Download as PDF, PPTX









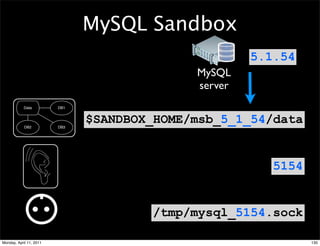
![3 ENABLE THE MASTER
Master
Configuration file
[mysqld]
log-bin=mysql-bin
server-id=1
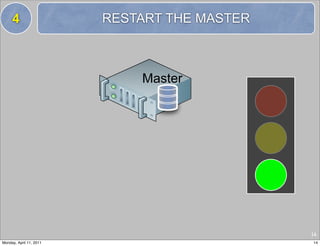
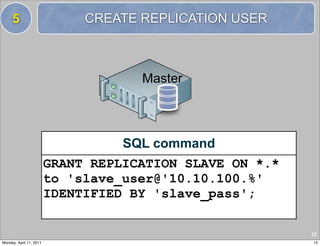
13
Monday, April 11, 2011 13](https://image.slidesharecdn.com/advancedmysqlreplicationtechniques-110411153301-phpapp02/85/Advanced-mysql-replication-techniques-13-320.jpg)

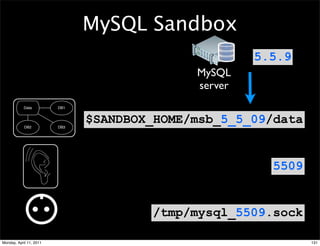
![8 ENABLE THE SLAVE
Slave 1
Configuration file
[mysqld]
server-id=2
relay-log=mysql-relay
read-only
# optional:
log-bin=mysql-bin 18
Monday, April 11, 2011 18](https://image.slidesharecdn.com/advancedmysqlreplicationtechniques-110411153301-phpapp02/85/Advanced-mysql-replication-techniques-18-320.jpg)





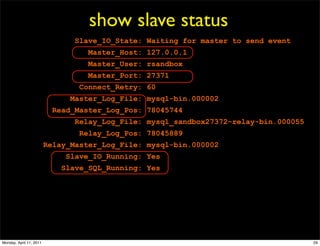
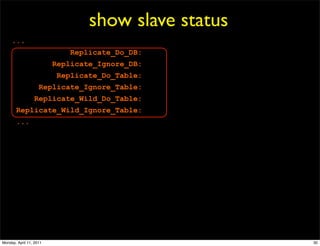
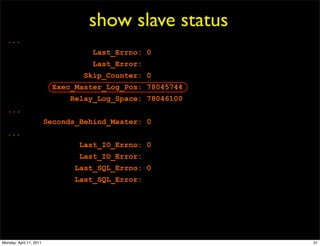


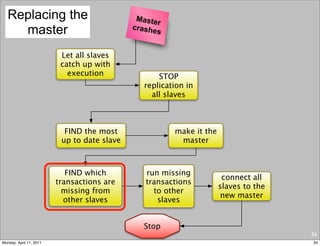








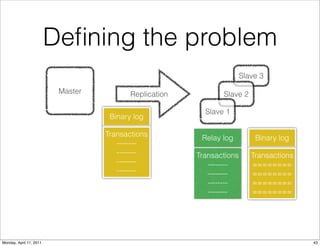
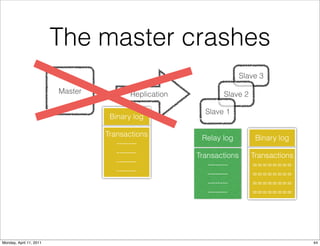
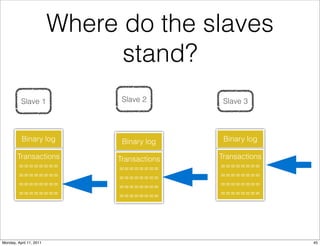
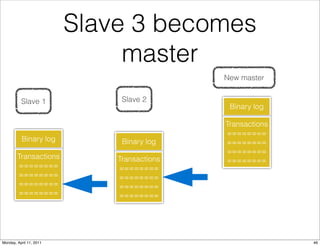
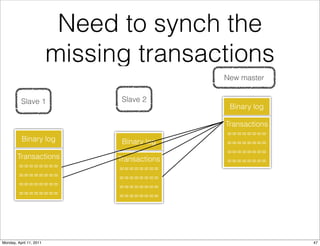
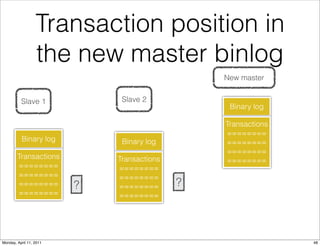


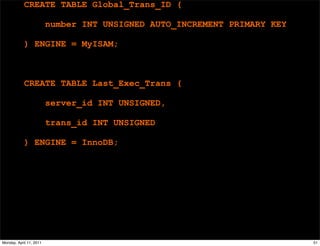
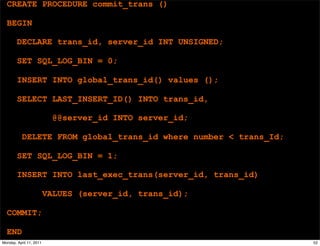
























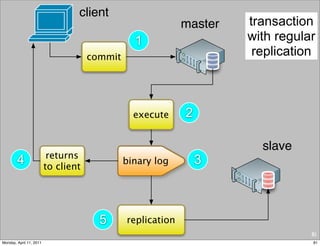
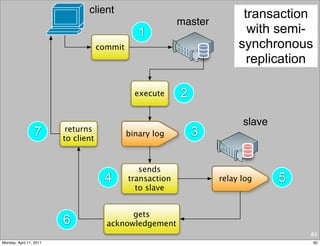

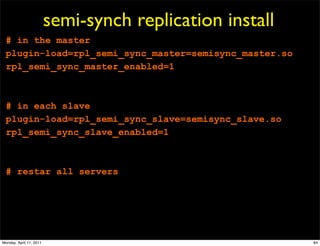
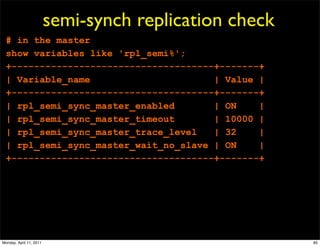
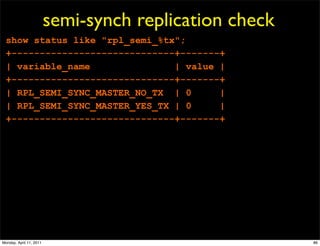
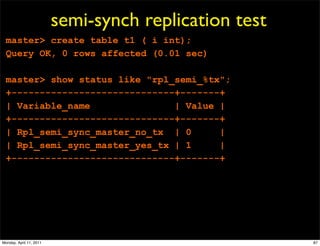
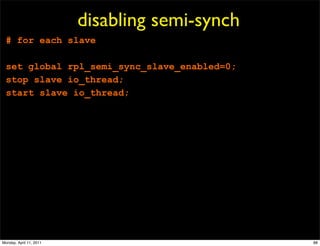
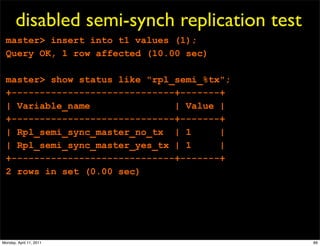






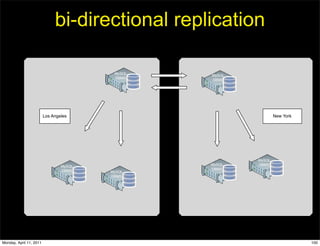


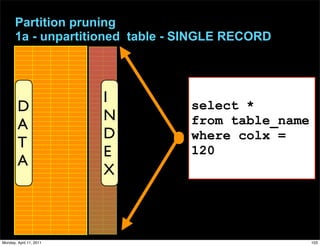

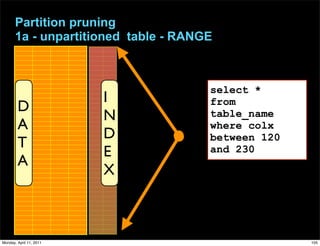

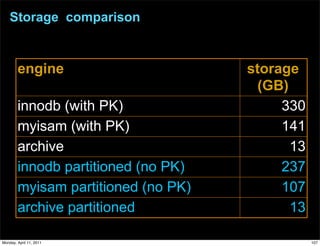
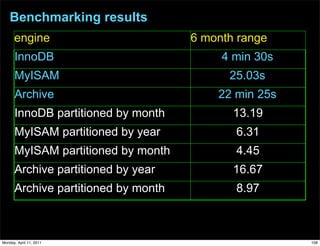



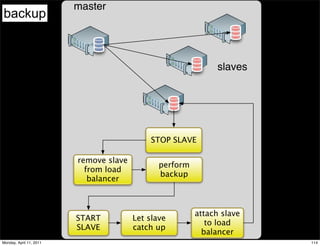




































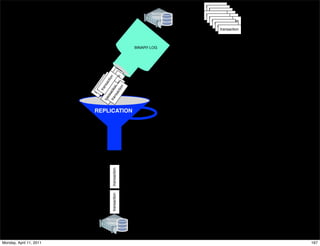

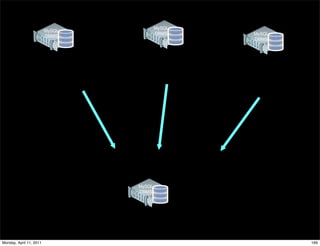

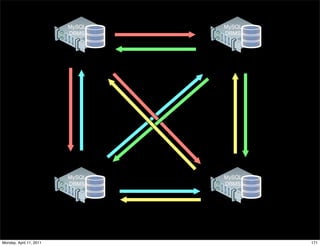




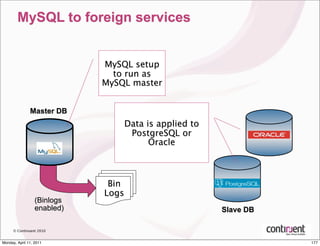
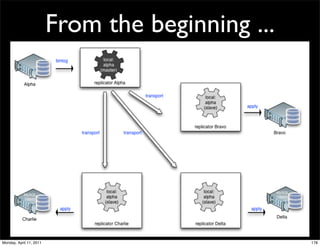
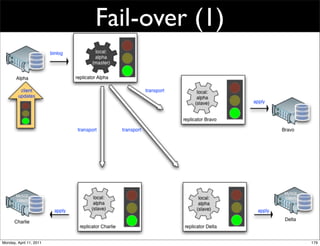
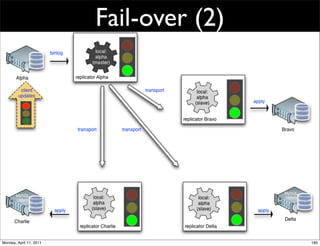
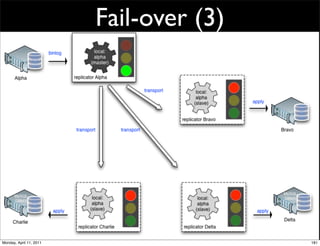
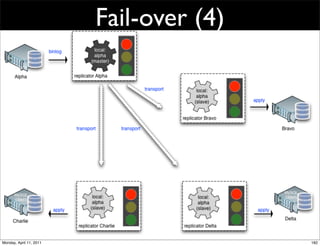
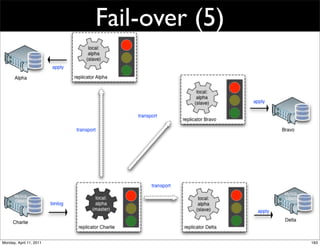
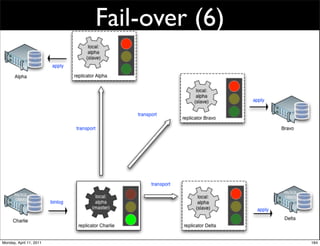
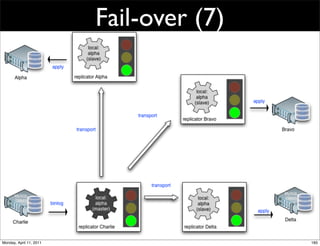
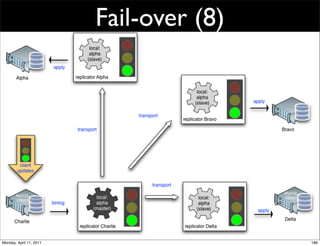

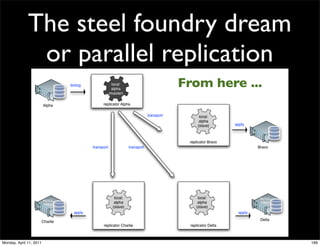
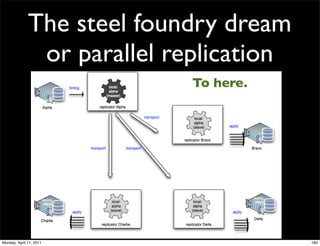







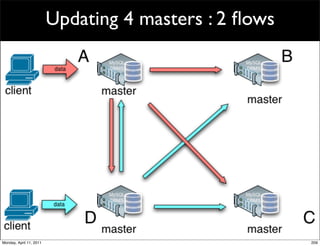
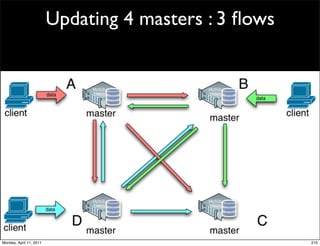
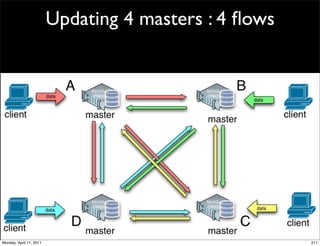



















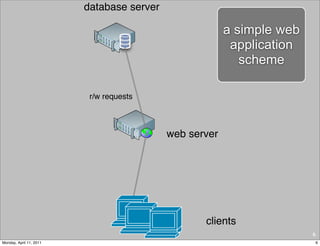
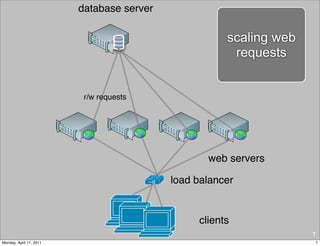
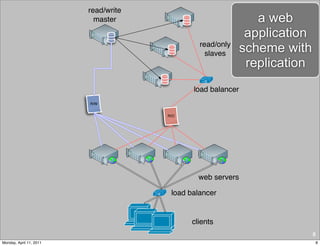
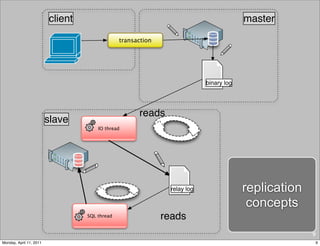
This document provides an overview of advanced MySQL replication techniques. It begins with an introduction to replication basics like principles, setup, and monitoring. It then discusses challenges with replication including master switchovers during failures and slaves falling behind. The document outlines various replication power techniques and features that can help address these issues like row-based and semi-synchronous replication. It also covers tools for replication and techniques for replication outside of the traditional setup.























































































