Download to read offline



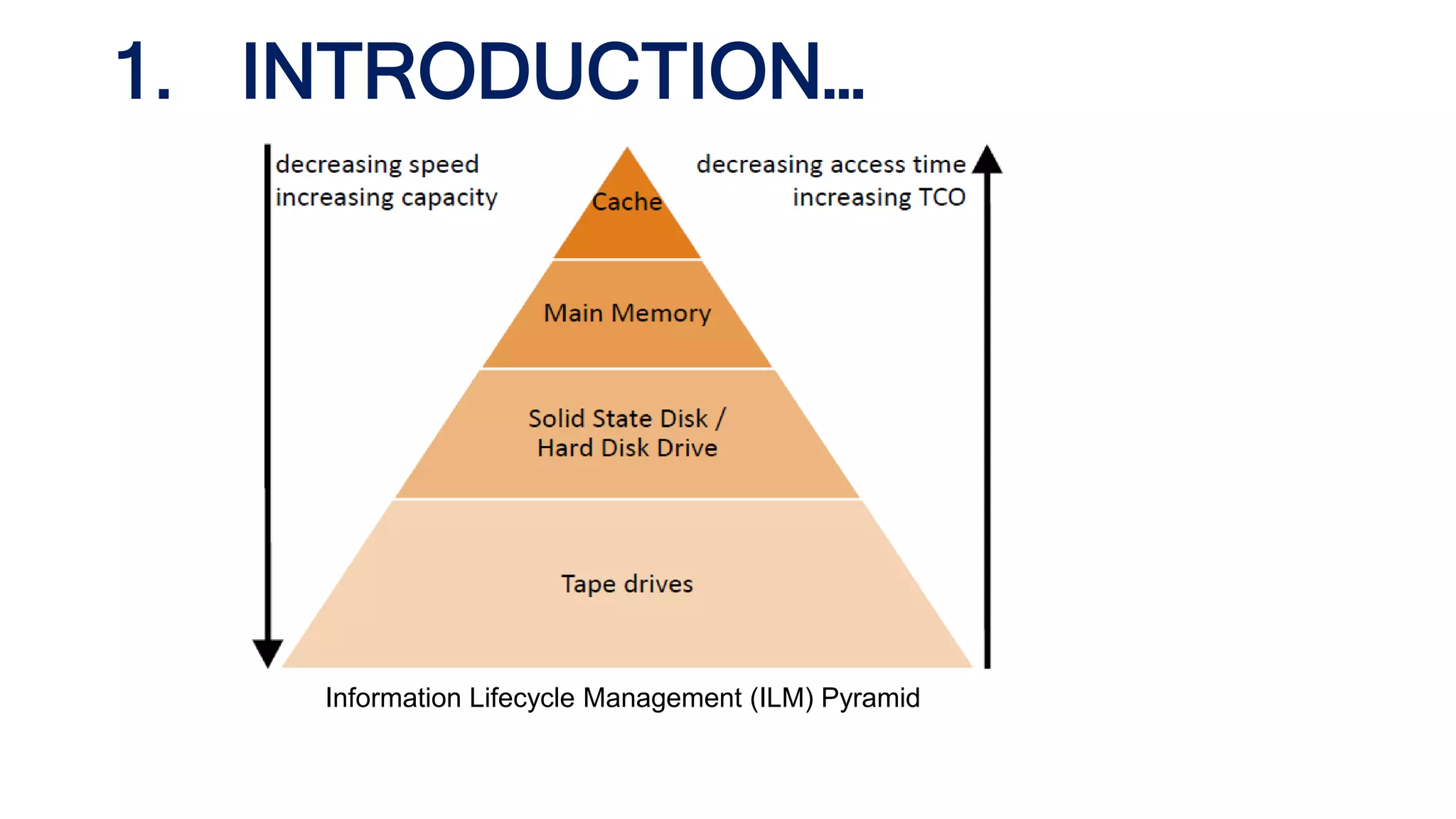



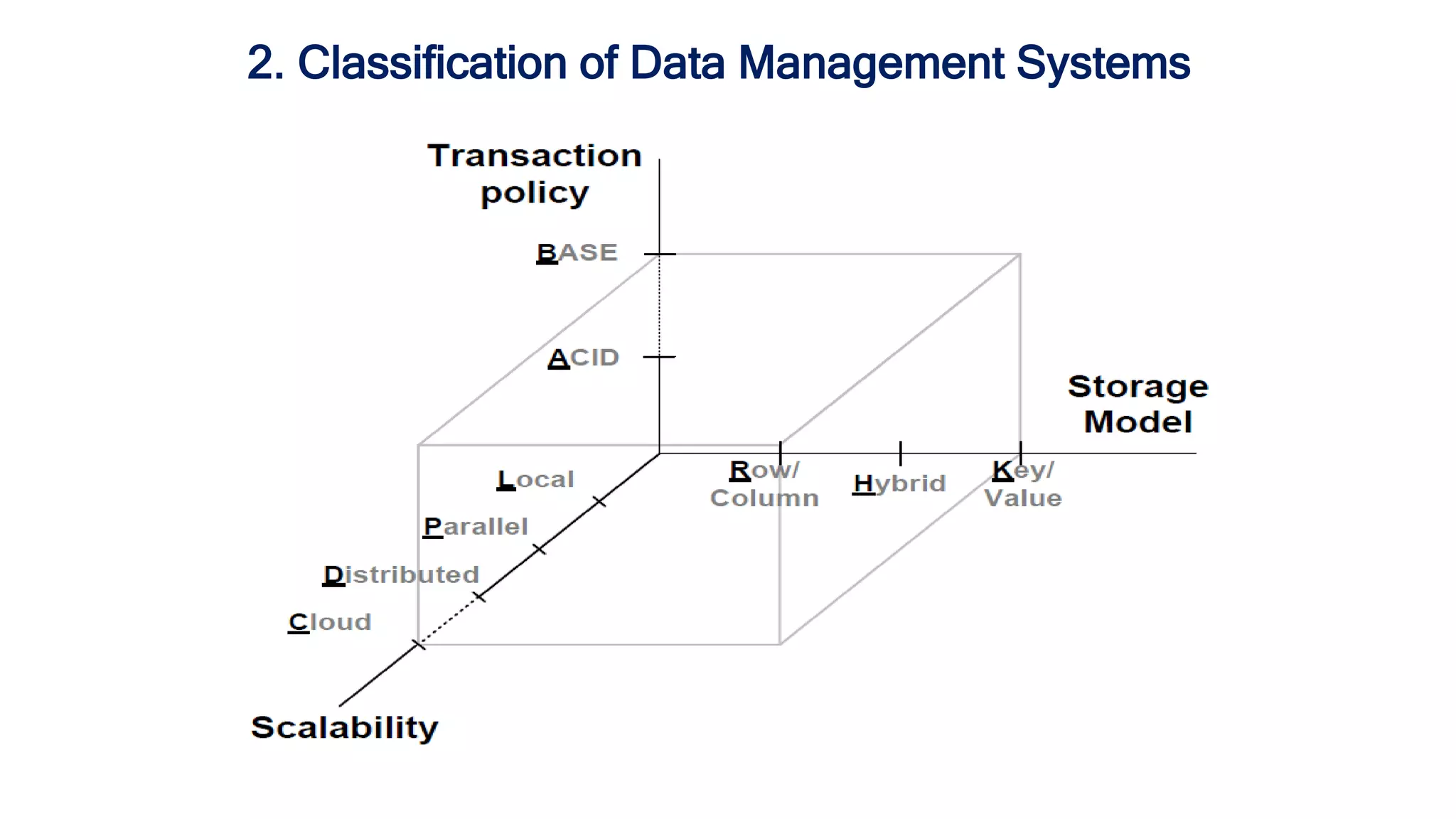




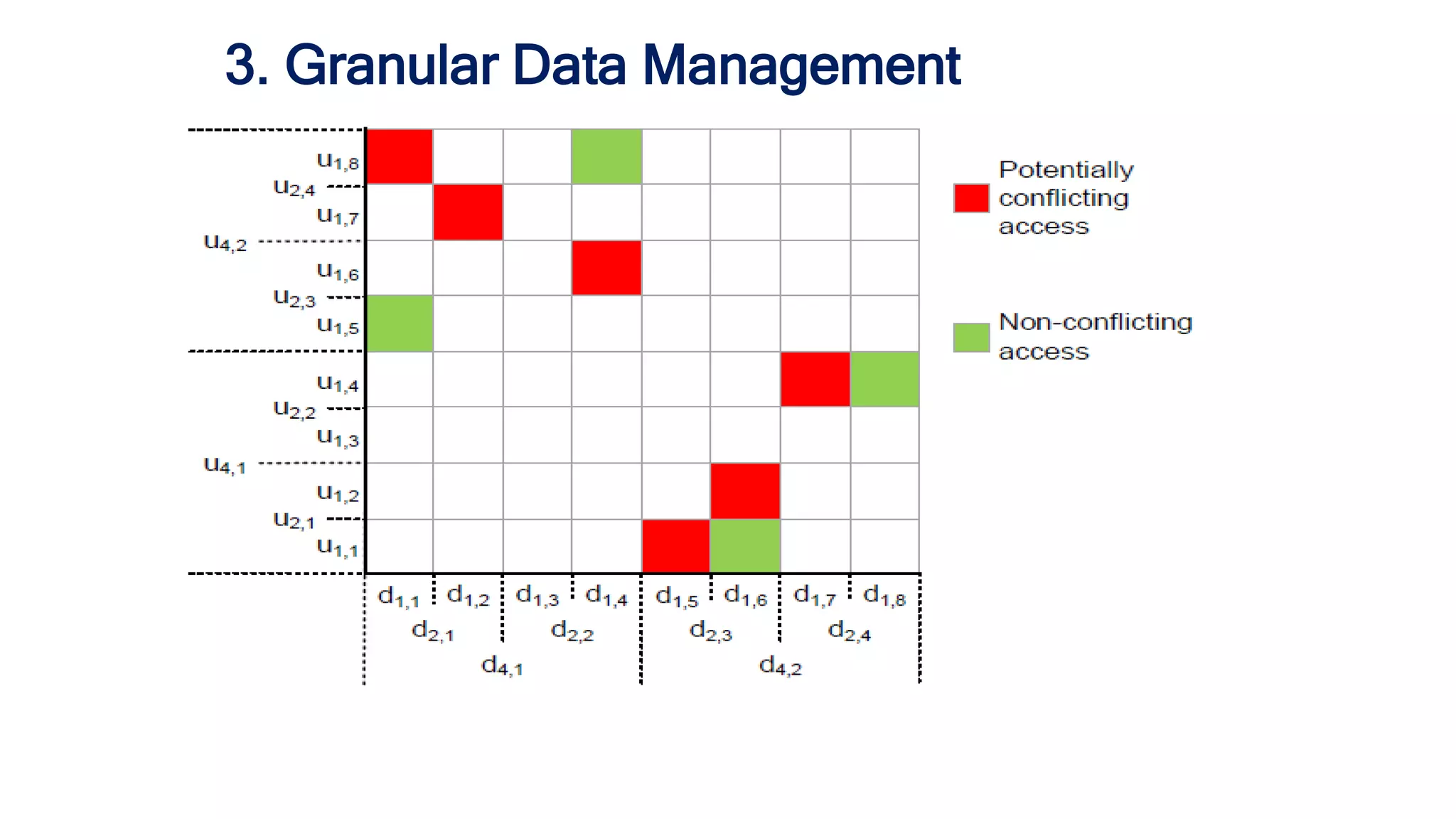



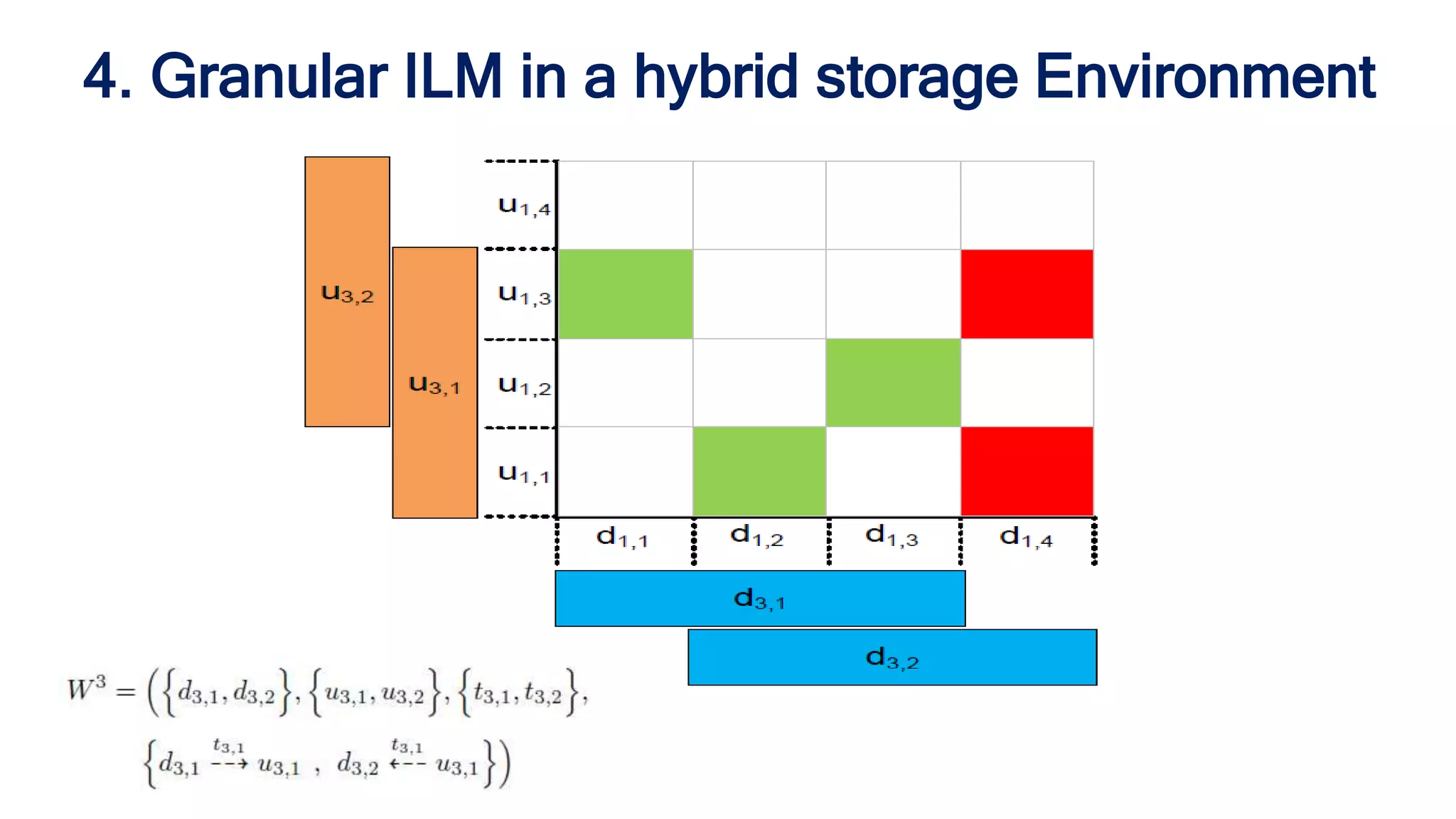
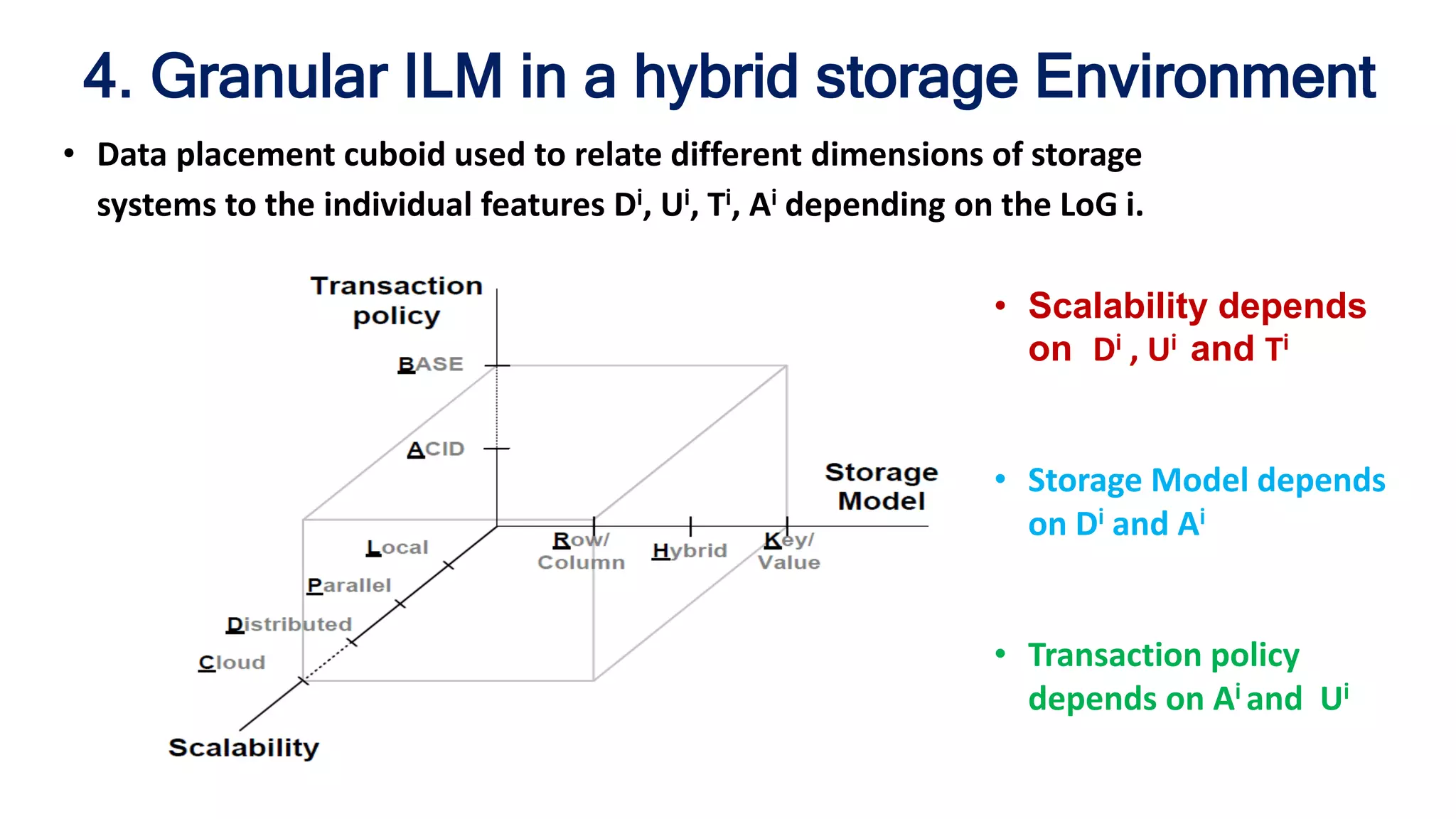



The document discusses granular data placement strategies for cloud platforms, emphasizing the evolution of information lifecycle management (ILM) in the context of hybrid storage environments. It proposes a new classification for data management systems that incorporates scalability, transaction policy, and storage models while advocating for a data-centric approach to better adapt to modern distributed applications. The research aims to create a flexible and sophisticated framework for data placement that integrates both on-site and cloud resources.



















![[IJET-V1I6P11] Authors: A.Stenila, M. Kavitha, S.Alonshia](https://cdn.slidesharecdn.com/ss_thumbnails/ijet-v1i6p11-151213120711-thumbnail.jpg?width=640&height=640&fit=bounds)

































































