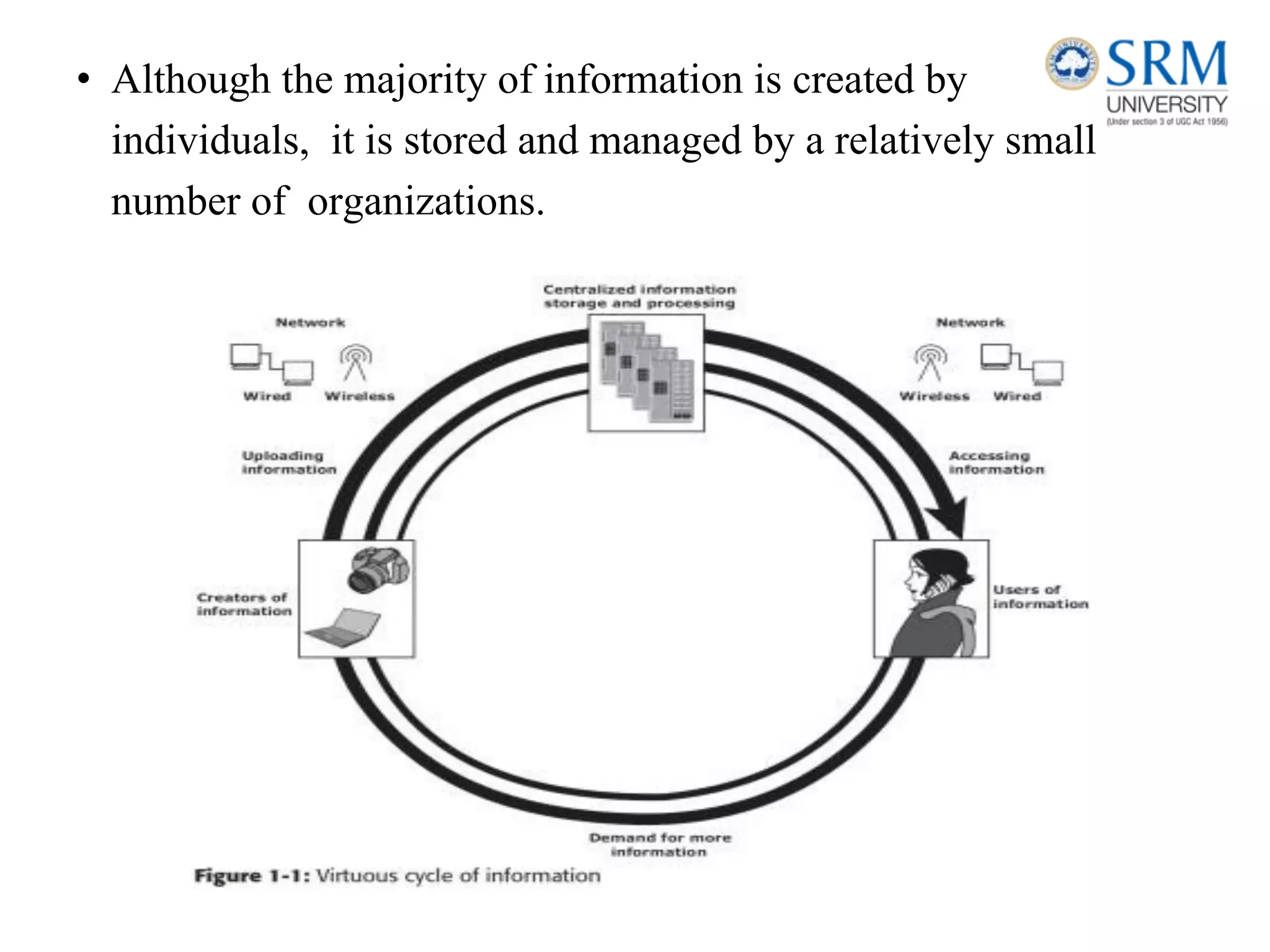
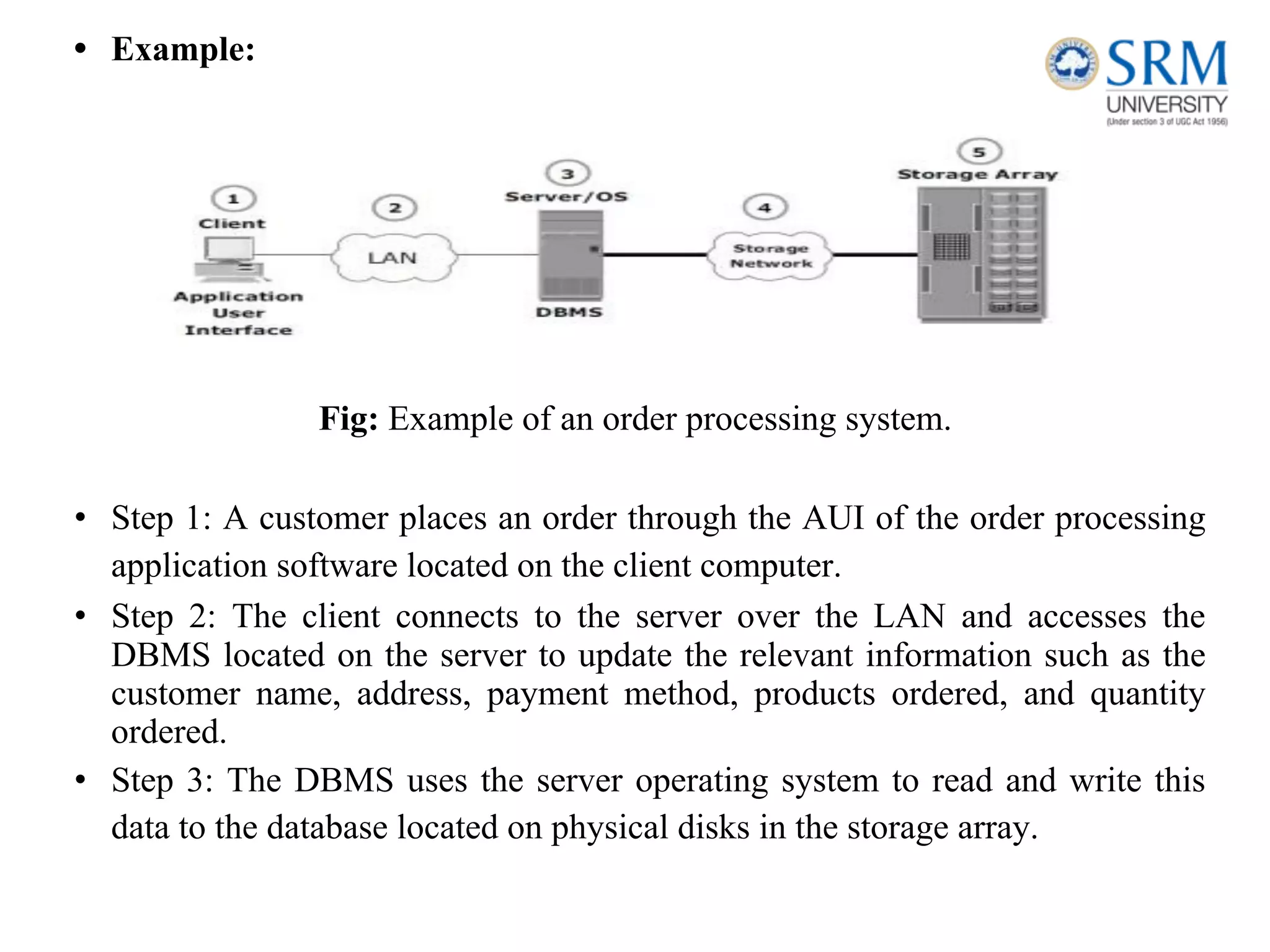
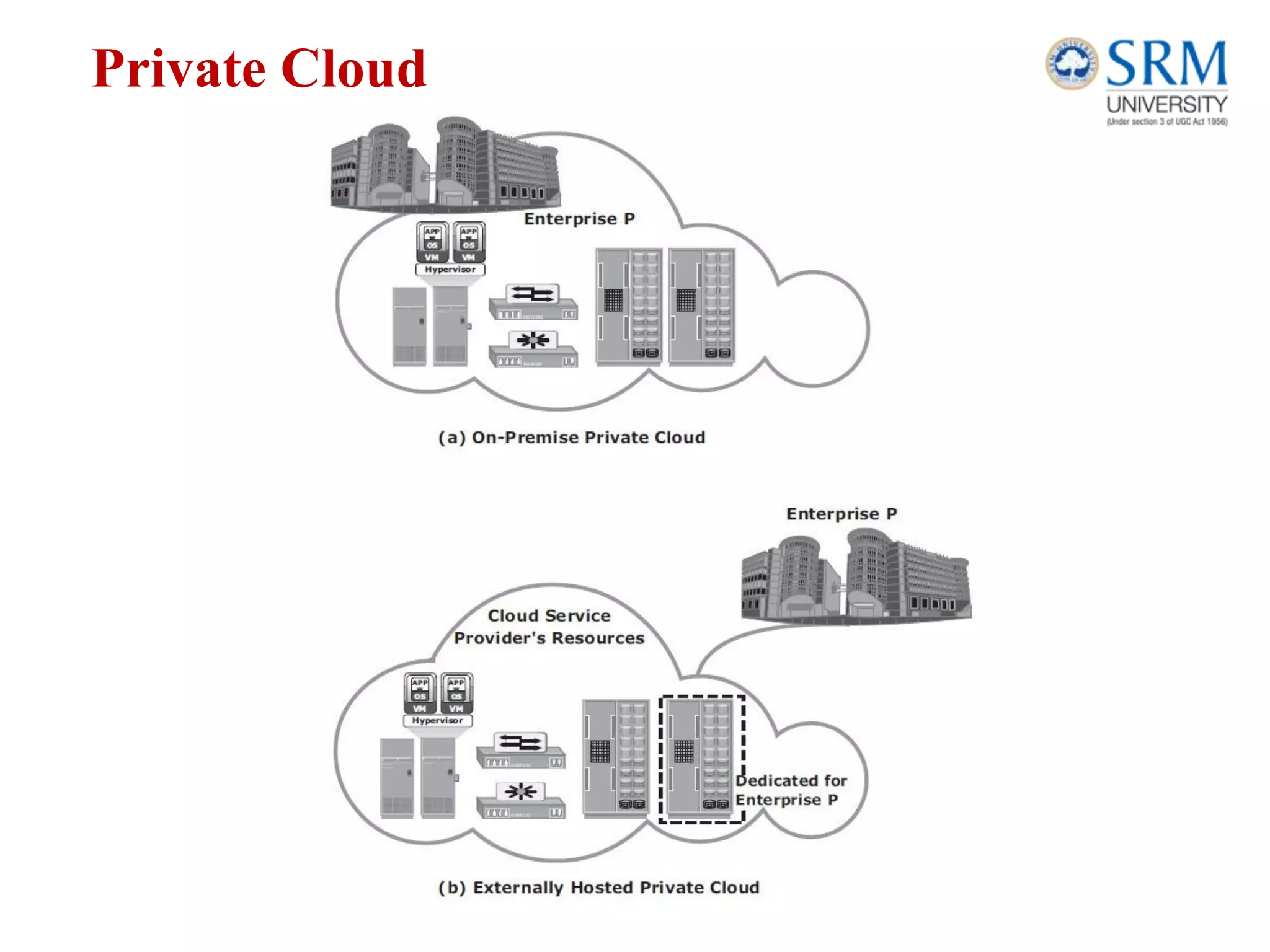
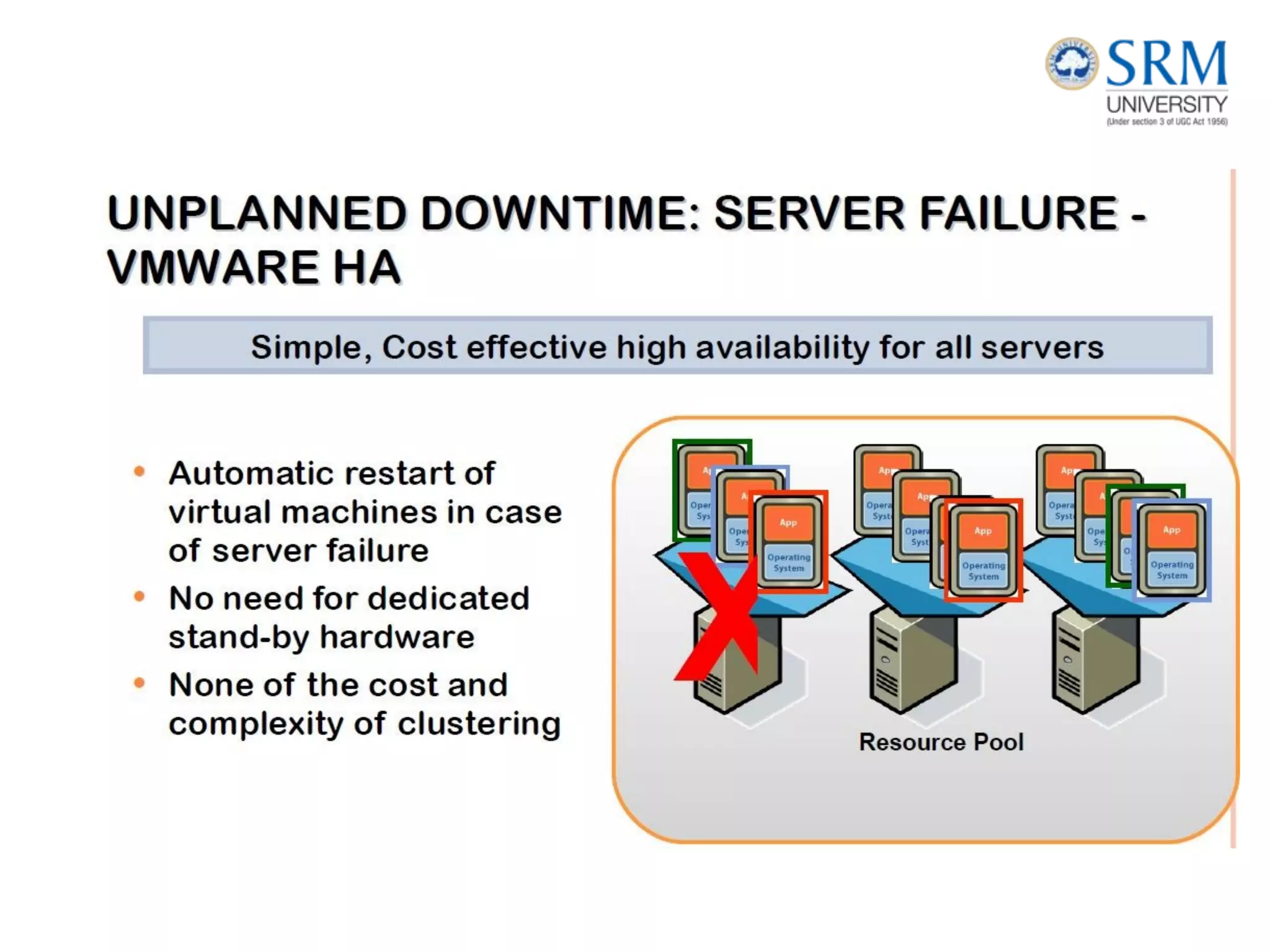
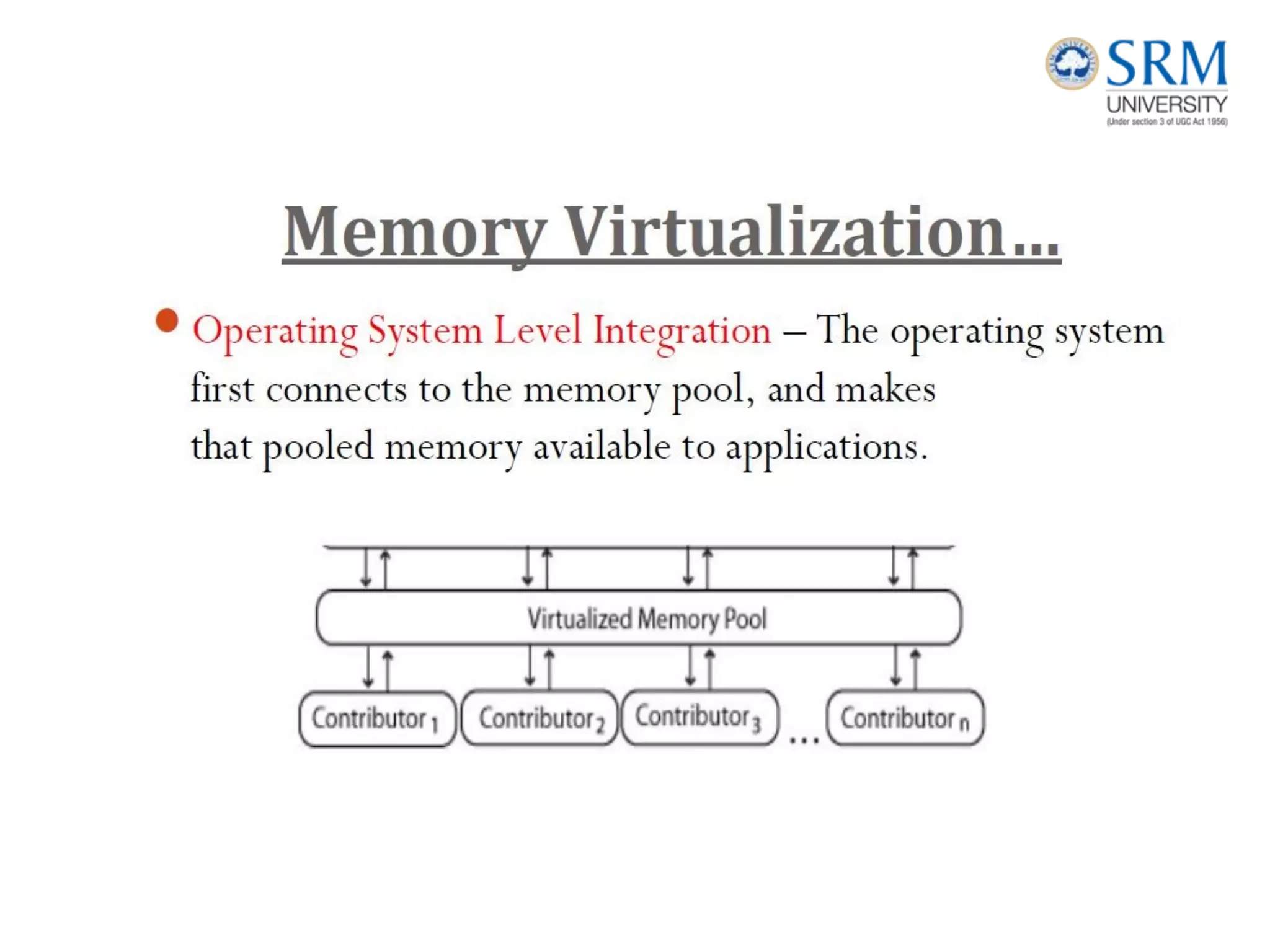
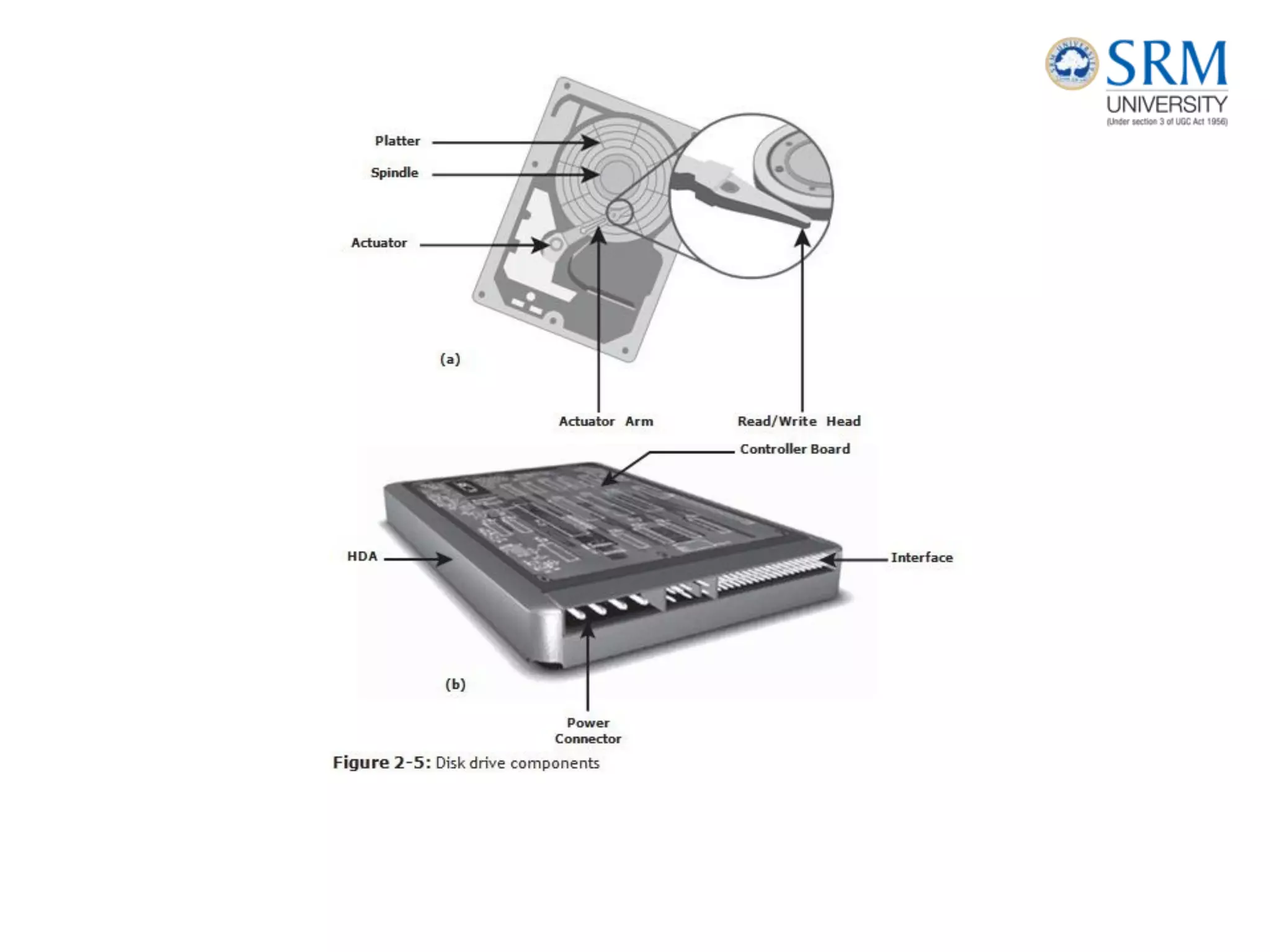
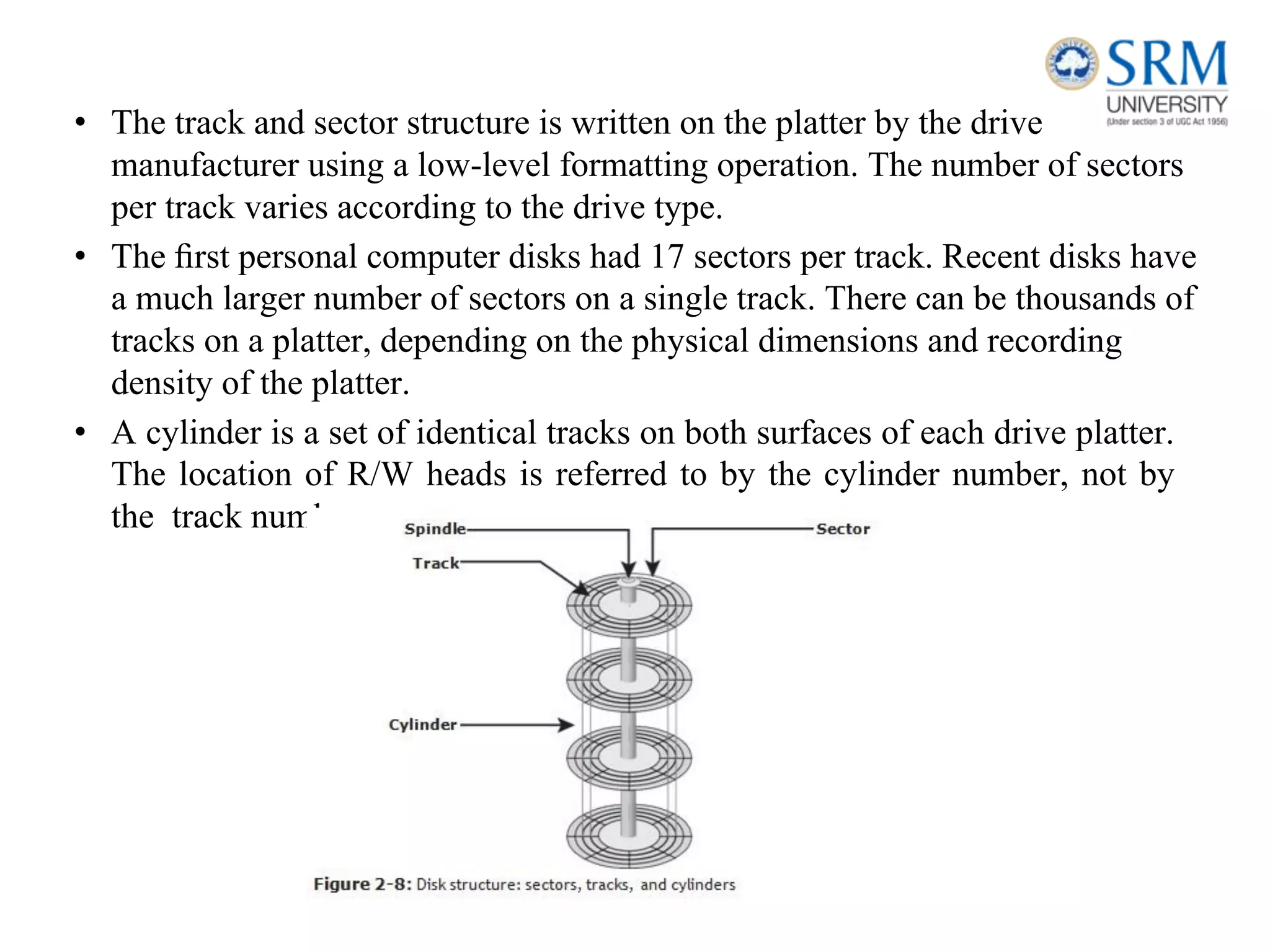
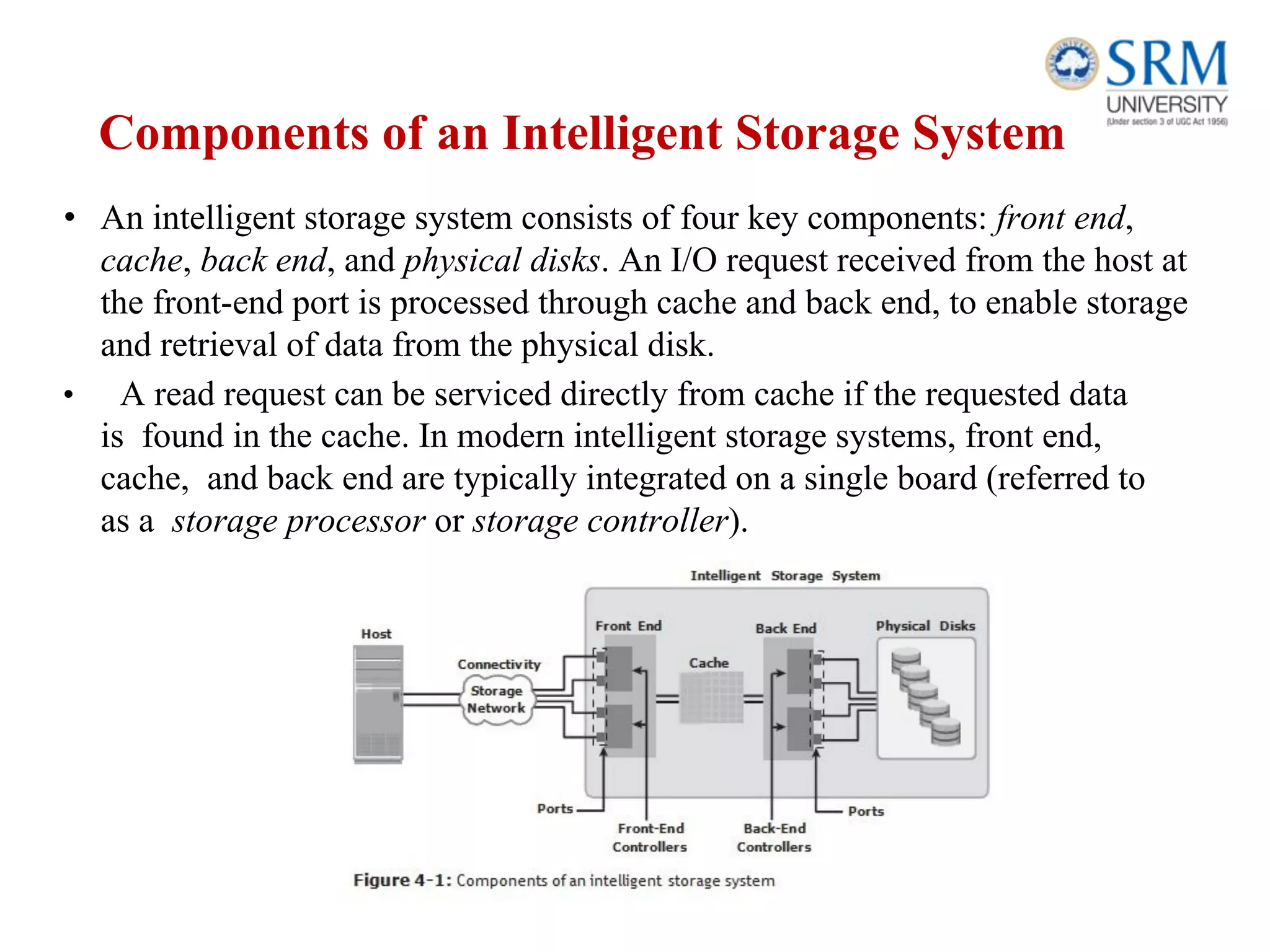
This document discusses information storage and management. It provides an overview of key topics including the evolution of storage architecture, data center infrastructure, and virtualization and cloud computing. Specifically, it outlines the core elements of a data center including applications, databases, servers, networks, and storage arrays. It also describes how these elements work together in an example order processing system. The document emphasizes that uninterrupted operation and high availability of data are critical requirements for data center infrastructure.