Recommended
PDF
PDF
PDF
DARM勉強会第3回 (missing data analysis)
PDF
PPTX
PDF
臨床疫学研究における傾向スコア分析の使い⽅ 〜観察研究における治療効果研究〜
PPTX
PPTX
PDF
PPTX
PPTX
PDF
PDF
PPTX
PDF
一般化線形モデル (GLM) & 一般化加法モデル(GAM)
PDF
PPTX
PDF
PDF
PDF
PDF
PDF
PDF
PDF
PPTX
PDF
Rによるやさしい統計学第20章「検定力分析によるサンプルサイズの決定」
PPTX
PDF
PDF
[読会]Logistic regression models for aggregated data
PPTX
More Related Content
PDF
PDF
PDF
DARM勉強会第3回 (missing data analysis)
PDF
PPTX
PDF
臨床疫学研究における傾向スコア分析の使い⽅ 〜観察研究における治療効果研究〜
PPTX
PPTX
What's hot
PDF
PPTX
PPTX
PDF
PDF
PPTX
PDF
一般化線形モデル (GLM) & 一般化加法モデル(GAM)
PDF
PPTX
PDF
PDF
PDF
PDF
PDF
PDF
PDF
PPTX
PDF
Rによるやさしい統計学第20章「検定力分析によるサンプルサイズの決定」
PPTX
PDF
Similar to ロジスティック回帰分析の入門 -予測モデル構築-
PDF
[読会]Logistic regression models for aggregated data
PPTX
PDF
第六回「データ解析のための統計モデリング入門」前半
PDF
PPTX
PPTX
PPTX
PDF
PDF
PDF
PDF
PDF
PDF
データ解析のための統計モデリング入門3章後半
PDF
2013.12.26 prml勉強会 線形回帰モデル3.2~3.4
PPTX
PDF
PDF
PDF
PDF
PDF
Osaka.Stan #3 Chapter 5-2
ロジスティック回帰分析の入門 -予測モデル構築- 1. 2. 3. 予測モデルとは?
“Predictive modelling is the process by which a model
is created or chosen to try to best predict the
probability of an outcome” Predictive Inference: An
Introduction 1983
“I define predictive modeling as the process of applying
a statistical model or data mining algorithm to data
for the purpose of predicting new or future
observations.” Galit Shmueli “To Explain or to Predict?” Statical
Science 2010
3
4. 5. 6. ロジスティック回帰
• 「回帰」とは結果変数 ( アウトカム ) と説
明変数の間に式を当てはめ、どれくらい
説明できるか定量化 ( 関連 ) したものであ
る
• 「打ち切りのない、結果変数が 2 値であ
るデータにはロジスティック回帰分析が
使われる。」
• なぜ?
6
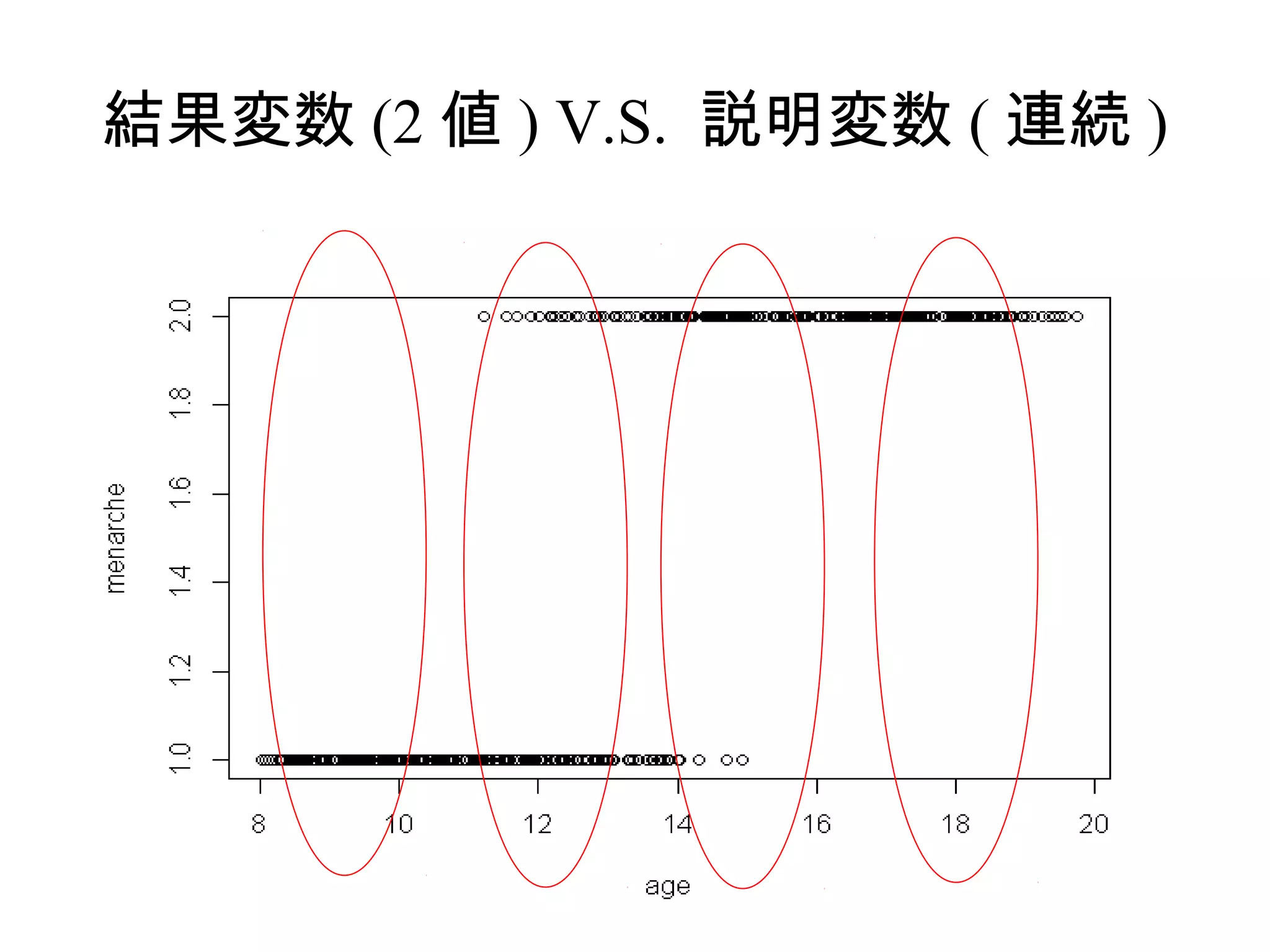
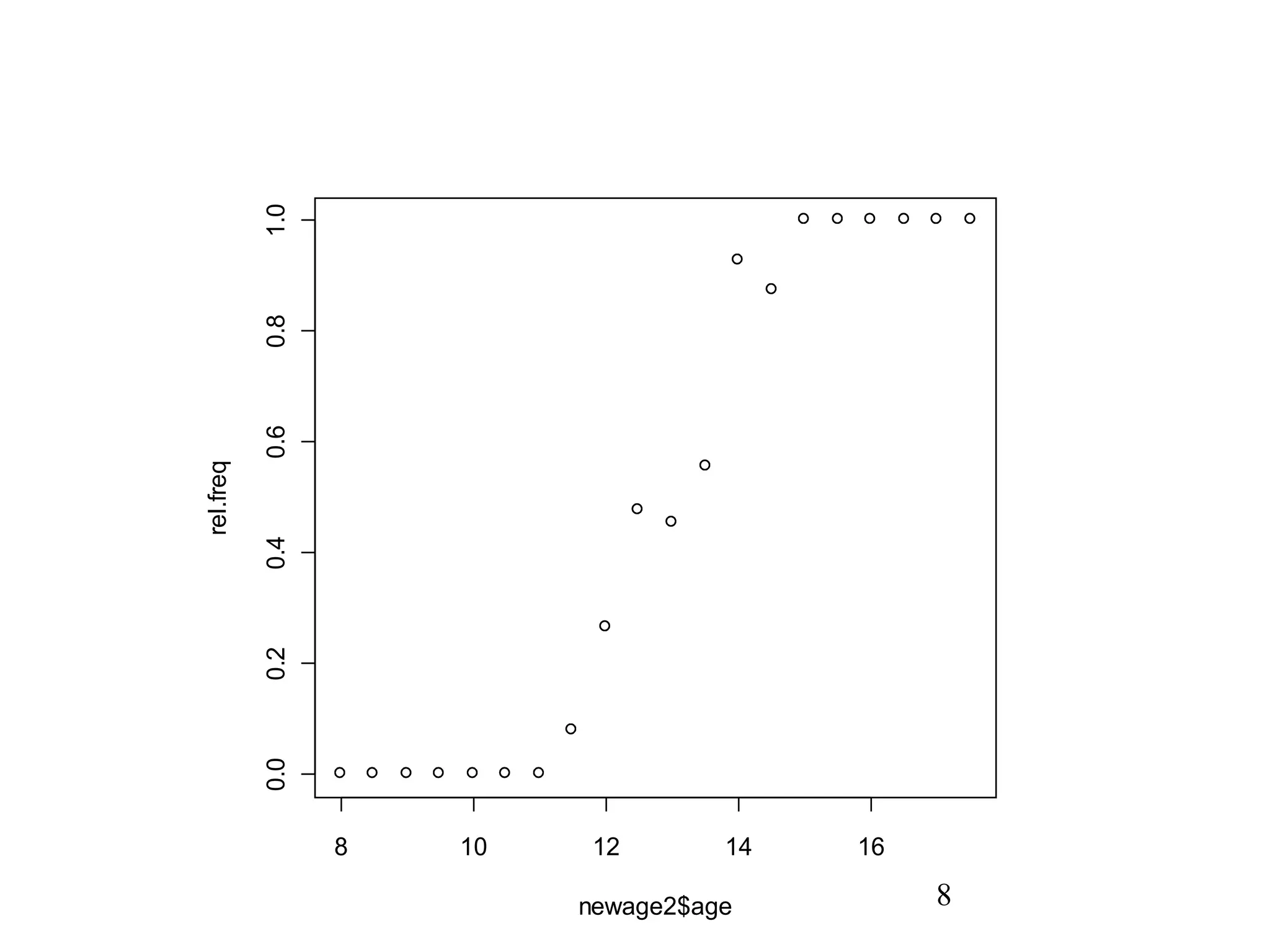
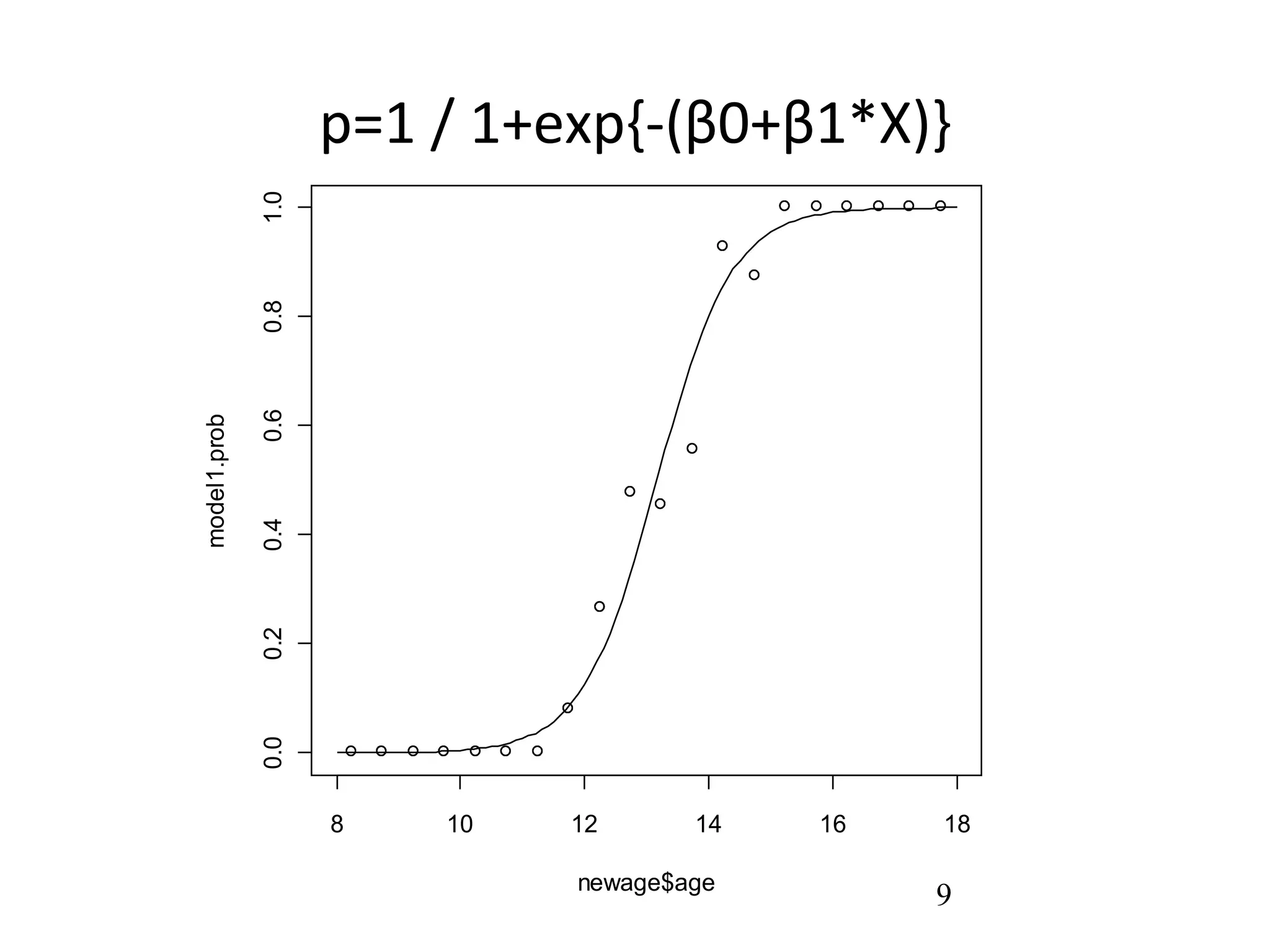
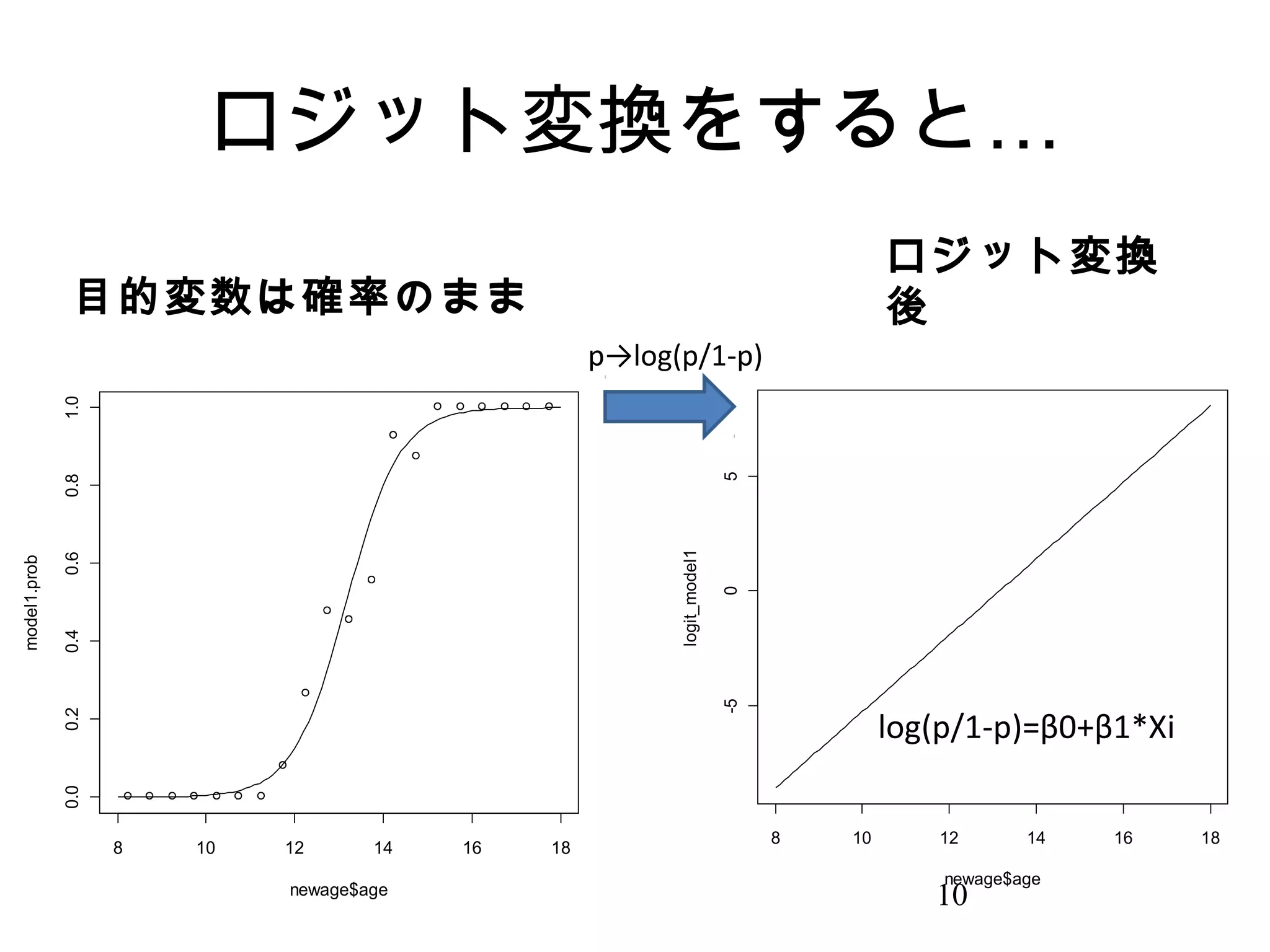
7. 8. 9. 10. 11. なぜロジスティックモデル?
• 大きく 2 つの利点がある
– 1. アウトカムが 2 値データのときはシグ
モイドカーブが合理的
– 2. 係数が対数オッズになる。このため、
結果が理解されやすい→医者にとっては大
事
11
12. ロジスティック分析の流れ
• モデル作成 ( 変数選択→ main effect model→
交互作用項検討 )
• ↓
• モデル評価 (determination?calibration?)
• ↓
• Validation( 内的妥当性→外的妥当性 )
• ↓
• 完成。
12
13. R での使い方
• Hosmer-Lemeshow “Applied Logistic
regression” Wiley 2012 から
LowBirthWeightData
• N=189 、 11 の変数からなるデータセット
• R コーディングはハンドアウト
13
14. 15. 3 つのモデル
• null モデル ( 変数のないモデル )
• low~1
• 説明変数が一つだけのモデル
• low~smoke
• 多変数モデル
• low~smoke+age+race+lwt+smoke:race+age:sm
15
oke+age:race+smoke:age:race
16. smoke モデルの結果出力
Call:
glm(formula = low ~ smoke, family = binomial, data = lbw)
Deviance Residuals:
Min
1Q Median
3Q
Max
-1.0197 -0.7623 -0.7623 1.3438 1.6599
Wald 統計量≒ Z
Coefficients : Estimate Std. Error z value Pr(>|z|)
(Intercept)
-1.0871 0.2147
-5.062 4.14e-07 ***
smokeYes
0.7041
0.3196
2.203
0.0276 *
--Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 234.67 on 188 degrees of freedom
Residual deviance: 229.80 on 187 degrees of freedom
AIC: 233.8
Number of Fisher Scoring iterations: 4
16
17. smoke モデルの結果出力
Call:
glm(formula = low ~ smoke, family = binomial, data = lbw)
尤度 (likelihood) とは「あるモデルで
Deviance Residuals:
Min
1Q Median
3Q
Max
現実のデータが得られる確率」
-1.0197 -0.7623 -0.7623 1.3438 1.6599
最尤法→尤度を最大化するパラメータ
Coefficients : Estimate Std. Error z value Pr(>|z|)
の極値を得る方法 4.14e-07 ***
(Intercept)
-1.0871 0.2147
-5.062
smokeYes
0.7041
0.3196
2.203 0.0276 *
--Residual deviance = -2log(likelihood of fitted
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
model/ likelihood of saturated model)
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 234.67 on 188 degrees of freedom
Residual deviance: 229.80 on 187 degrees of freedom
AIC: 233.8
Number of Fisher Scoring iterations: 4
17
18. Null モデルの出力結果
•
•
•
•
•
•
•
•
•
•
•
•
•
•
glm(formula = low ~ 1, family = binomial, data = lbw)
Deviance Residuals:
Min
1Q Median
3Q
Max
-0.8651 -0.8651 -0.8651 1.5259 1.5259
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -0.790
0.157
-5.033 4.84e-07 ***
Residual deviance = -2log(likelihood of fitted
--model/ likelihood of saturated model)
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 234.67 on deviance(Saturated model) = 0
188 degrees of freedom
deviance(null model) = 234.67
Residual deviance: 234.67 on 188 degrees of freedom
deviance が小さいほどあてはまりは良
AIC: 236.67
い
Number of Fisher Scoring iterations: 4
18
AIC = Deviance + 2*N of parameter
19. smoke モデルの結果出力
Call:
glm(formula = low ~ smoke, family = binomial, data = lbw)
Deviance Residuals:
Min
1Q Median
3Q
Max
-1.0197 -0.7623 -0.7623 1.3438 1.6599
Coefficients : Estimate Std. Error z value Pr(>|z|)
(Intercept)
-1.0871 0.2147
-5.062 4.14e-07 ***
smokeYes
0.7041
0.3196
2.203 0.0276 *
--Residual codes: 0 ‘***’ 0.001 ‘**’ 0.01 fitted ‘.’ 0.1 ‘ ’ 1
Signif. deviance = -2log(likelihood of ‘*’ 0.05
model/ likelihood of saturated model)family taken to be 1)
(Dispersion parameter for binomial
Null deviance: 234.67 on 188 degrees of freedom
Residual deviance: 229.80 on 187 degrees of freedom
AIC: 233.8
Number of Fisher Scoring iterations: 4
19
AIC = Deviance + 2*N of parameter
20. 多変数モデル
glm(formula = low ~ age + race + smoke + lwt + age:race + age:smoke +
age:lwt + race:smoke + race:lwt + smoke:lwt + age:race:smoke +
age:race:lwt + age:smoke:lwt + race:smoke:lwt + age:race:smoke:lwt,
family = binomial, data = lbw)
Deviance Residuals:
Min
1Q Median
3Q
Max
-1.4788 -0.9690 -0.5532 1.2638 2.3464
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept)
19.081932 18.327804 1.041 0.298
age
-0.801232 0.763315 -1.050 0.294
race
-9.656472 8.229436 -1.173 0.241
smokeYes
-25.658851 21.995005 -1.167 0.243
lwt
-0.138424 0.139208 -0.994 0.320
(以下略)
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 234.67 on 188 degrees of freedom
Residual deviance: 210.12 on 173 degrees of freedom
20
•AIC: 242.12
21. ロジスティック分析の流れ
• モデル作成 ( 変数選択→ main effect model→
交互作用項検討 )
• ↓
• モデル評価 (determination?calibration?)
• ↓
• Validation( 内的妥当性→外的妥当性 )
• ↓
• 完成。
21
22. 23. 変数選択
• Subject matter knowledge
• ニュアンスとしては、「アウトカムと変
数の関係について、先行研究や専門的な
見地から明らかな相関または因果がある
とわかっていること」
• 基本的に変数は subject matter knowledge に
基づいて選択される。 ( データは一切みな
い)
• 説明モデルでは機械的選択は推奨されな
23
い。でも予測モデルならありかも。
24. 25. 26. アルゴリズム選択
• いろいろあるが、どれが一番いいという
のはない。
• Hosmer, Lemeshow”Applied logistic
regression”→ purposeful selection
• Styerberg “Clinical Prediction Models”→
bayesian model averaging(Package”BMA”),
bootstrapping(Package”bootStepAIC”),
Lasso(Package”glmnet”)
• AIC
26
27. 交互作用項
• 交互作用も基本的に subject matter
knowledge に基づいて加える。
• 重要な交互作用の例 : Harrel “Regression
modeling strategies” より
• 年齢とリスク因子 (age:hypertension)
• 年齢と疾患のタイプ (age:diabetes)
• 人種と疾患
• 季節とある疾患 (season:diarrea)
27
• 症候同士 (consciousness:blood pressure)
28. Hierarchically well-formulated
• 例えば、 4 つの共変量があれば理論的には
10 通りの交互作用の組み合わせがある。
• 全てをモデルに投入すると前述した
overfitting 、パワーの問題が生じる
• 交互作用項を検討する原則 : Hierarchically
well-formulation
• 高次の交互作用項 (3way, 4way) はより低次
の交互作用項あるいは main effect に依存す
28
29. Example
• Outcome ~ P1 + P2 + P3 + P1:P2 + P1:P3 +
P2:P3 + P1:P2:P3
• これらの予測因子のの中で P1,P2 が現実的
に相互作用を起こしえない場合、 P1:P2 は
除去される。
• 同時により高次の交互作用項 P1:P2:P3 も
除去される (Hierarchically well-formulated)
• その後は統計学的検定により残すか決定
する
29
30. 例: lbw でのモデル構築
• アウトカムは low として予測モデルを構
築する
• subject matter knowledge は分かっていない
とする
• 全ての変数は smoke, race, age, lwt である。
• 強制投入はできないので、アルゴリズム
選択をしてみる。 purposeful selection
• Model: low~age+race+smoke+lwt 30
31. ロジスティック分析の流れ
• モデル作成 ( 変数選択→ main effect model→
交互作用項検討 )
• ↓
• モデル評価 (determination?calibration?)
• ↓
• Validation( 内的妥当性→外的妥当性 )
• ↓
• 完成。
31
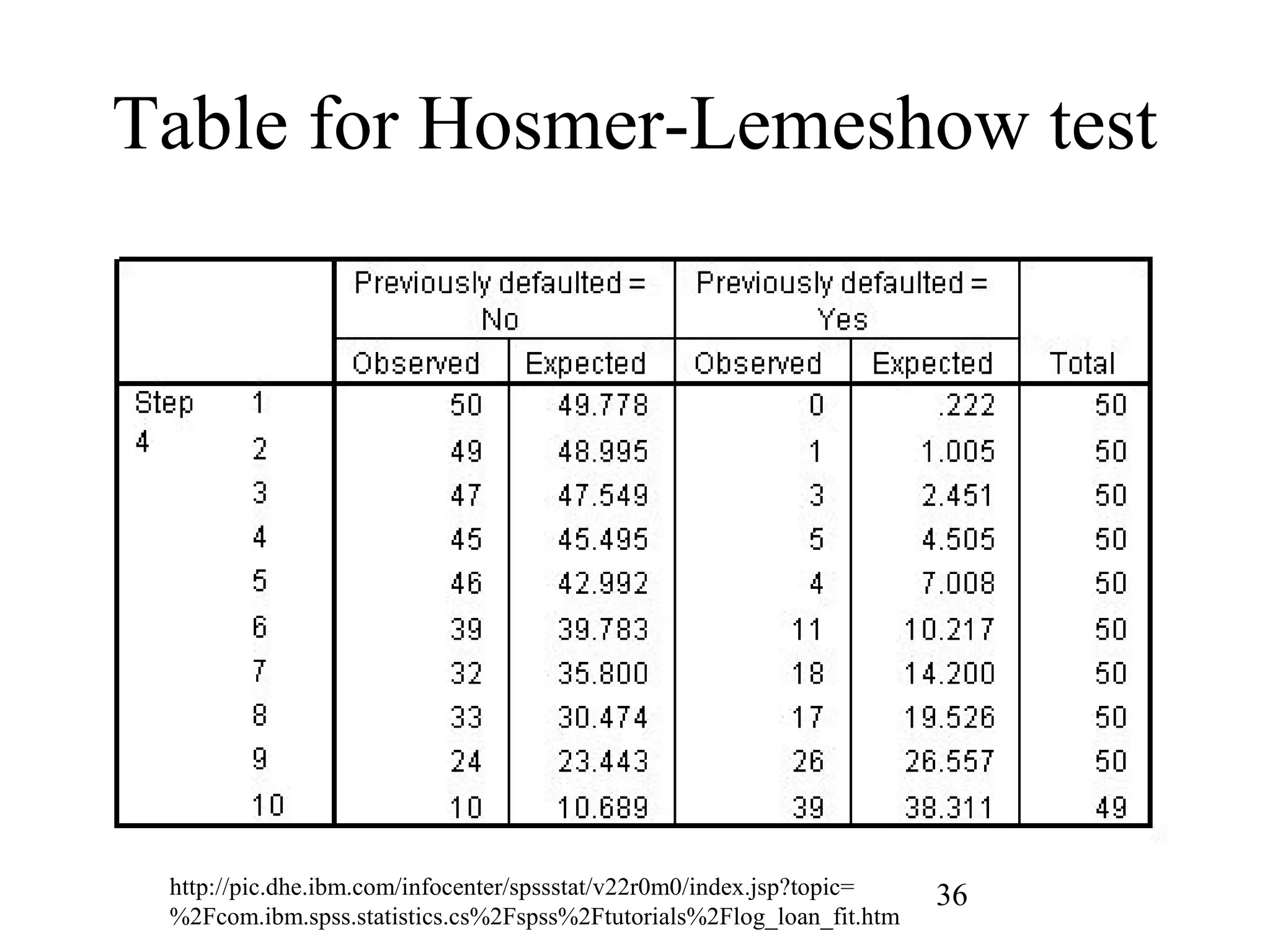
32. 33. 34. 35. 36. Table for Hosmer-Lemeshow test
http://pic.dhe.ibm.com/infocenter/spssstat/v22r0m0/index.jsp?topic=
%2Fcom.ibm.spss.statistics.cs%2Fspss%2Ftutorials%2Flog_loan_fit.htm
36
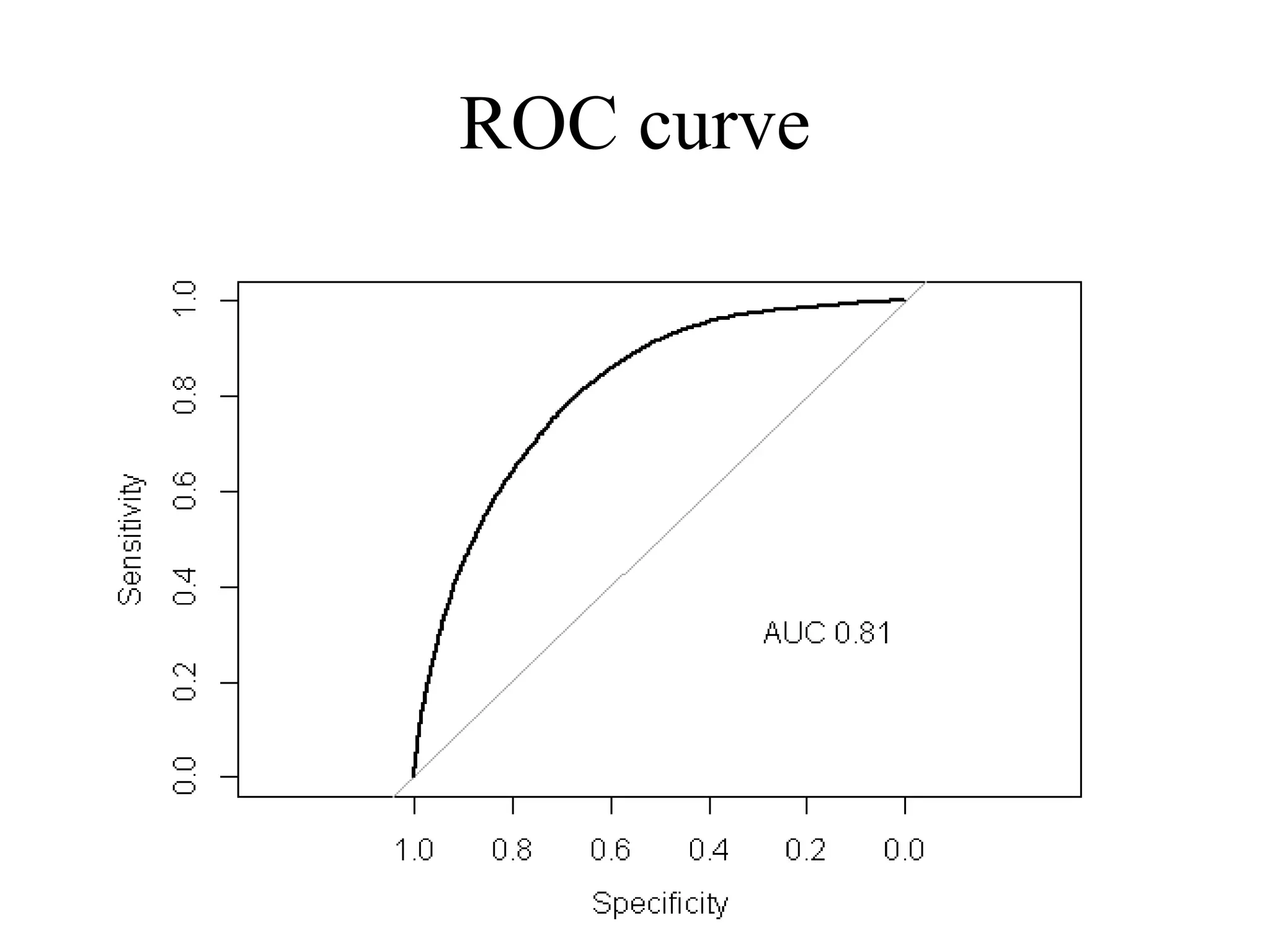
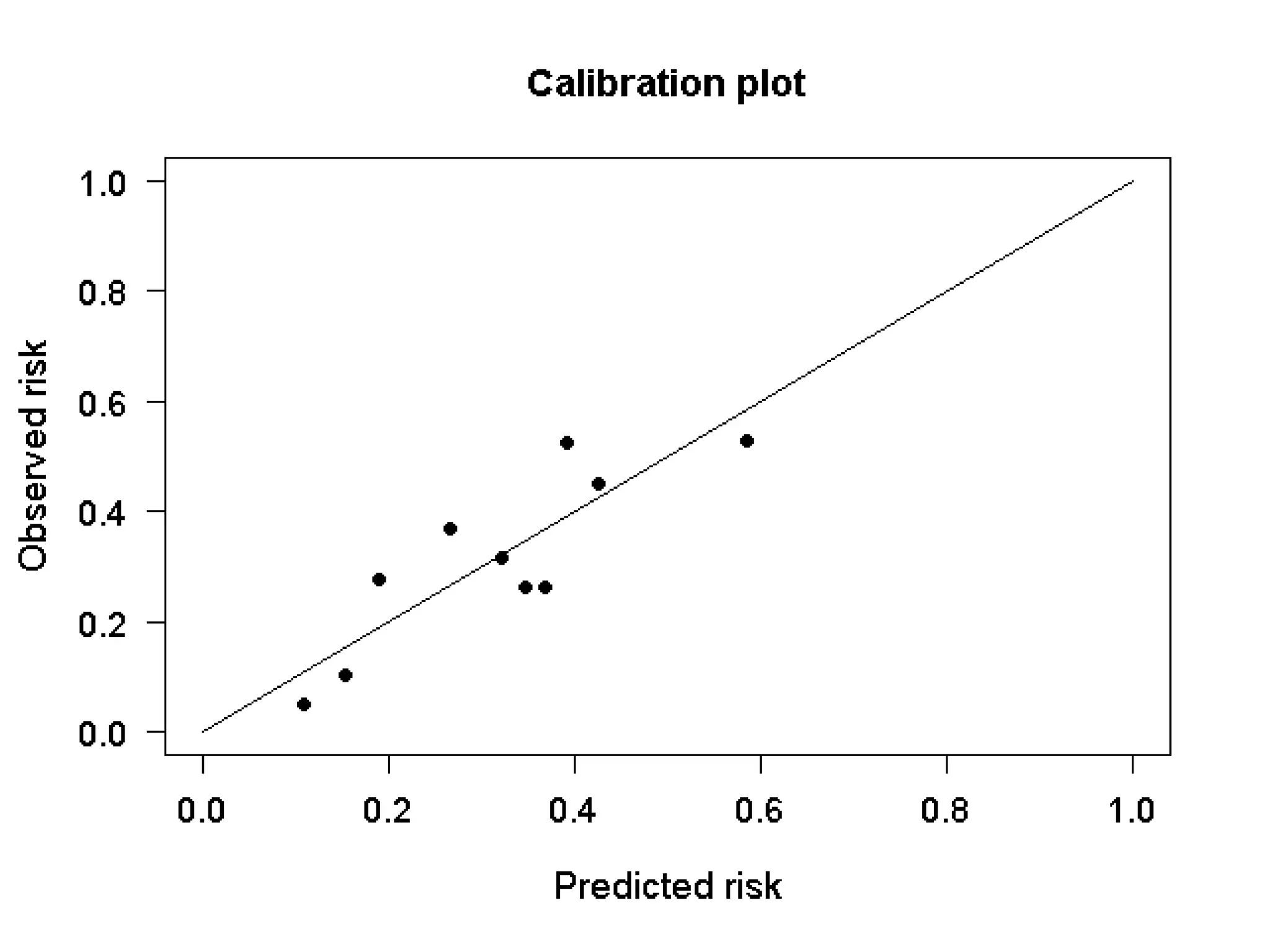
37. 38. Discrimination V.S. Calibration
• この両者はトレードオフの関係にある。
• アウトカムがすでに起きている ( 診断目的
など ) ものならば、アウトカムへの分類を
みる discrimination が良い。
• アウトカムがまだ起きていない ( 予後予測
など ) 場合は、リスクや確率で推測しなけ
ればならないので Calibration が重視され
る
• Cook et al. Circulation 2007
38
39. ロジスティック分析の流れ
• モデル作成 ( 変数選択→ main effect model→
交互作用項検討 )
• ↓
• モデル評価 (determination?calibration?)
• ↓
• Validation( 内的妥当性→外的妥当性 )
• ↓
• 完成
39
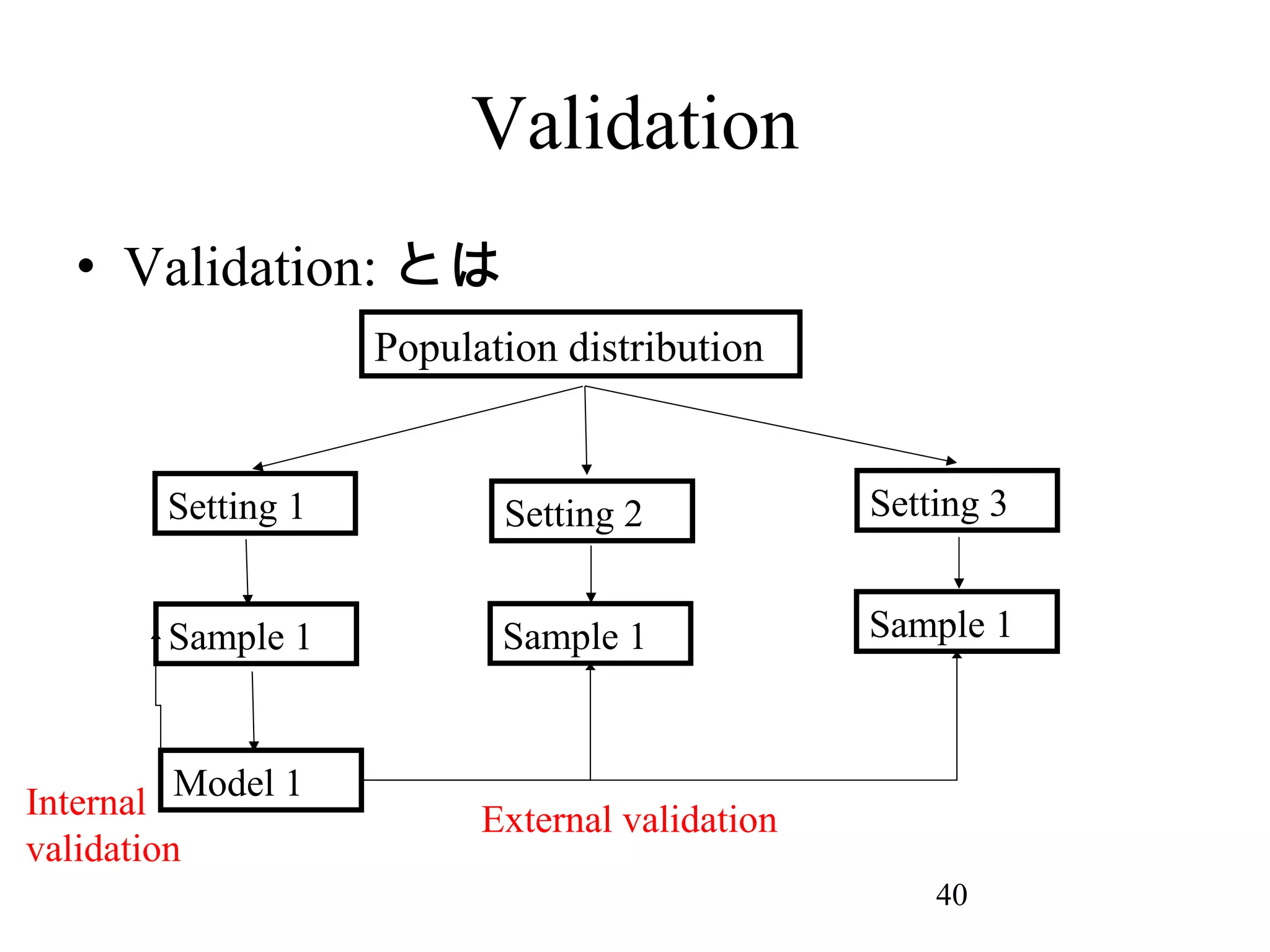
40. 41. 42. 43. 外的妥当性 = 一般化可能性
• 外部データを用いて評価する。
• 外部データとは時間的、空間的に離れて
いる、または独立した他者による検討さ
れるものである。
• 外的妥当性のチェックでは、モデルパフ
ォーマンスが低下することが多い。その
場合、 re-calibration などといった、モデル
に少し手を加えるリペア法もいくつか存
在する。
43
44. 予測モデル V.S. 説明モデル
• モデルアセスメントの観点
• 予測モデル→一般化できるかが問題なので
、 validation が大事
• 説明モデル→理論を上手く説明できている
かが大事なので、 goodness-of-fit や残差診
断などが大事になる
44
45. 参考文献
• Hosmer, Lemeshow “Applied Logistic Regression 3rd
ed.” Wiley 2013
• Steyerberg “Clinical Prediction Models” Springer 2009
• Harrell “Regression Modeling Strategies” Springer
2001
• Kleinbaum “Logistic regression 3rd ed” Springer 2010
• Jaccard “Interaction effects in logistic regression”
SAGE 2001
• Shmueli “To Explain or to Predict?” Statical Science
2010
45
Editor's Notes #5 説明モデル→XとYの理論的な因果関係に立脚して構築するモデル
#26 説明モデル→理論が先にあって、その理論のもとspecificationされるべき
予測モデル→データに基づいて一番予測できるモデルを作るので、アルゴリズム法もO.K.


































































![[読会]Logistic regression models for aggregated data](https://cdn.slidesharecdn.com/ss_thumbnails/logisticregressionmodelsforaggregateddata-211229094148-thumbnail.jpg?width=640&height=640&fit=bounds)


















