Downloaded 373 times























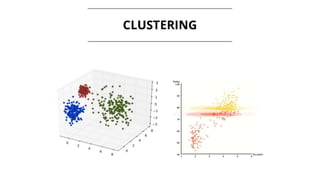



















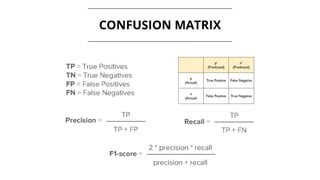





















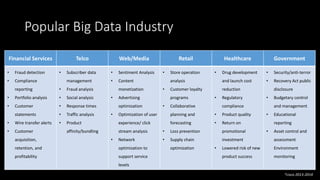
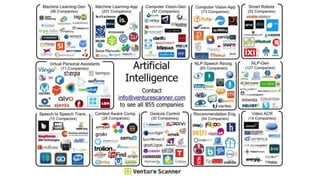















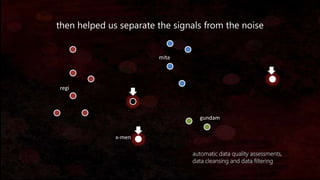













































































The document discusses the evolution of machine learning, highlighting its definitions, challenges, and recent breakthroughs such as DeepMind's AlphaGo and various applications in industries including healthcare and finance. It outlines the major challenges in implementing machine learning, particularly in data preparation and integration, while envisioning intelligent machines that simplify analytics processes. Furthermore, it touches upon scalability issues and emerging technologies aimed at enhancing data analysis and user interaction with intelligent systems.






















































































