Download to read offline





![Preprocessing
Preprocessing is an important step in a speaker verification system. This also called
voice activity detection (VAD).
VAD separates speech region from non-speech regions[2-3]
It is very difficult to implement a VAD algorithm which works consistently for
different type of data
VAD algorithms can be classified in two groups
Feature based approach
Statistical model based approach
Each of the VAD method have its own merits and demerits depending on accuracy,
complexity etc.
Due to simplicity most of the speaker verification systems use signal energy for VAD.
6/24/2015 N.I.T. PATNA ECE, DEPTT. 7](https://image.slidesharecdn.com/finalprojectnew-150624180337-lva1-app6892/85/SPEKER-RECOGNITION-UNDER-LIMITED-DATA-CODITION-7-320.jpg)
![The speech signal along with speaker information
contains many other redundant information like
recording sensor, channel, environment etc.
The speaker specific information in the speech
signal[2]
Unique speech production system
Physiological
Behavioral aspects
Feature extraction module transforms speech to a set
of feature vectors of reduce dimensions
To enhance speaker specific information
Suppress redundant information.
Feature Extraction
6/24/2015 N.I.T. PATNA ECE, DEPTT. 8](https://image.slidesharecdn.com/finalprojectnew-150624180337-lva1-app6892/85/SPEKER-RECOGNITION-UNDER-LIMITED-DATA-CODITION-8-320.jpg)




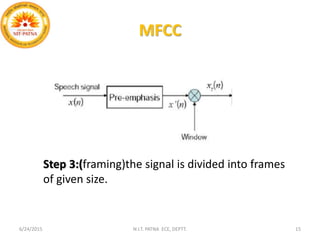

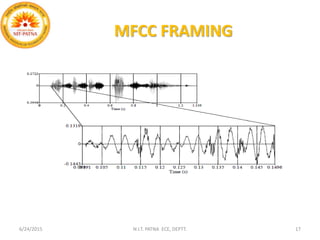
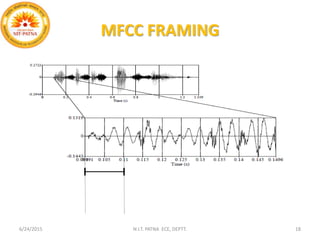
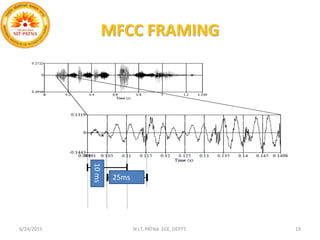

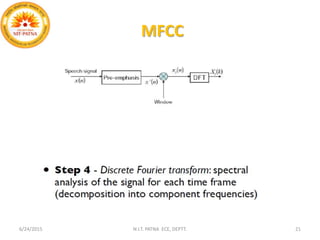
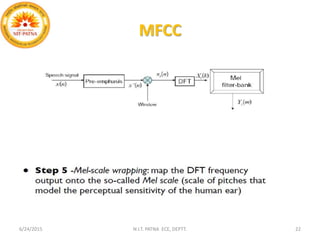
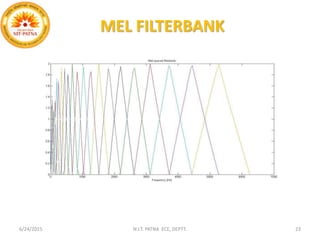
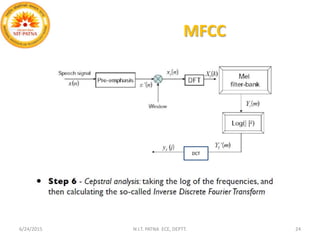
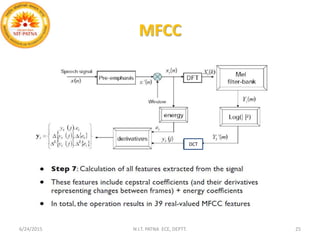



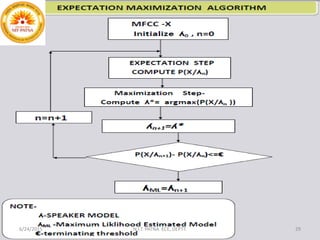




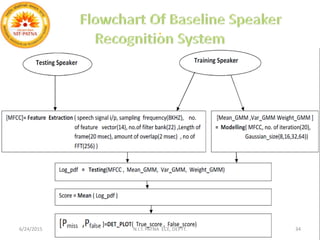
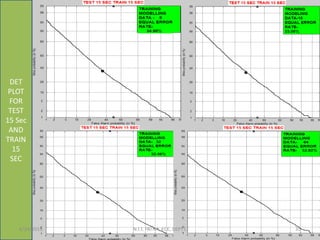
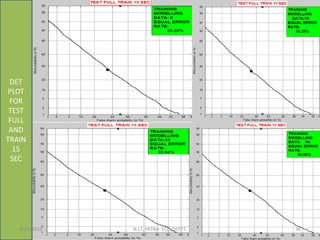
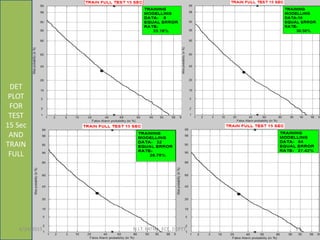
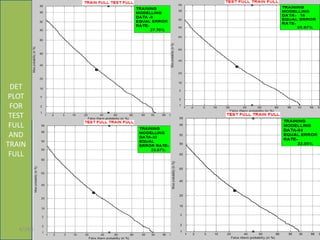
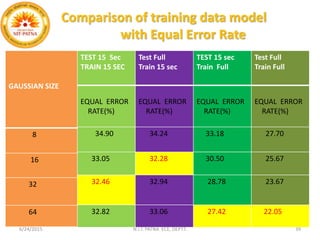




This document summarizes a presentation on baseline speaker verification. It discusses preprocessing speech signals using voice activity detection, extracting mel-frequency cepstral coefficients as features, building Gaussian mixture models during enrollment and testing phases, and evaluating performance using equal error rates. The authors' future plans include generating more training data synthetically and validating their results using i-vector based speaker verification.


























































