Download to read offline

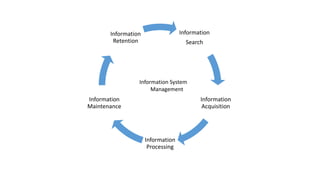


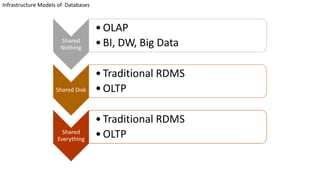
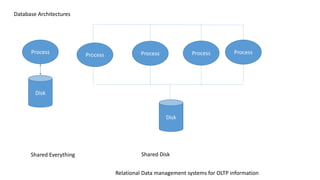
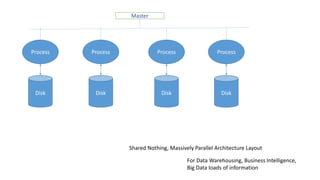

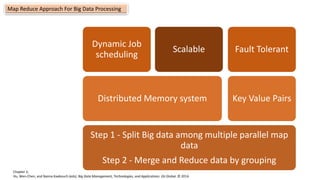

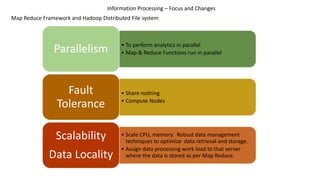









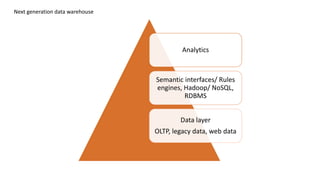

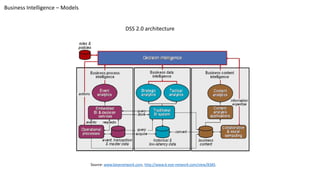
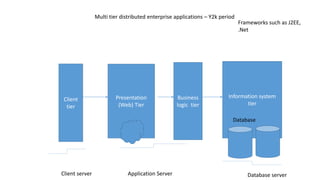








This document discusses information processing architectures and models. It covers topics like online transaction processing, online analytical processing, complex event processing, and massively parallel processing. It also discusses shared nothing, shared disk and shared everything infrastructure models. The document then covers database architectures, tradeoffs in task scheduling, and the map reduce approach used for big data processing. Other topics discussed include ACID, BASE and CAP theories; distributed information management; data warehousing models; business intelligence models; multi-tier enterprise applications; mobile data progress; social, mobile and cloud computing; and cloud infrastructures for information processing.

















































































