Download to read offline

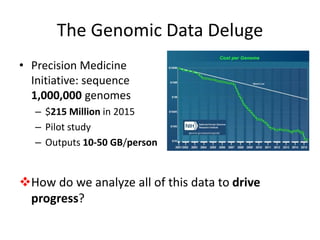

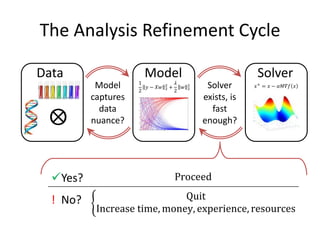
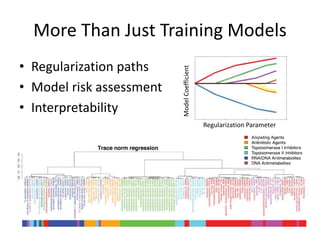
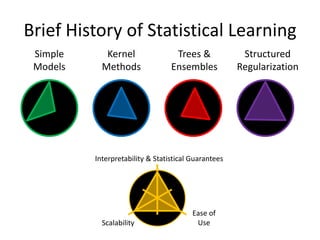

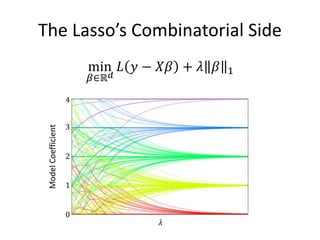

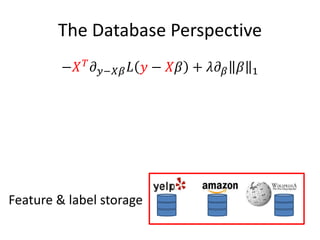
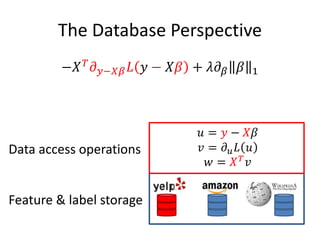
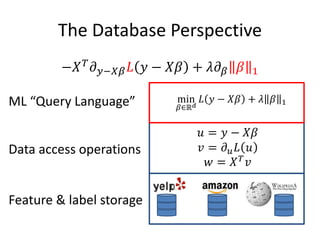

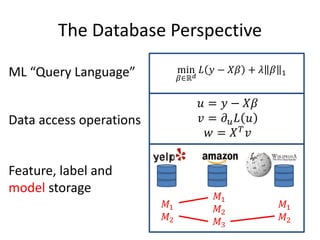
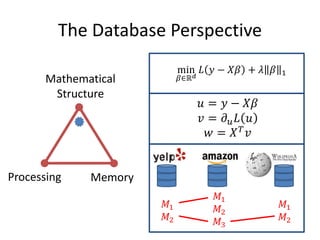
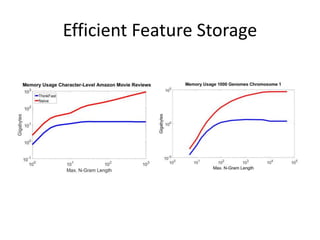


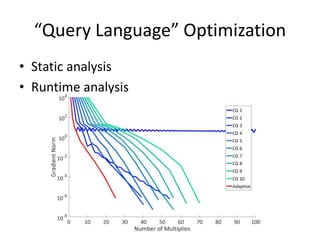



This document discusses scaling machine learning to meet modern demands for analyzing massive datasets. It notes initiatives like the Precision Medicine Initiative that will generate terabytes of genomic data per person, and how statistical learning and structured regularization can help analyze such data. The document presents machine learning as a "query language" that can be optimized like database queries by using the mathematical structure of learning problems and efficient feature storage. It provides examples of applications in bioinformatics that have improved results over state-of-the-art using these techniques.








































































































