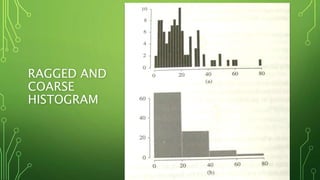
This document provides an overview of input modeling for simulation. It discusses the four main steps: 1) collecting real system data, 2) identifying the probability distribution, 3) estimating distribution parameters, and 4) evaluating goodness of fit. Common distributions are identified like Poisson, normal, exponential. Methods for identifying the distribution include histograms and Q-Q plots. Goodness of fit can be tested using chi-square and Kolmogorov-Smirnov tests. The document also discusses modeling non-stationary processes, selecting distributions without data, and multivariate/time-series input models.





























































![System simulation & modeling notes[sjbit]](https://cdn.slidesharecdn.com/ss_thumbnails/systemsimulationmodelingnotessjbit-110929031610-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
































































