Download as PDF, PPTX












![www.percona.com
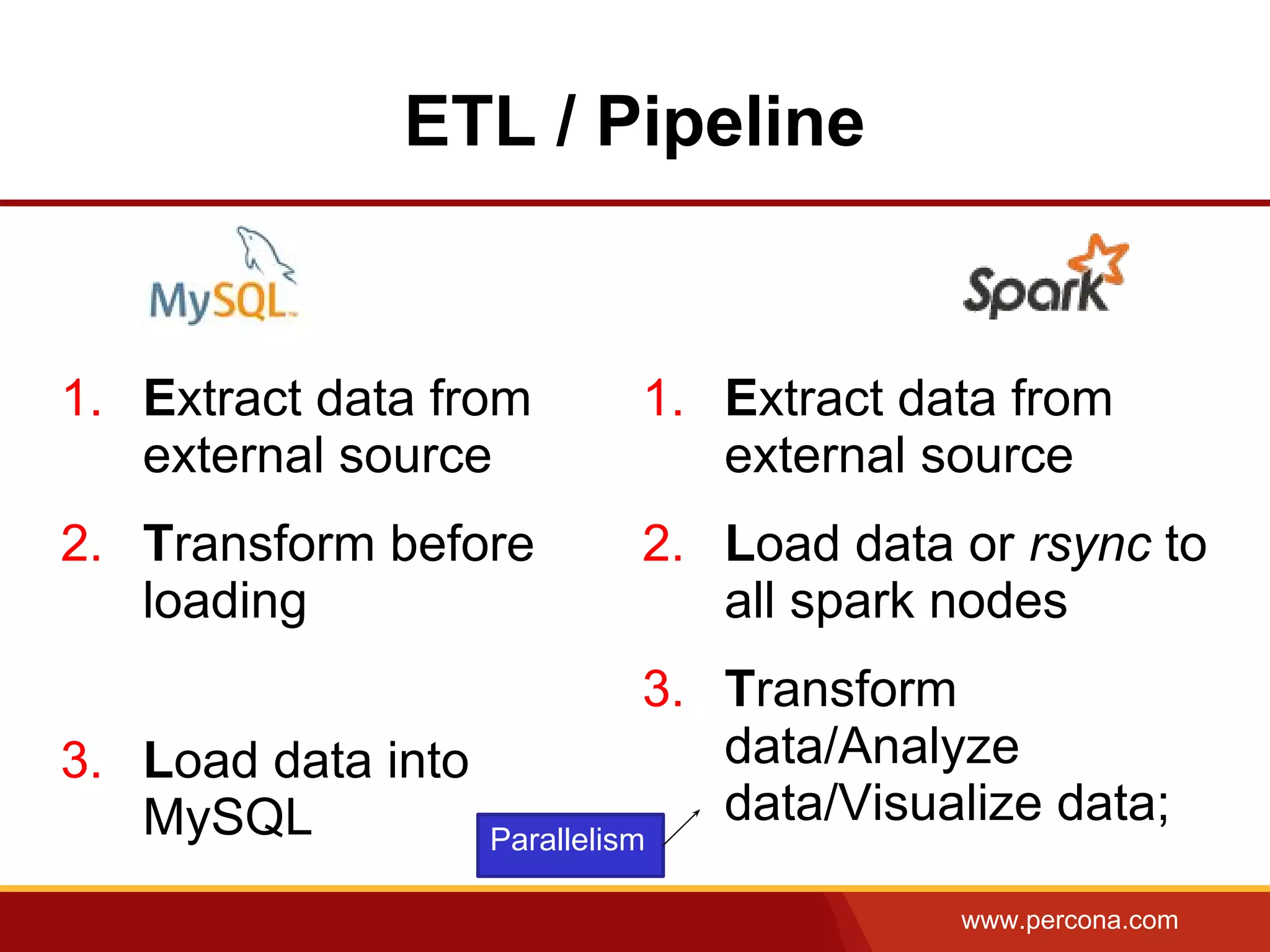
Spark and WikiStats: load pipeline
Row(project=p[0],
url=urllib.unquote(p[1]).lower(),
num_requests=int(p[2]),
content_size=int(p[3])))](https://image.slidesharecdn.com/usingapachesparkandmysqlfordataanalysis-170205010832/75/Using-Apache-Spark-and-MySQL-for-Data-Analysis-16-2048.jpg)



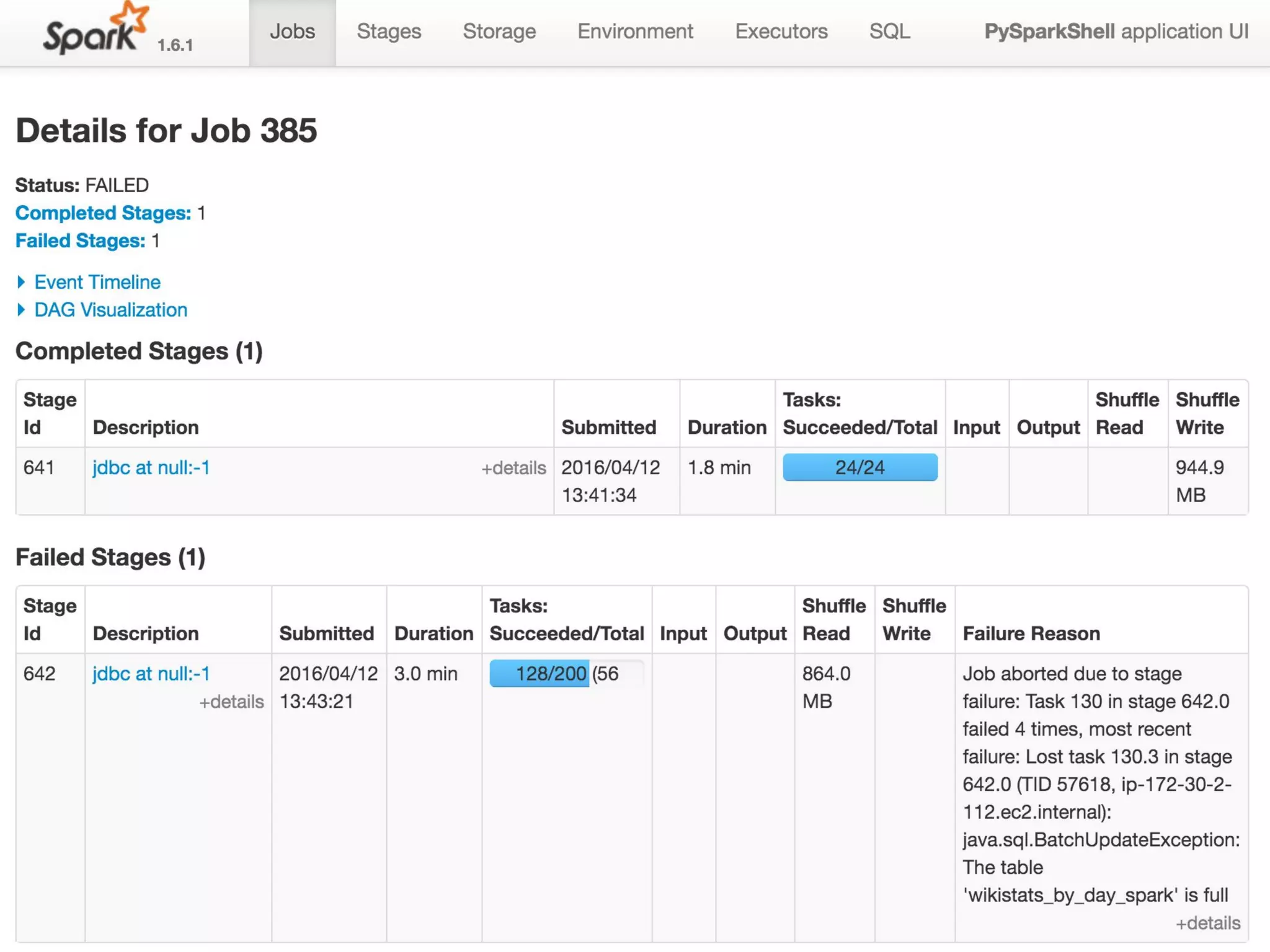
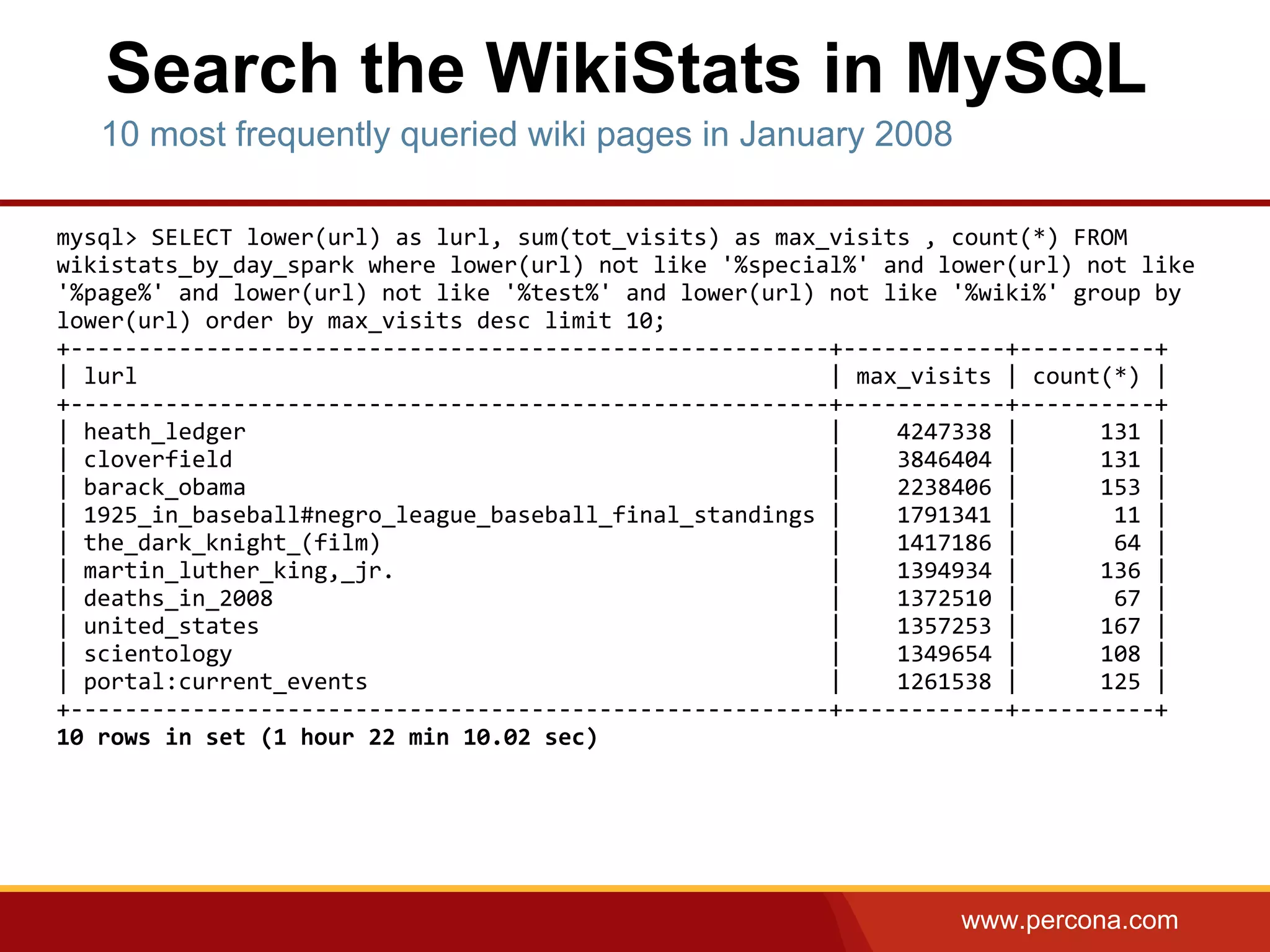
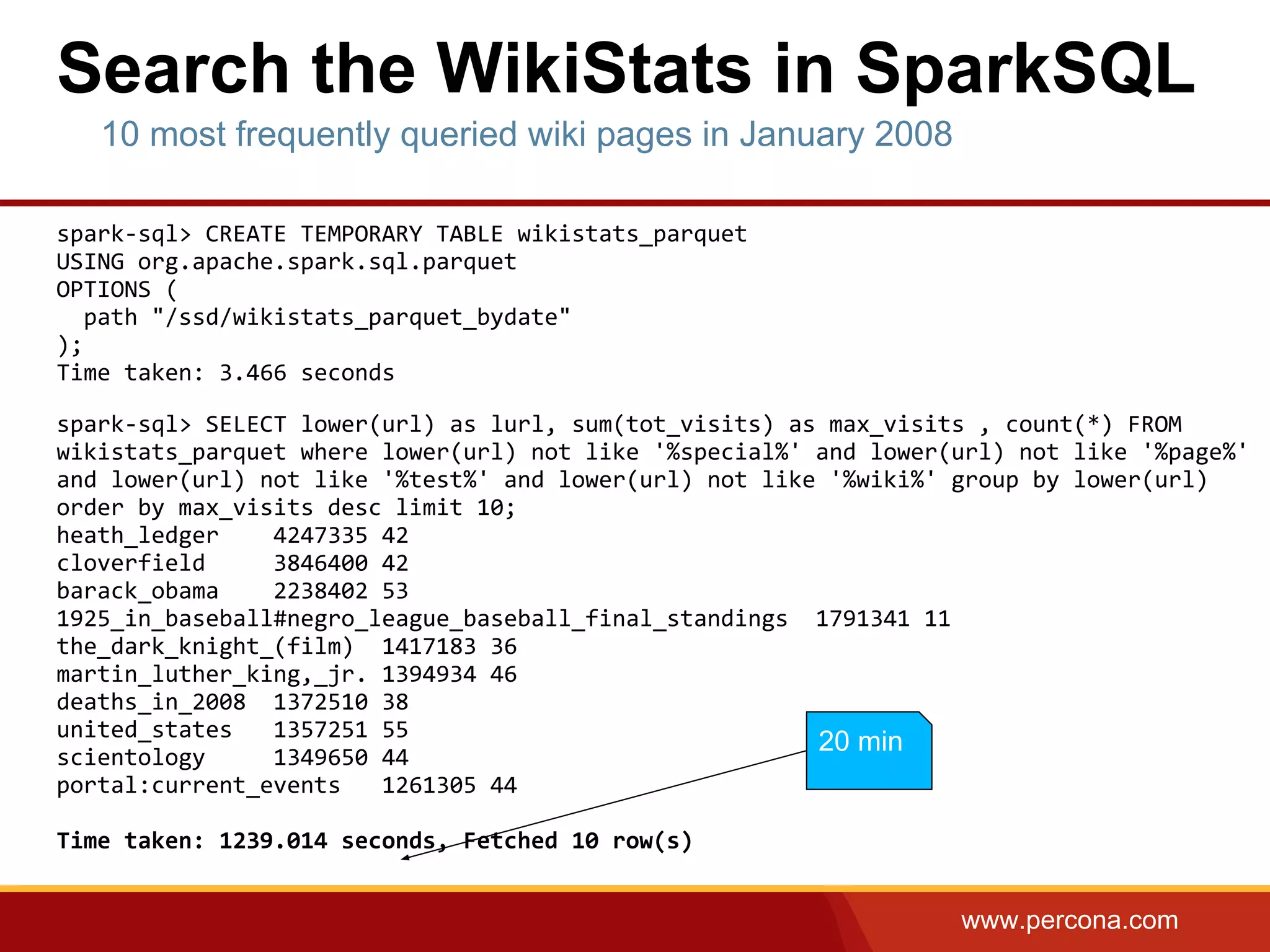





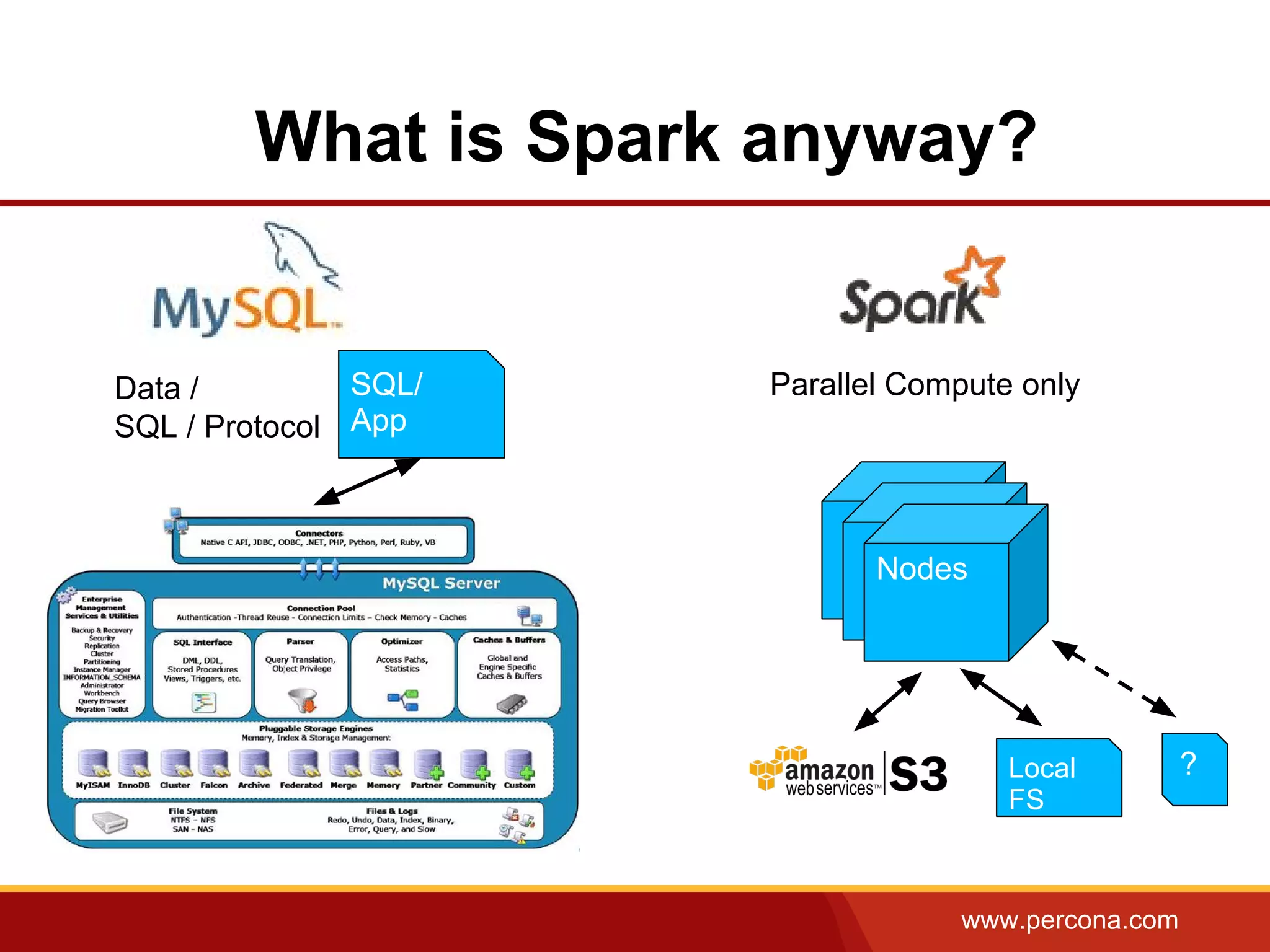
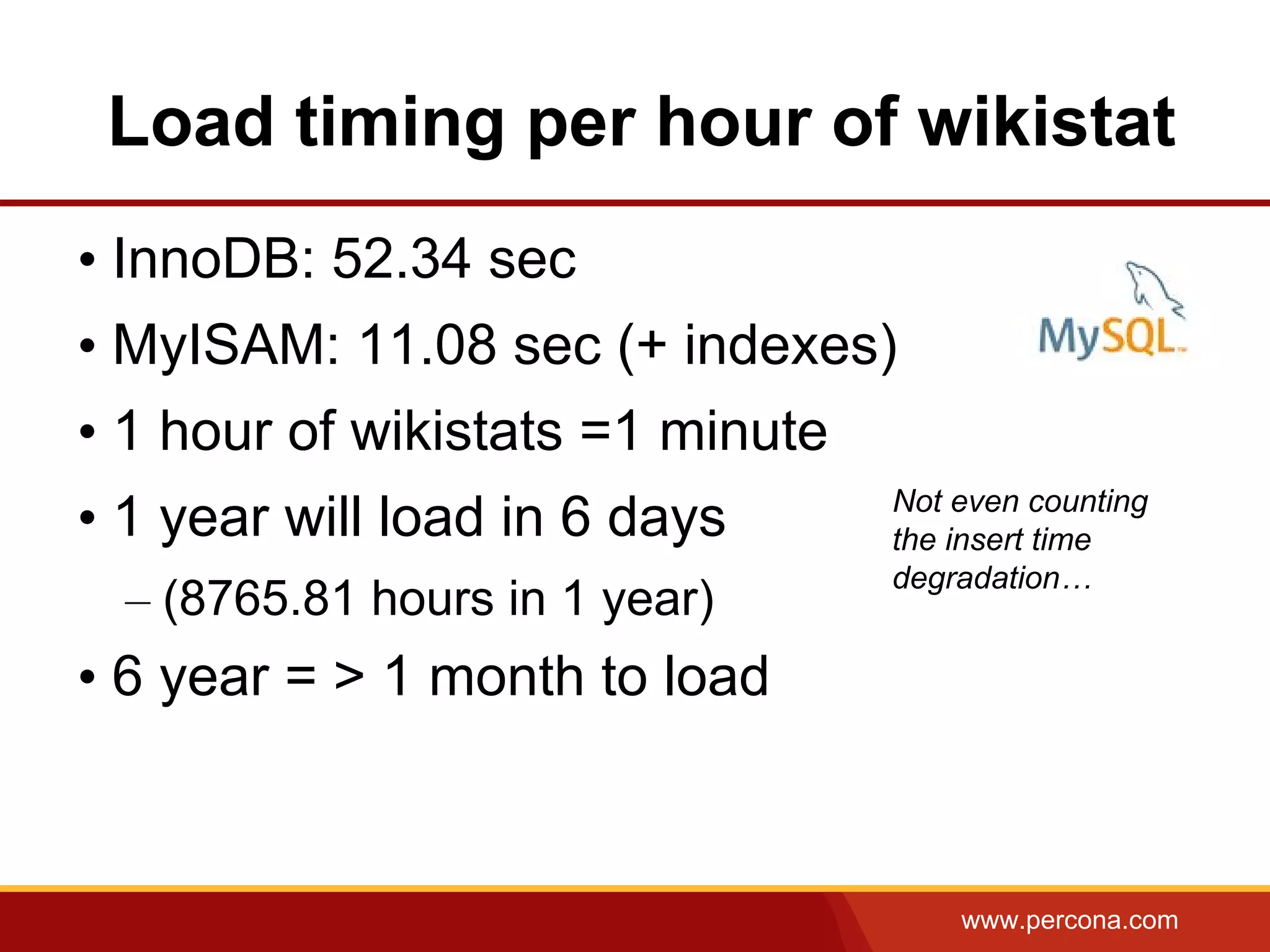
The document discusses using Apache Spark and MySQL for data analysis. It provides examples of loading Wikipedia usage statistics (Wikistats) data into both MySQL and Spark for analysis. Loading the full 10+ TB of Wikistats data into MySQL took over a month, while Spark was able to scan and analyze the entire dataset in under an hour by leveraging its ability to perform distributed, parallel processing across multiple nodes. The document compares key differences between Spark and MySQL for big data processing, such as Spark's lack of indexes but ability to perform full scans in parallel across nodes.
























![[2017 Windows on AWS] AWS를 활용한 그룹웨어 구축 방안](https://cdn.slidesharecdn.com/ss_thumbnails/3-171027022843-thumbnail.jpg?width=640&height=640&fit=bounds)














































![Introduction into MySQL Query Tuning for Dev[Op]s](https://cdn.slidesharecdn.com/ss_thumbnails/qtdevops-210717011329-thumbnail.jpg?width=640&height=640&fit=bounds)








![Introduction to MySQL Query Tuning for Dev[Op]s](https://cdn.slidesharecdn.com/ss_thumbnails/qtdevops-191005204425-thumbnail.jpg?width=640&height=640&fit=bounds)


























