Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
ShoKumada
187 views
Time series analysis with python chapter2-1
データラーニングギルドの時系列輪読会の第2回前半の資料です
Data & Analytics
◦
Read more
0
Save
Share
Embed
Embed presentation
1
/ 26
2
/ 26
3
/ 26
4
/ 26
5
/ 26
6
/ 26
7
/ 26
8
/ 26
9
/ 26
10
/ 26
11
/ 26
12
/ 26
13
/ 26
14
/ 26
15
/ 26
16
/ 26
17
/ 26
18
/ 26
19
/ 26
20
/ 26
21
/ 26
22
/ 26
23
/ 26
24
/ 26
25
/ 26
26
/ 26
More Related Content
PPTX
Time series analysis with python 1 3
by
ShoKumada
PDF
第5章混合分布モデルによる逐次更新型異常検知
by
Tetsuma Tada
PDF
グラフィカル Lasso を用いた異常検知
by
Yuya Takashina
PDF
星野「調査観察データの統計科学」第1&2章
by
Shuyo Nakatani
PDF
星野「調査観察データの統計科学」第3章
by
Shuyo Nakatani
PDF
SMO徹底入門 - SVMをちゃんと実装する
by
sleepy_yoshi
PDF
Rによるデータサイエンス:12章「時系列」
by
Nagi Teramo
PDF
Rで計量時系列分析~CRANパッケージ総ざらい~
by
Takashi J OZAKI
Time series analysis with python 1 3
by
ShoKumada
第5章混合分布モデルによる逐次更新型異常検知
by
Tetsuma Tada
グラフィカル Lasso を用いた異常検知
by
Yuya Takashina
星野「調査観察データの統計科学」第1&2章
by
Shuyo Nakatani
星野「調査観察データの統計科学」第3章
by
Shuyo Nakatani
SMO徹底入門 - SVMをちゃんと実装する
by
sleepy_yoshi
Rによるデータサイエンス:12章「時系列」
by
Nagi Teramo
Rで計量時系列分析~CRANパッケージ総ざらい~
by
Takashi J OZAKI
Similar to Time series analysis with python chapter2-1
PPTX
社会心理学者のための時系列分析入門_小森
by
Masashi Komori
PDF
時系列解析の使い方 - TokyoWebMining #17
by
horihorio
PDF
TokyoWebmining統計学部 第1回
by
Issei Kurahashi
PDF
Data assim r
by
Xiangze
PDF
20101002 cd sigfin_spx_ss
by
Takanobu Mizuta
PDF
Rで学ぶ回帰分析と単位根検定
by
Nagi Teramo
PDF
Rubyによるデータ解析
by
Shugo Maeda
PDF
Oshasta em
by
Naotaka Yamada
PDF
PRML 第4章
by
Akira Miyazawa
PDF
Dynamic panel in tokyo r
by
Shota Yasui
PDF
13.2 隠れマルコフモデル
by
show you
PDF
ma99992011id513
by
matsushimalab
PPTX
アンケートデータ集計・分析のためのExcel
by
小山 友介
PDF
第8章 ガウス過程回帰による異常検知
by
Chika Inoshita
PPTX
【読書会資料】『StanとRでベイズ統計モデリング』Chapter12:時間や空間を扱うモデル
by
Masashi Komori
PDF
2013.12.26 prml勉強会 線形回帰モデル3.2~3.4
by
Takeshi Sakaki
PPTX
Prml 1.3~1.6 ver3
by
Toshihiko Iio
PDF
Gunosy2015-06-03
by
Yuta Kashino
PDF
カステラ本勉強会 第三回
by
ke beck
PDF
Unified Expectation Maximization
by
Koji Matsuda
社会心理学者のための時系列分析入門_小森
by
Masashi Komori
時系列解析の使い方 - TokyoWebMining #17
by
horihorio
TokyoWebmining統計学部 第1回
by
Issei Kurahashi
Data assim r
by
Xiangze
20101002 cd sigfin_spx_ss
by
Takanobu Mizuta
Rで学ぶ回帰分析と単位根検定
by
Nagi Teramo
Rubyによるデータ解析
by
Shugo Maeda
Oshasta em
by
Naotaka Yamada
PRML 第4章
by
Akira Miyazawa
Dynamic panel in tokyo r
by
Shota Yasui
13.2 隠れマルコフモデル
by
show you
ma99992011id513
by
matsushimalab
アンケートデータ集計・分析のためのExcel
by
小山 友介
第8章 ガウス過程回帰による異常検知
by
Chika Inoshita
【読書会資料】『StanとRでベイズ統計モデリング』Chapter12:時間や空間を扱うモデル
by
Masashi Komori
2013.12.26 prml勉強会 線形回帰モデル3.2~3.4
by
Takeshi Sakaki
Prml 1.3~1.6 ver3
by
Toshihiko Iio
Gunosy2015-06-03
by
Yuta Kashino
カステラ本勉強会 第三回
by
ke beck
Unified Expectation Maximization
by
Koji Matsuda
Time series analysis with python chapter2-1
1.
時系列解析 自己回帰モデル、状態空間モデル、異常検知 共立出版 島田直希 著 2章まとめ前半 DLG
時系列分析輪読会 sho.kumada 1
2.
2 目次概要 1. なぜ時系列解析を行うか、どの様に行うか 2. HOWを実現するための道具 3.
弱定常性のおさらい 4. MA過程 5. AR過程 AR過程の定常条件 6. ARMA過程 7. どうやって最適なモデルを求めるか 8. モデル選択の目安 9. 情報量基準 10. モデルの診断 11. 単位根過程 12. 単位根検定
3.
なぜ時系列解析を行うか、どの様に行うか 3 WHY ・ 過去のデータを統計学的に理解したい ・ 過去のデータから未来を予測したい HOW 過去のデータに最も合致する統計モデルを特定する 時系列分析では、1時点に1個のデータしか取得できないため、 頻度主義的な確率分布を求めることができない。 (同じ時点で何度もサイコロを振れない) ある確率分布に従う統計モデルを仮定して、現実世界に合うように パラメータを決めていきます。
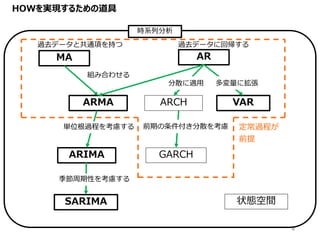
4.
HOWを実現するための道具 4 ARMA ARIMA ARMA VARARCH 状態空間 GARCH 時系列分析 SARIMA 過去データと共通項を持つ 過去データに回帰する 組み合わせる 単位根過程を考慮する 多変量に拡張 季節周期性を考慮する 分散に適用 前期の条件付き分散を考慮
定常過程が 前提
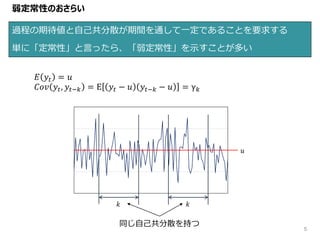
5.
過程の期待値と自己共分散が期間を通して一定であることを要求する 単に「定常性」と言ったら、「弱定常性」を示すことが多い 5 弱定常性のおさらい 𝐸 𝑦𝑡 =
𝑢 𝐶𝑜𝑣 𝑦𝑡, 𝑦𝑡−𝑘 = E 𝑦𝑡 − 𝑢 𝑦𝑡−𝑘 − 𝑢 = γ 𝑘 𝑢 𝑘 𝑘 同じ自己共分散を持つ
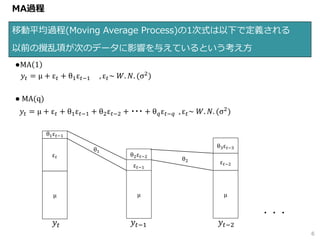
6.
●MA 1 𝑦𝑡 =
μ + ε 𝑡 + θ1ε 𝑡−1 , ε 𝑡~ 𝑊. 𝑁. (σ2) ● MA(q) 𝑦𝑡 = μ + ε 𝑡 + θ1ε 𝑡−1 + θ2ε 𝑡−2 + ・・・ + θ 𝑞ε 𝑡−𝑞 , ε 𝑡~ 𝑊. 𝑁. (σ2) MA過程 移動平均過程(Moving Average Process)の1次式は以下で定義される 以前の攪乱項が次のデータに影響を与えているという考え方 6 𝑦𝑡 𝑦𝑡−1 𝑦𝑡−2 ・・・ μ ε 𝑡 θ1ε 𝑡−1 μ ε 𝑡−1 θ2ε 𝑡−2 μ ε 𝑡−2 θ3ε 𝑡−3 θ2 θ1
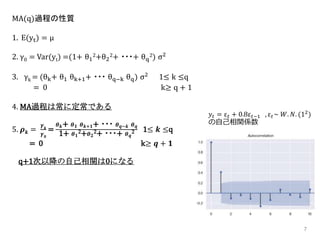
7.
7 MA(q)過程の性質 1. E(yt) =
μ 2. γ0 = Var(yt) =(1+ θ1 2+θ2 2+ ・・・+ θq 2) σ2 3. γk = (θk+ θ1 θk+1+ ・・・ θq−k θq) σ2 1≤ k ≤q = 0 k≥ q + 1 4. MA過程は常に定常である 5. 𝝆 𝒌 = 𝜸 𝒌 𝜸 𝟎 = 𝜽 𝒌+ 𝜽 𝟏 𝜽 𝒌+𝟏+ ・・・ 𝜽 𝒒−𝒌 𝜽 𝒒 1+ 𝜽 𝟏 2+ 𝜽 𝟐 2+ ・・・+ 𝜽 𝒒 2 1≤ 𝒌 ≤q = 0 k≥ 𝒒 + 𝟏 𝑦𝑡 = ε 𝑡 + 0.8ε 𝑡−1 , ε 𝑡~ 𝑊. 𝑁. (12 ) の自己相関係数 q+1次以降の自己相関は0になる
8.
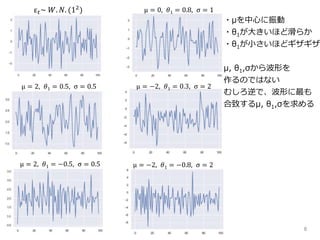
8 ε 𝑡~ 𝑊.
𝑁. (12 ) μ = 0, 𝜃1 = 0.8, σ = 1 μ = 2, 𝜃1 = 0.5, σ = 0.5 μ = −2, 𝜃1 = 0.3, σ = 2 μ = 2, 𝜃1 = −0.5, σ = 0.5 μ = −2, 𝜃1 = −0.8, σ = 2 ・μを中心に振動 ・θ1が大きいほど滑らか ・θ1が小さいほどギザギザ μ, θ1,σから波形を 作るのではない むしろ逆で、波形に最も 合致するμ, θ1,σを求める
9.
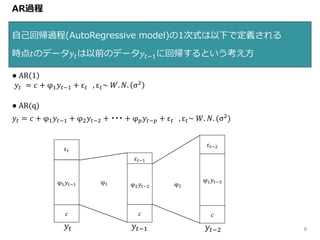
AR過程 自己回帰過程(AutoRegressive model)の1次式は以下で定義される 時点𝑡のデータ𝑦𝑡は以前のデータ𝑦𝑡−1に回帰するという考え方 9 ● AR
1 𝑦𝑡 = 𝑐 + φ1 𝑦𝑡−1 + ε 𝑡 , ε 𝑡~ 𝑊. 𝑁. σ2 ● AR(q) 𝑦𝑡 = 𝑐 + φ1 𝑦𝑡−1 + φ2 𝑦𝑡−2 + ・・・ + φ 𝑝 𝑦𝑡−𝑝 + ε 𝑡 , ε 𝑡~ 𝑊. 𝑁. (σ2) 𝑦𝑡 𝑐 φ1 𝑦𝑡−1 ε 𝑡 φ1 𝑦𝑡−1 𝑐 ε 𝑡−1 φ2 𝑦𝑡−2 𝑦𝑡−2 𝑐 ε 𝑡−2 φ1 𝑦𝑡−3 φ2
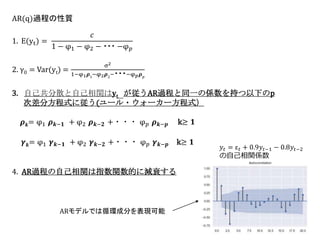
10.
10 AR(q)過程の性質 1. E(yt) = 𝑐 1
− φ1 − φ2 − ・・・ −φ 𝑝 2. γ0 = Var(yt) = σ2 1−φ1 𝝆1 −φ2 𝝆2 −・・・−φ 𝑝 𝝆 𝑝 3. 自己共分散と自己相関は𝐲t が従うAR過程と同一の係数を持つ以下のp 次差分方程式に従う(ユール・ウォーカー方程式) 𝝆 𝒌= φ1 𝝆 𝒌−𝟏 + φ2 𝝆 𝒌−𝟐 +・・・ φ 𝑝 𝝆 𝒌−𝒑 k≥ 𝟏 𝜸 𝒌= φ1 𝜸 𝒌−𝟏 + φ2 𝜸 𝒌−𝟐 +・・・ φ 𝑝 𝜸 𝒌−𝒑 k≥ 𝟏 4. AR過程の自己相関は指数関数的に減衰する 𝑦𝑡 = ε 𝑡 + 0.9𝑦𝑡−1 − 0.8𝑦𝑡−2 の自己相関係数 ARモデルでは循環成分を表現可能
11.
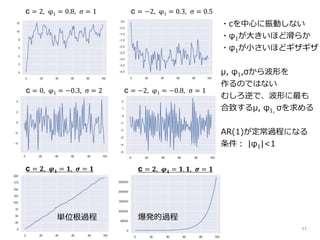
11 c = 2,
φ1 = 0.8, σ = 1 c = −2, φ1 = 0.3, σ = 0.5 c = 0, φ1 = −0.3, σ = 2 c = −2, φ1 = −0.8, σ = 1 ・cを中心に振動しない ・φ1が大きいほど滑らか ・φ1が小さいほどギザギザ μ, φ1,σから波形を 作るのではない むしろ逆で、波形に最も 合致するμ, φ1, σを求める AR(1)が定常過程になる 条件: |φ1|<1 c = 𝟐, 𝝋 𝟏 = 𝟏, 𝝈 = 𝟏 c = 𝟐, 𝝋 𝟏 = 𝟏. 𝟏, 𝝈 = 𝟏 単位根過程 爆発的過程
12.
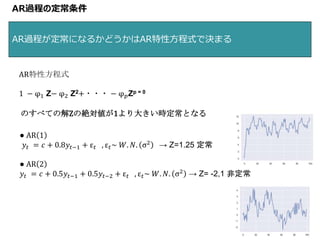
AR過程の定常条件 AR過程が定常になるかどうかはAR特性方程式で決まる 12 AR特性方程式 1 − φ1
Z− φ2 Z2+・・・ − φ 𝑝Zp = 0 のすべての解Zの絶対値が1より大きい時定常となる ● AR 1 𝑦𝑡 = 𝑐 + 0.8𝑦𝑡−1 + ε 𝑡 , ε 𝑡~ 𝑊. 𝑁. σ2 → Z=1.25 定常 ● AR 2 𝑦𝑡 = 𝑐 + 0.5𝑦𝑡−1 + 0.5𝑦𝑡−2 + ε 𝑡 , ε 𝑡~ 𝑊. 𝑁. σ2 → Z= -2,1 非定常
13.
両者を足し合した自己回帰移動平均過程(AutoRegressive Moving Average Process)は以下で定義される 13 ARMA過程 ●
AR𝑀𝐴 𝑝, 𝑞 𝑦𝑡 = 𝑐 + φ1 𝑦𝑡−1 + φ2 𝑦𝑡−2 + ・・・ + φ 𝑝 𝑦𝑡−𝑝 + ε 𝑡 + θ1ε 𝑡−1, +θ2ε 𝑡−2 + ・・・ + θ 𝑞ε 𝑡−𝑞 , ε 𝑡~ 𝑊. 𝑁. (σ2 ) AR MA
14.
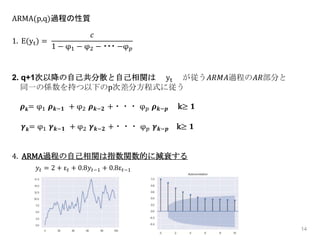
14 ARMA(p,q)過程の性質 1. E(yt) = 𝑐 1
− φ1 − φ2 − ・・・ −φ 𝑝 2. q+1次以降の自己共分散と自己相関は yt が従う𝐴𝑅𝑀𝐴過程の𝐴𝑅部分と 同一の係数を持つ以下のp次差分方程式に従う 𝝆 𝒌= φ1 𝝆 𝒌−𝟏 + φ2 𝝆 𝒌−𝟐 +・・・ φ 𝑝 𝝆 𝒌−𝒑 k≥ 𝟏 𝜸 𝒌= φ1 𝜸 𝒌−𝟏 + φ2 𝜸 𝒌−𝟐 +・・・ φ 𝑝 𝜸 𝒌−𝒑 k≥ 𝟏 4. ARMA過程の自己相関は指数関数的に減衰する 𝑦𝑡 = 2 + ε 𝑡 + 0.8𝑦𝑡−1 + 0.8ε 𝑡−1
15.
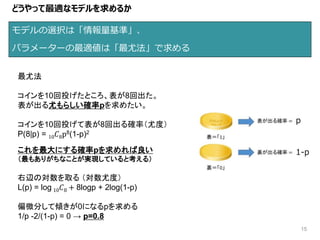
モデルの選択は「情報量基準」、 パラメーターの最適値は「最尤法」で求める 15 どうやって最適なモデルを求めるか 最尤法 コインを10回投げたところ、表が8回出た。 表が出る尤もらしい確率pを求めたい。 コインを10回投げて表が8回出る確率(尤度) P(8|p) = 10
𝐶8p8(1-p)2 これを最大にする確率pを求めれば良い (最もありがちなことが実現していると考える) 右辺の対数を取る (対数尤度) L(p) = log 10 𝐶8 + 8logp + 2log(1-p) 偏微分して傾きが0になるpを求める 1/p -2/(1-p) = 0 → p=0.8 p 1-p
16.
16 𝐴R(1)に対して最適なパラメータを求める 𝑦𝑡 = 𝑐
+ φ1 𝑦𝑡−1 + ε 𝑡 , ε 𝑡~ 𝑊. 𝑁. σ2 → 求めたいパラメータθ(c, φ1 , σ2) 尤度 P(𝑦1| 𝑦0;θ)×p(𝑦2| 𝑦1;θ)×・・・×p(𝑦 𝑇| 𝑦 𝑇−1;θ) 対数尤度 Logp(𝑦1| 𝑦0;θ)+logp(𝑦2| 𝑦1;θ)+・・・+logp(𝑦 𝑇| 𝑦 𝑇−1;θ) これを最大にするθを求める 尤度の計算 P(𝑦𝑡| 𝑦𝑡−1;θ)=N(𝑐 + φ1 𝑦𝑡−1, σ2 ) = 1 2πσ2 exp[ − 𝑦 𝑡−𝑐−φ1 𝑦 𝑡−1 2 2σ2 ] 対数尤度の計算 -T/2log(2π)-T/2log(σ2 )- 𝑡=1 𝑇 [ 𝑦 𝑡−𝑐−φ1 𝑦 𝑡−1 2 2σ2 ] 結局、 𝑦 𝑡−𝑐−φ1 𝑦 𝑡−1 2 2σ2 を最小にするθ(c, φ1 , σ2 )を求めてやれば良い! → 偏微分して0とおいて連立方程式を解く 𝑦0は決め打ちでやっちゃう ことがほとんど
17.
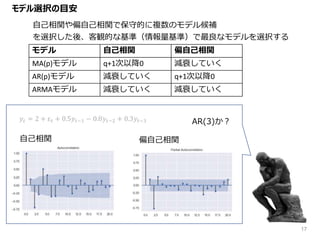
モデル選択の目安 17 モデル 自己相関 偏自己相関 MA(p)モデル
q+1次以降0 減衰していく AR(p)モデル 減衰していく q+1次以降0 ARMAモデル 減衰していく 減衰していく 自己相関 偏自己相関 𝑦𝑡 = 2 + ε 𝑡 + 0.5𝑦𝑡−1 − 0.8𝑦𝑡−2 + 0.3𝑦𝑡−3 自己相関や偏自己相関で保守的に複数のモデル候補 を選択した後、客観的な基準(情報量基準)で最良なモデルを選択する AR(3)か?
18.
情報量基準が最小になる次数を選択する 18 情報量基準 情報量基準の一般式 𝐼𝐶 = −2𝐿(θ)+p(T)k 𝐿
θ : 最大対数尤度 T:モデルの推定に用いた標本数 p(T):Tの何らかの関数 K:推定したパラメータの数 AIC (赤池情報量基準) BIC (ベイズ情報量基準) 式 −2𝐿(θ)+2k −2𝐿(θ)+log(T)k 性質 lim 𝑇→∞ 𝑃( 𝑝 < 𝑝) = 0 lim 𝑇→∞ 𝑃( 𝑝 > 𝑝) > 0 一致性なし lim 𝑇→∞ 𝑃( 𝑝 = 𝑝) = 1 一致性あり 当てはまりの良さ 罰則項 𝑝:情報量基準から選ばれた次数、𝑝:真の次数
19.
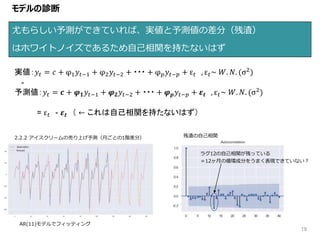
19 尤もらしい予測ができていれば、実値と予測値の差分(残渣) はホワイトノイズであるため自己相関を持たないはず モデルの診断 実値:𝑦𝑡 = 𝑐
+ φ1 𝑦𝑡−1 + φ2 𝑦𝑡−2 + ・・・ + φ 𝑝 𝑦𝑡−𝑝 + ε 𝑡 , ε 𝑡~ 𝑊. 𝑁. (σ2) - 予測値:𝑦𝑡 = 𝒄 + 𝝋 𝟏 𝑦𝑡−1 + 𝝋 𝟐 𝑦𝑡−2 + ・・・ + 𝝋 𝒑 𝑦𝑡−𝑝 + 𝜺 𝒕 , ε 𝑡~ 𝑊. 𝑁. (σ2 ) = ε 𝑡 - 𝜺 𝒕 ( ← これは自己相関を持たないはず) 2.2.2 アイスクリームの売り上げ予測(月ごとの1階差分) 残渣の自己相関 AR(11)モデルでフィッティング ラグ12の自己相関が残っている =12ヶ月の循環成分をうまく表現できていない?
20.
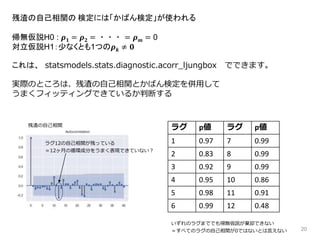
20 残渣の自己相関の 検定には「かばん検定」が使われる 帰無仮説H0 :
𝝆 𝟏 = 𝝆 𝟐 = ・・・ = 𝝆 𝒎 = 0 対立仮説H1:少なくとも1つの𝝆 𝒌 ≠ 𝟎 これは、 statsmodels.stats.diagnostic.acorr_ljungbox でできます。 実際のところは、残渣の自己相関とかばん検定を併用して うまくフィッティングできているか判断する 残渣の自己相関 ラグ12の自己相関が残っている =12ヶ月の循環成分をうまく表現できていない? ラグ p値 ラグ p値 1 0.97 7 0.99 2 0.83 8 0.99 3 0.92 9 0.99 4 0.95 10 0.86 5 0.98 11 0.91 6 0.99 12 0.48 いずれのラグまででも帰無仮説が棄却できない =すべてのラグの自己相関が0ではないとは言えない
21.
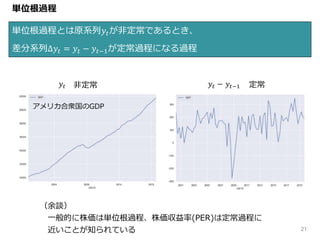
21 単位根過程とは原系列𝑦𝑡が非定常であるとき、 差分系列Δ𝑦𝑡 = 𝑦𝑡
− 𝑦𝑡−1が定常過程になる過程 単位根過程 𝑦𝑡 𝑦𝑡 − 𝑦𝑡−1 定常非定常 アメリカ合衆国のGDP (余談) 一般的に株価は単位根過程、株価収益率(PER)は定常過程に 近いことが知られている
22.
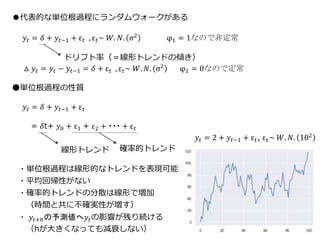
22 ●代表的な単位根過程にランダムウォークがある 𝑦𝑡 = 𝛿
+ 𝑦𝑡−1 + ε 𝑡 , ε 𝑡~ 𝑊. 𝑁. σ2 φ1 = 1なので非定常 △ 𝑦𝑡 = 𝑦𝑡 − 𝑦𝑡−1 = 𝛿 + ε 𝑡 , ε 𝑡~ 𝑊. 𝑁. σ2 φ1 = 0なので定常 ●単位根過程の性質 𝑦𝑡 = 𝛿 + 𝑦𝑡−1 + ε 𝑡 = 𝛿t+ 𝑦0 + ε1 + ε2 + ・・・ + ε 𝑡 ドリフト率(=線形トレンドの傾き) 確率的トレンド線形トレンド ・単位根過程は線形的なトレンドを表現可能 ・平均回帰性がない ・確率的トレンドの分散は線形で増加 (時間と共に不確実性が増す) ・ 𝑦𝑡+ℎの予測値へ𝑦𝑡の影響が残り続ける (hが大きくなっても減衰しない) 𝑦𝑡 = 2 + 𝑦𝑡−1 + ε 𝑡, ε 𝑡~ 𝑊. 𝑁. 102
23.
過程が単位根過程か定常過程かによって、 施策のうち方が変わってくるため、適切に判断することが重要 23 単位根検定 代表的な単位根検定には以下の3つがある 名称 帰無仮説(H0) 対立仮説(H1) Dickey-Fuller(DF)検定
単位根AR(1)過程である 定常AR(1)過程である 拡張DF(ADF)検定 単位根AR(p)過程である 定常AR(p)過程である Phillips-Perron(PP)検定* 単位根AR(p)過程である 定常AR(p)過程である *ホワイトノイズの分散不均一性まで考慮した検定手法
24.
24 帰無仮説と対立仮説のモデルの置き方によって棄却点が異なる。 モデルを適切に仮定することが大切。 よく使われるモデルは次の3つ [場合1]H0: 𝑦𝑡 =
𝑦𝑡−1 + 𝑢 𝑡 , H1: 𝑦𝑡 = 𝜌𝑦𝑡−1 + 𝑢 𝑡 , | 𝜌|<1 [場合2]H0: 𝑦𝑡 = 𝑦𝑡−1 + 𝑢 𝑡 , H1:𝑦𝑡 = α + 𝜌𝑦𝑡−1 + 𝑢 𝑡 , | 𝜌|<1 [場合3]H0: 𝑦𝑡 = α + 𝑦𝑡−1 + 𝑢 𝑡 , H1:α + 𝜌𝑦𝑡−1 + 𝛿𝑡 + 𝑢 𝑡, | 𝜌|<1 [場合1]データがトレンドを持たず、過程の期待値が0の場合 [場合2]データがトレンドを持たず、過程の期待値が0でない場合 [場合3]データがトレンドを持を持つ場合 アメリカ合衆国のGDP 場合3に該当 場合1に該当
25.
25 StatsmodelsでのADF検定 実施例(書籍2.7.3) 場合3に該当 場合2に該当 場合1に該当 場合1 、場合2、場合3と進むにつれて一般的になっており、 判断に迷う際は場合3を用いるのが安全。 場合1
、場合2が真で場合3を仮定してしまった場合、 間違いにはならないが、検定の検出力が落ちる。 つまり、単位根検定の帰無仮説を棄却する確率が下がってしまう。
26.
26 TJOさんのブログに以下の記述がありました。 ところで、単位根AR過程のモデル推定に当たり 「単位根を持つことを無視したらどうなるか?」ということが 沖本本pp.120-122に書かれています。 結論から言うと「そんなに問題はない」が、 「非標準的な漸近理論に基づくポイントがあるためF検定が使えず」、 「特にVARモデルに拡張した場合はGranger因果性検定が使えない」。 Granger因果性については、第2章後半で取りあげます 渋谷駅前で働くデータサイエンティストのブログ 出典:https://tjo.hatenablog.com/entry/2013/08/16/095536#fn-0435acc5




![16
𝐴R(1)に対して最適なパラメータを求める
𝑦𝑡 = 𝑐 + φ1 𝑦𝑡−1 + ε 𝑡 , ε 𝑡~ 𝑊. 𝑁. σ2 → 求めたいパラメータθ(c, φ1 , σ2)
尤度
P(𝑦1| 𝑦0;θ)×p(𝑦2| 𝑦1;θ)×・・・×p(𝑦 𝑇| 𝑦 𝑇−1;θ)
対数尤度
Logp(𝑦1| 𝑦0;θ)+logp(𝑦2| 𝑦1;θ)+・・・+logp(𝑦 𝑇| 𝑦 𝑇−1;θ) これを最大にするθを求める
尤度の計算
P(𝑦𝑡| 𝑦𝑡−1;θ)=N(𝑐 + φ1 𝑦𝑡−1, σ2
)
=
1
2πσ2
exp[
− 𝑦 𝑡−𝑐−φ1
𝑦 𝑡−1
2
2σ2 ]
対数尤度の計算
-T/2log(2π)-T/2log(σ2
)- 𝑡=1
𝑇
[
𝑦 𝑡−𝑐−φ1
𝑦 𝑡−1
2
2σ2 ]
結局、
𝑦 𝑡−𝑐−φ1
𝑦 𝑡−1
2
2σ2 を最小にするθ(c, φ1 , σ2
)を求めてやれば良い!
→ 偏微分して0とおいて連立方程式を解く
𝑦0は決め打ちでやっちゃう
ことがほとんど](https://image.slidesharecdn.com/timeseriesanalysiswithpython-1-200402091032/85/Time-series-analysis-with-python-chapter2-1-16-320.jpg)


![24
帰無仮説と対立仮説のモデルの置き方によって棄却点が異なる。
モデルを適切に仮定することが大切。
よく使われるモデルは次の3つ
[場合1]H0: 𝑦𝑡 = 𝑦𝑡−1 + 𝑢 𝑡 , H1: 𝑦𝑡 = 𝜌𝑦𝑡−1 + 𝑢 𝑡 , | 𝜌|<1
[場合2]H0: 𝑦𝑡 = 𝑦𝑡−1 + 𝑢 𝑡 , H1:𝑦𝑡 = α + 𝜌𝑦𝑡−1 + 𝑢 𝑡 , | 𝜌|<1
[場合3]H0: 𝑦𝑡 = α + 𝑦𝑡−1 + 𝑢 𝑡 , H1:α + 𝜌𝑦𝑡−1 + 𝛿𝑡 + 𝑢 𝑡, | 𝜌|<1
[場合1]データがトレンドを持たず、過程の期待値が0の場合
[場合2]データがトレンドを持たず、過程の期待値が0でない場合
[場合3]データがトレンドを持を持つ場合
アメリカ合衆国のGDP
場合3に該当 場合1に該当](https://image.slidesharecdn.com/timeseriesanalysiswithpython-1-200402091032/85/Time-series-analysis-with-python-chapter2-1-24-320.jpg)





























