Downloaded 11 times



![FRENCH MACHINE READING FOR QUESTION ANSWERING
2018, October 22 │24
4
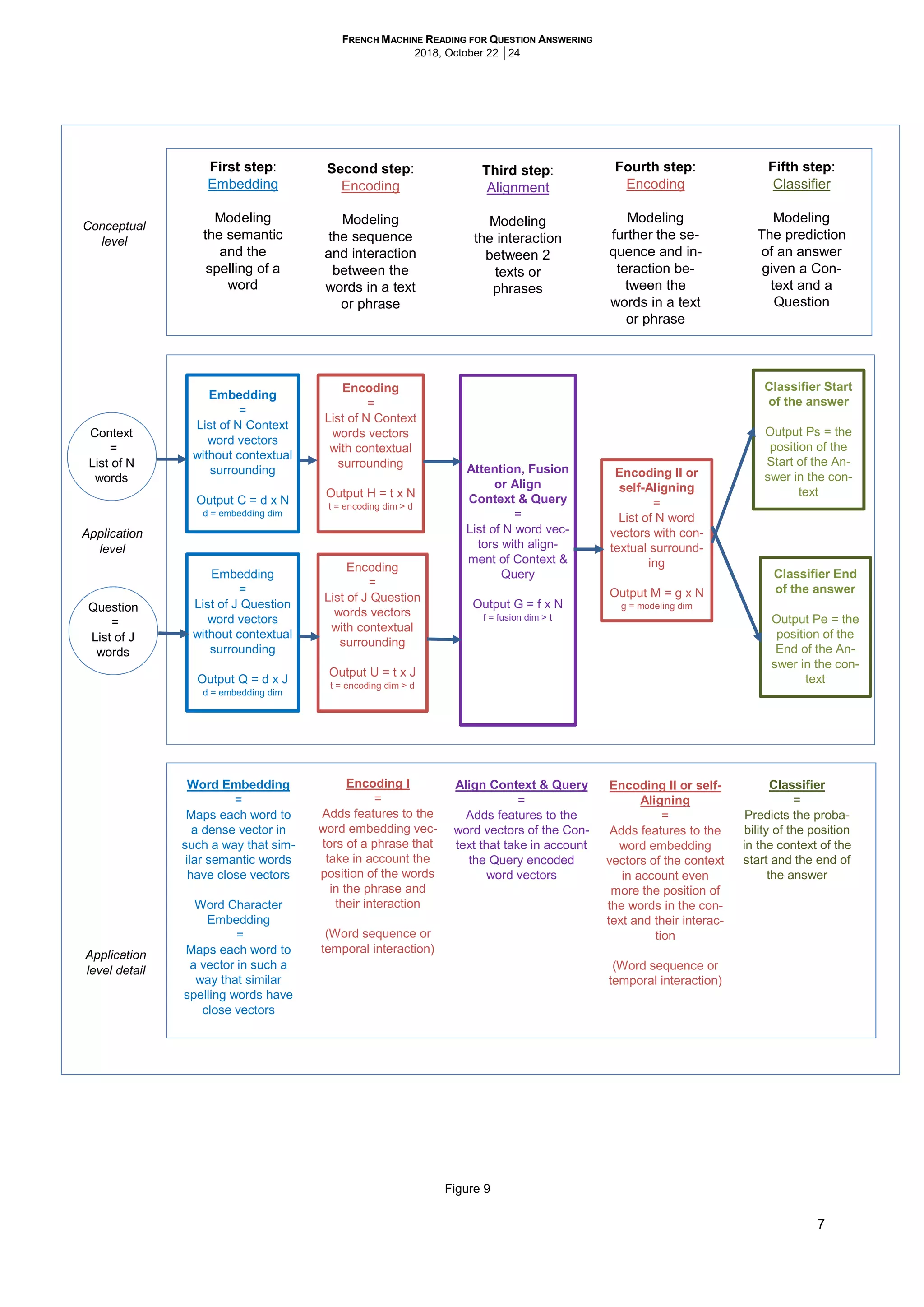
2.1 DEEP LEARNING Q&A IN FRENCH
2.1.1 The objective
All the Q&A neural network model try to extract from a given context paragraph P the right answer to a
given question Q. The given paragraph is an ordered list of n words, P = [ p1, p2,….., pn] and the question
is an ordered list of m words, Q = [ q1, q2,….., qn]. The model should extract the right answer A which
should be a span of the original paragraph, A = [ pi, pi+1,….., pi+j].] with i+j<n.
To be clear the answer should be a span from the paragraph. No deduction can be made. For example
if the paragraph is P = “Paul has a Ford and a Honda” and the question Q = “How many car does Paul
have?” the Q&A model will not be able to answer “2”. But it wil be able to answer the question Q =
”What car does Paul have?”, the answer will be A = “a Ford and a Honda”.
2.1.2 The Neural Network Architectures
For our work, from the hundreds of neural network architectures referenced in the SQuAD leaderboard, https://raj-
purkar.github.io/SQuAD-explorer, we chose to test, train and three most competitive ones of them. We focus only on
“simple model” category and compare against other models with the same category.
Figure 5
Scores collected from the SQuAD leaderboard on Sep 1, 2018
https://rajpurkar.github.io/SQuAD-explorer/
EM F1
Human Performance
Stanford University
QANet (single)
Google Brain & CMU
Reinforced Mnemonic Reader + A2D (single model)
Microsoft Research Asia & NUDT
r-net (ensemble)
Microsoft Research Asia & NUDT
SLQA+
single model
Hybrid AoA Reader (single model)
Joint Laboratory of HIT and iFLYTEK Research
r-net+ (single model)
Microsoft Research Asia
MAMCN+ (single model)
Samsung Research
BiDAF + Self Attention + ELMo (single model)
Allen Institute for Artificial Intelligence
KACTEIL-MRC(GF-Net+) (single model)
Kangwon National University, Natural Language Processing Lab.
MDReader0
single model
KakaoNet (single model)
Kakao NLP Team
Mnemonic Reader (single model)
NUDT and Fudan University
QFASE
NUS
MAMCN (single model)
Samsung Research
M-NET (single)
UFL
AttReader (single)
College of Computer & Information Science, SouthWest University, Chongqing, China
Document Reader (single model)
Facebook AI Research
Ruminating Reader (single model)
New York University
ReasoNet (single model)
MSR Redmond
jNet (single model)
USTC & National Research Council Canada & York University
May 09, 2018 78.401 85.724
…………. ………. ……….
87.288
85.833
78.664 85.78
78.171 85.543
Jun 20, 2018
May 09, 2018
May 09, 2018
Jan 13, 2018
Jan 22, 2018
Jan 03, 2018
Feb 23, 2018
Nov 03, 2017
Mar 29, 2018
Jun 01, 2018
82.304 91.221
82.471 89.306
79.692 86.727
78.58
79.901 86.536
88.1381.538
82.136 88.126
80.436 87.021
80.027
80.146
Apr 13, 2017 71.898 79.989
Mar 24, 2017 70.607 79.821
………………….
Apr 02, 2017 70.639 79.456
Mar 08, 2017 70.555 79.364
May 23, 2018 71.373 79.725
Mar 14, 2017 70.733 79.353
Apr 22, 2018 70.985 79.939
Oct 27, 2017 71.016 79.835
Jul 14, 2017 70.995](https://image.slidesharecdn.com/frenchmachinereadingforquestionanswering-181111194422/75/French-machine-reading-for-question-answering-4-2048.jpg)



![FRENCH MACHINE READING FOR QUESTION ANSWERING
2018, October 22 │24
10
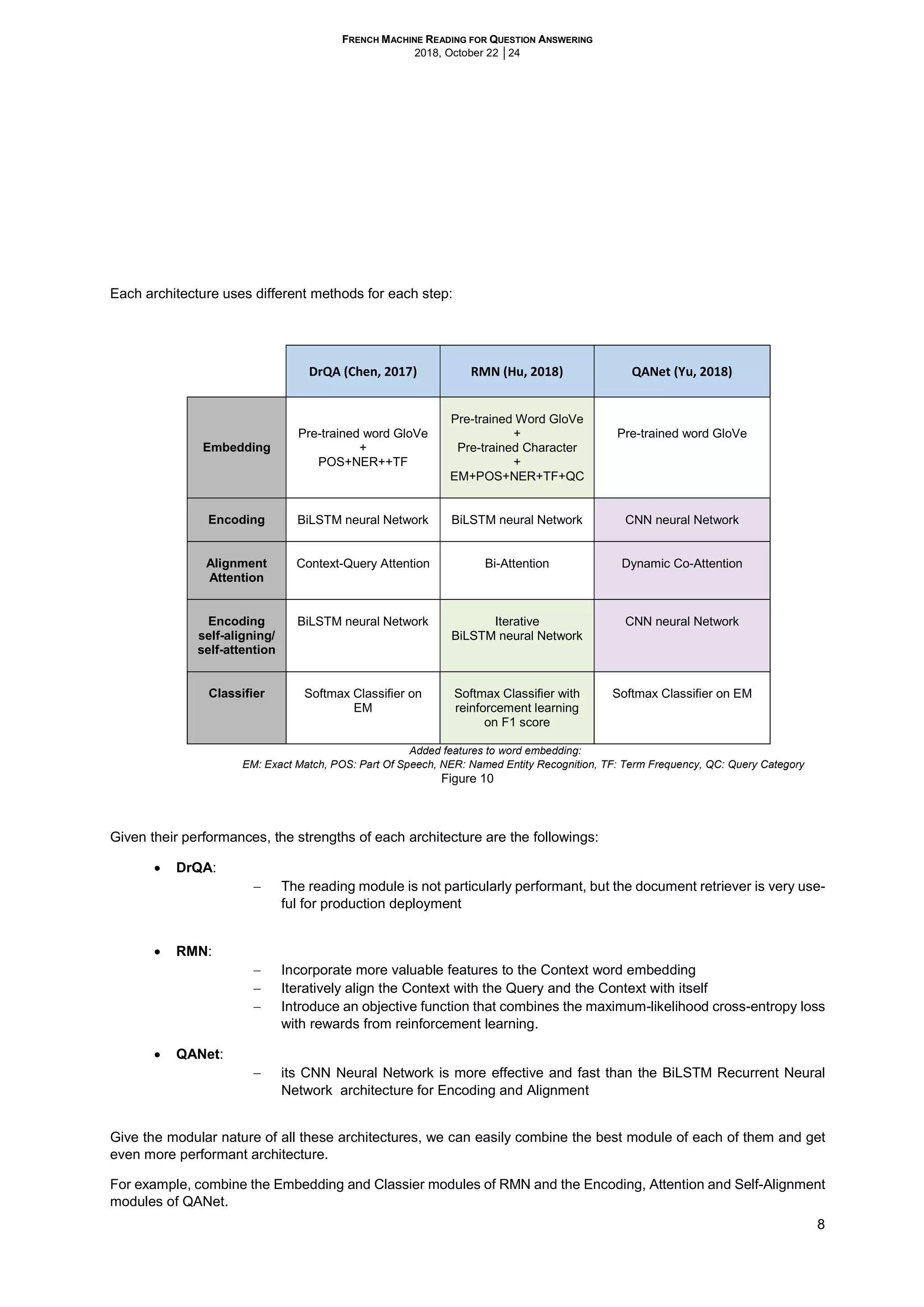
2.1.4 The training Dataset
Almost all the models available are trained on English datasets. For our work we need to train with a French dataset.
Since we did not find any substantial French Q&A Dataset, we had to build one. Instead of starting from scratch and
spend weeks to ask crowd workers to read article, create questions and report answers and their start and end
position in the context, we preferred to translate the SQuAD training and dev datasets v1.1 (Rajpurkar et al., 2016)
from English to French.
SQuAD contains 107.7K query-answer pairs, with 87.5K for training, 10.1K for validation, and another 10.1K for
testing. Only the training and validation data are publicly available. Each training example of SQuAD is a triple of (d;
q; a) in which document d is a multi-sentence paragraph, q is the question and a is the answer to the question.
For Machine Translation, we utilized the publicly available Google Translate API GoogleTrans package provided by
SuHun Han on https://github.com/ssut/py-googletrans.
However, translating (d; q; a) from English to French is not enough. All the models need the answer span and its
position in the context, its start and end. Therefore, we need to find for the French answer the star and the end of the
answer in the French context.
Since the translation of the context and the answer are not always aligned, it is not always possible to find the answer
as translated in the context. In our translation less than 2/3 of the answers were found in the context. For the rest we
had to reconstitute the answer from the English one (EnA) and the French translated one (FrA).
For this reconstituted French answer, we first split the strings (EnA) and (FrA) in a list of words (Lowa) and try to find
the string in the context with a length equal to the maximum of (EnA) and (FrA) length, Lmax, and the maximum of
word close to the words in (Lowa). We used three kind of methods to determine how close two words are.
Exact match = 1
Ratio Levenshtein distance
Jaro Winkler distance
For each string of a length of Lmax in the context, we add up the words distances and take the string with the highest
score. We did that with the strings including stop words and punctuation and strings without them (Non-normalized
and Normalized).
*closet string in the context: string in the context of a length of 40 (Lmax) with the highest distance (EM, Ratio Levenshtein or Jaro Winkle)
Figure 11: French answer reconstitution
English context:
The dismantling of a nuclear reactor can only take place after the appro-
priate license has been granted pursuant to the Council Directive 85 / 3
37 /EEC and the Article 37 of the Grand Euratom Treaty. As part of the
licensing procedure, various documents, reports and expert opinions
have to be written and delivered to the competent authority, e.g. safety
report, technical documents and an environmental impact study (EIS).
French context:
Le démantèlement d'un réacteur nucléaire ne peut avoir lieu qu'après l'oc-
troi de la licence appropriée conformément à la directive 85/3 37 / CEE du
Conseil et à l'article 37 du traité Grand d’Euratom. Dans le cadre de la
procédure d'autorisation, divers documents, rapports et avis d'experts doi-
vent être rédigés et remis à l'autorité compétente, par exemple rapport de
sécurité, documents techniques et étude d’impact sur l’environnement.
English Question:
What article rules nuclear dismantling?
English Answer (EnA):
Article 37 of the Grand Euratom Treaty
French Answer Start, length:
159 , 40
French Question:
Quel article régit le démantèlement nucléaire?
French Answer (FrA):
L’Article 37 du grandiose traité Euratom
English Answer Start, length:
159 , 38
Machine Translation
Answer in
context
List of words in the answers (Lowa)
[‘37', 'article', ‘euratom', 'grand', 'treaty', 'du', 'grandiose', 'of', 'traité']
Closest string
in the context*
French Answer Start:
161
New French Answer
l'article 37 du traité Grand d’Euratom.
No](https://image.slidesharecdn.com/frenchmachinereadingforquestionanswering-181111194422/75/French-machine-reading-for-question-answering-10-2048.jpg)
![FRENCH MACHINE READING FOR QUESTION ANSWERING
2018, October 22 │24
11
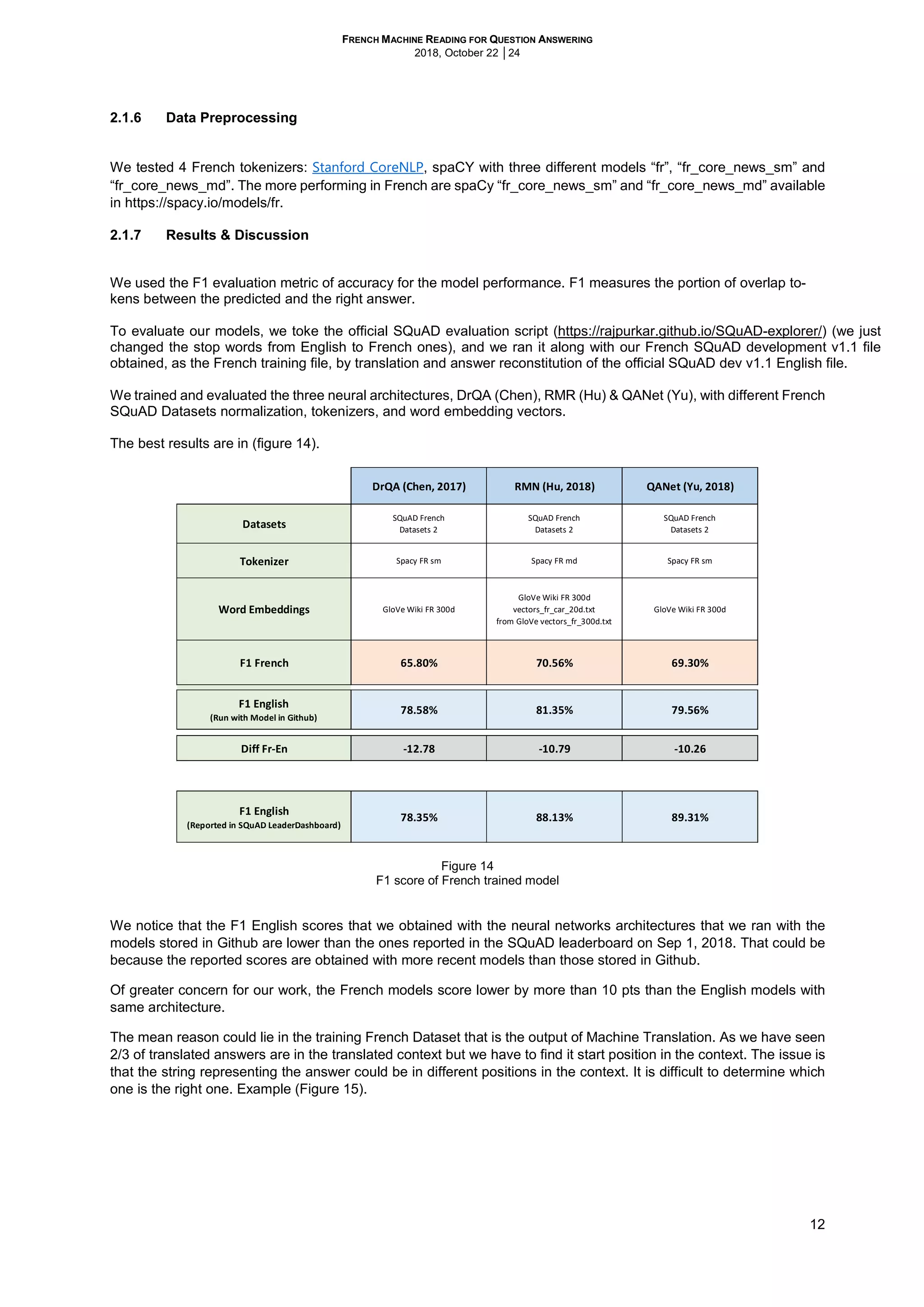
We end with six French SQuAD Datasets. We trained the models with each of them. The one that produced the best
F1 score is the Dataset 2, (Figure 12).
Figure 12
Tested French SQuAD datasets
The SQuAD French Datset 2 has the following statistics (Figure 13)
Figure 13
2.1.5 Word and Character Embedding
In order to manipulate words and characters in the code and the models, we need to represent them in form of
vectors. The first idea is representing them as one-hot vectors. Therefore, the vector dimension will be equal to the
total number of words in a vocabulary.
This representation has at least two drawbacks. The word vectors are very long and sparse. Secondly, it is not pos-
sible to compare the semantic and syntactic similarity of two words. It would be convenient to devise a dense vector
for each word chosen in such a way that similar words has close vectors. That is word embedding.
GloVe [(Pennington et al., 2014)] and word2vec [Tomas Mikolov et al., 2013] are two well-known word embedding
methods that learn embedding vectors based on the idea that the words that often appear in similar contexts are
similar to each other. To do so, these algorithms try to accurately predict the adjacent word(s) given a word or a
context (i.e., a few words appeared in the same context window).
Using well pre-trained word embedding vectors is very important for Q&A model performance.
English pre-trained word embedding vectors are available open source on the net [http://nlp.stan-
ford.edu/data/wordvecs/glove.840B.300d.zip / https://code.google.com/archive/p/word2vec/downloads],
But we didn’t find an open source reliable French pre-trained word embedding vectors.
Therefore, we had to build our own French pre-trained word embedding vectors. To do that, we used as corpus the
French Wikipedia Dump of 2018-07-20 [frwiki-20180720-pages-articles-multistream.xml -https://dumps.wiki-
media.org/frwiki/20180720/ ] and we ran the package given in https://github.com/stanfordnlp/GloVe. We got a file of
300 dimension vector for 1 658 972 French words.
Reinforced Mnemonic Reader (Hu et al. 2017) model requires also a pre-trained character embedding vectors. To
get these vectors for French language, we applied again the GloVe package to our words of the French pre-trained
word-embedding file.
In this model, to add features to the word vectors, the character vectors of all the characters in one word are concat-
enated to the word vector.
Exact Match
Levenshtein
Ratio distance
Jaro winkler
distance
Not Normalized
SQuAD French
Datasets 1
SQuAD French
Datasets 3
SQuAD French
Datasets 5
Normalized
SQuAD French
Datasets 2
SQuAD French
Datasets 4
SQuAD French
Datasets 6
Normalized
Word
Similarity
Tokenizer Set
Total English
Answers
Direct Answers
from Translation
Reconstuted
Answers
Lost Answers
Total French
Answers
34,725 21,858 11,671 1,196 33,529
100.00% 62.95% 33.61% 3.44% 96.56%
87,599 54,237 30,631 2,731 84,943
100.00% 61.92% 34.97% 3.12% 96.97%
dev
Yes Exact
train
SQuAD French Dataset 2
Spacy
fr_core_news_md](https://image.slidesharecdn.com/frenchmachinereadingforquestionanswering-181111194422/75/French-machine-reading-for-question-answering-11-2048.jpg)






The paper discusses the development of a machine reading and comprehension system tailored for French natural language texts, focusing on creating a large training dataset for question answering (Q&A) applications. By translating and adapting the English SQuAD v1.1 dataset, the authors trained various Q&A neural network architectures, achieving an F1 score of around 70%. This work represents a significant step in enabling effective Q&A systems for French texts using deep learning techniques.



































































