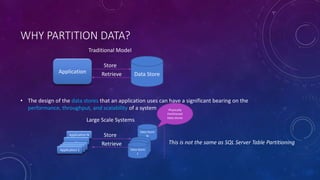
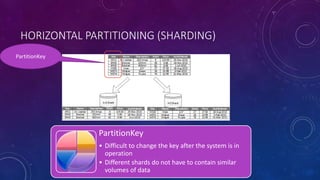
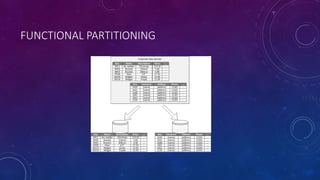
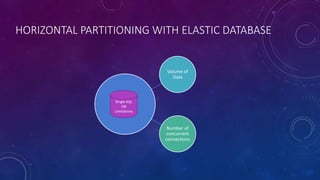
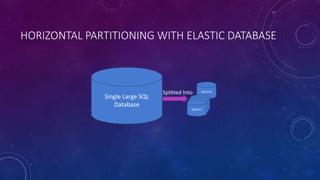
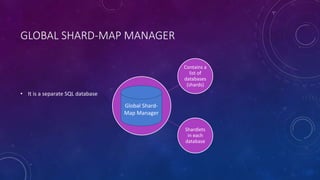
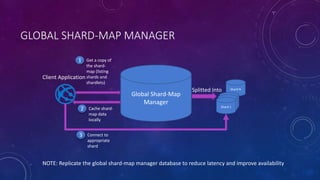
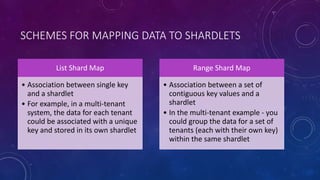
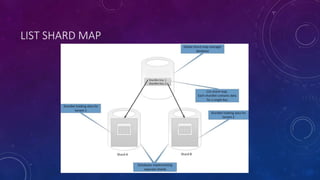
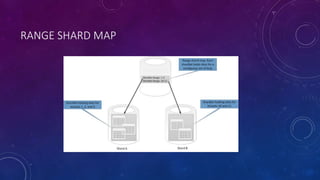
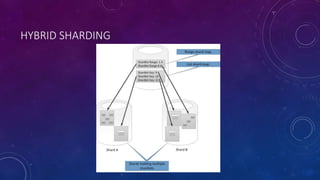
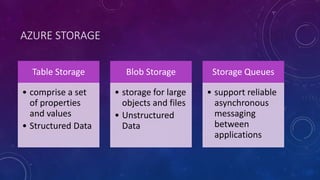
This document discusses data partitioning strategies for large scale systems. It explains that partitioning data across multiple data stores can improve performance, scalability, availability, security and operational flexibility of applications. The key partitioning strategies described are horizontal partitioning (sharding), vertical partitioning and functional partitioning. Horizontal partitioning involves splitting data into shards, each containing a subset of data. Vertical partitioning splits data into different fields or columns. Functional partitioning splits data based on functionality, such as invoicing vs product inventory. The document then focuses on horizontal partitioning and elastic databases, describing how data can be partitioned across multiple SQL databases while maintaining a global shard map for routing queries. It discusses issues to consider with partitioning such as minimizing cross-partition operations and maintaining referential


























































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)





