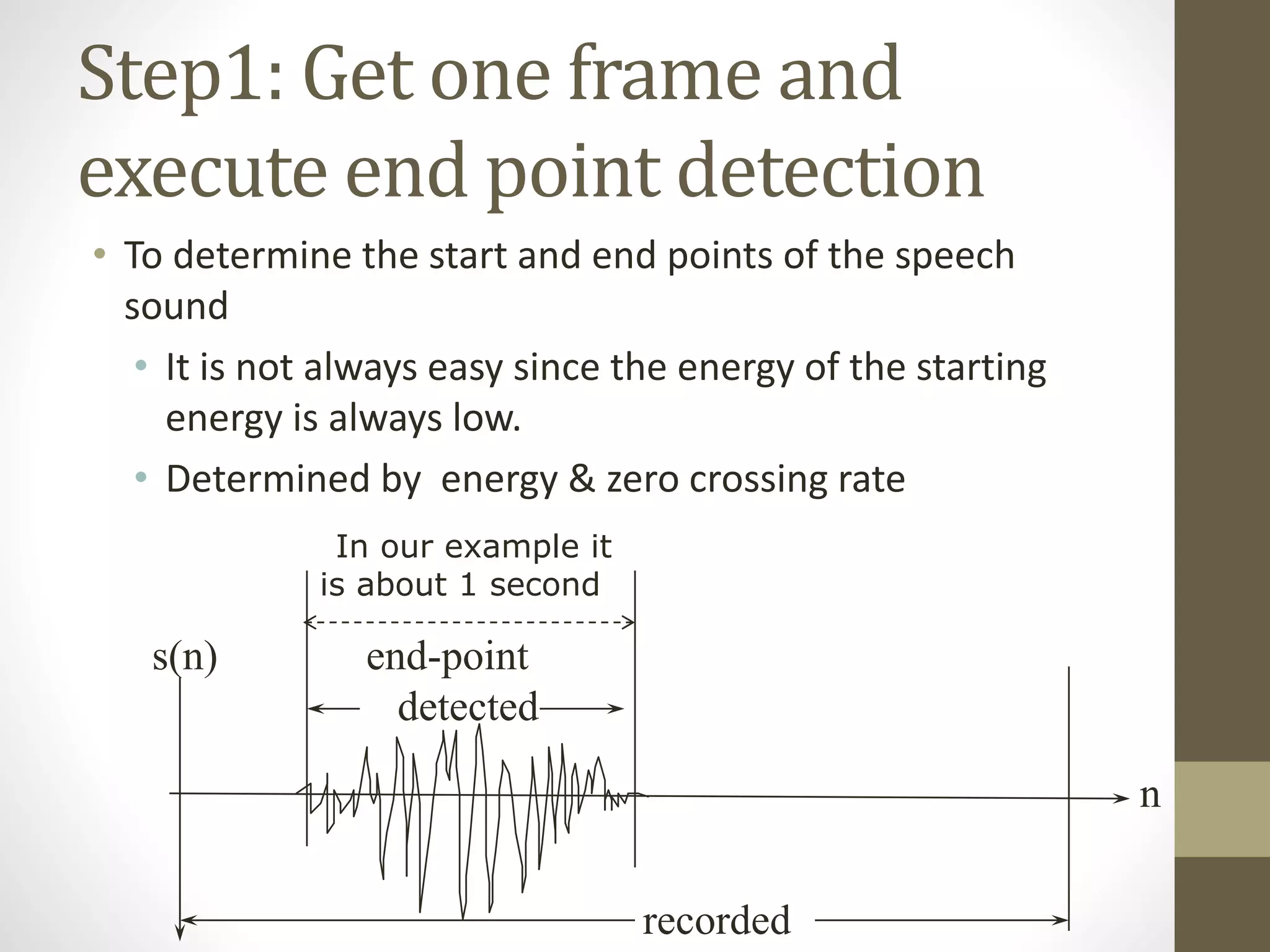
This document discusses speech signal processing and speech recognition. It begins by defining speech processing and its relationship to digital signal processing. It then outlines several disciplines related to speech processing including signal processing, physics, pattern recognition, and computer science. The document discusses aspects of speech signals including phonemes, the speech waveform, and spectral envelope. It covers various aspects of speech processing including pre-processing, feature extraction, and recognition. It provides details on techniques for pre-processing, feature extraction including filtering, linear predictive coding, and cepstrum. Finally, it summarizes the main steps in a speech recognition procedure including endpoint detection, framing and windowing, feature extraction, and distortion measure calculations for recognition.























































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)











